
A compressor trips offline during a production run, pressure falls off, operators start calling, and the maintenance team gets pulled into the same familiar question: what failed, and how fast can it be fixed? In most plants, that moment creates pressure to act before anyone has enough evidence. Parts get swapped, alarms get reset, and the machine may come back. The harder question is whether the team solved the problem.
That's where good compressor troubleshooting separates itself from reactive maintenance. A compressor failure isn't just a mechanical event. It's a reliability decision with consequences for downtime, spare parts, labor, energy use, and future risk. A reciprocating unit in gas service, a rotary screw package in a food plant, and a centrifugal machine in chemical processing all fail differently, but the discipline behind troubleshooting is the same. Gather facts first, identify the actual failure mode, and choose a corrective action that makes sense for the asset's remaining life.
Plants that handle this well usually have one thing in common. They treat troubleshooting as part of a broader operations and maintenance strategy, not as a stand-alone emergency task.
Table of Contents
- Beyond the Reset Button A Strategic Approach to Compressor Downtime
- Systematic Diagnosis Before You Touch a Wrench
- Using Data to Pinpoint the Failure Mode
- Decoding Failures in Reciprocating Screw and Centrifugal Units
- From Repair to Reliability Choosing the Right Corrective Action
- Implementing a Proactive Compressor Reliability Program
Beyond the Reset Button A Strategic Approach to Compressor Downtime
A plant rarely loses only a compressor. It loses stable pressure, process confidence, and time to think clearly. In a packaging facility, a rotary screw compressor trip can stop pneumatic actuators across multiple lines. In a refinery, a reciprocating compressor issue can force operators into a controlled slowdown while maintenance tries to determine whether the problem sits in the machine, the driver, or the process.
That's why the reset button is a poor troubleshooting strategy. Resetting a trip without understanding why it occurred only delays the next event, and the next event often arrives under worse conditions. A high discharge temperature alarm may trace back to blocked cooling airflow. A low-pressure complaint may have nothing to do with compression elements at all and everything to do with leaks, filter restriction, or bad control logic.
Practical rule: Treat every compressor trip as a system problem until the evidence proves it's a component problem.
The three compressor types most reliability teams deal with are reciprocating compressors, rotary screw compressors, and centrifugal compressors. A reciprocating compressor creates pressure with pistons moving in cylinders. A rotary screw compressor uses intermeshing rotors to trap and compress air or gas. A centrifugal compressor increases gas velocity with an impeller and converts that velocity into pressure through diffusion.
Those designs matter because they fail in different ways. Valve leakage and ring wear dominate many reciprocating investigations. Bearing distress, oil quality, and airend problems show up often in screw units. Centrifugal machines bring another class of risks, including aerodynamic instability, seal issues, and rotor-related vibration patterns.
The mistake junior teams often make is trying to memorize symptoms by machine type before they build a decision process. The stronger approach is the reverse. Start with operating condition, control response, and system context. Then narrow the likely failure modes based on compressor design and the evidence in hand.
Systematic Diagnosis Before You Touch a Wrench
The best troubleshooting work usually happens before anyone removes a guard or cracks a fitting. Good teams slow the situation down just enough to capture facts that disappear once the machine is shut down, reset, or disassembled. That discipline prevents expensive guesswork.

Start with the evidence already on the machine
Begin at the controller, not the toolbox. Review active alarms, shutdown history, trend screens, and any recent changes in operating mode. If a food processing plant reports low discharge pressure on a rotary screw package, the controller may already show rising oil temperature, unstable loading, or a history of frequent unload cycles. That points the investigation in a very different direction than a presumed airend failure.
A disciplined first pass should include the following:
- Alarm review: Identify the first-out alarm if the control system captures event order. The first event often matters more than the final trip.
- Operator input: Ask what changed before the failure. Operators often know whether the unit became louder, hotter, or slower to load.
- Process conditions: Compare current suction pressure, discharge pressure, temperature, and load state to the machine's normal operating baseline.
- Maintenance history: Look for repeated resets, repeated filter changes, recurring oil issues, or prior electrical work on the same train.
For industrial air compressors, a structured diagnostic sequence combines power-supply verification, filter inspection, leak testing, thermal imaging, vibration analysis, and lubrication checks. That sequence targets common root causes such as clogged intake filters, air-side leakage, overheating, and misalignment, and guidance on air compressor troubleshooting methods also emphasizes fully isolating power and releasing pressure before physical inspection begins.
A compressor that “suddenly failed” often spent days or weeks giving the plant evidence. The team just didn't collect it in a usable form.
Lock out isolate and inspect in a repeatable order
Once the team has captured the operating evidence, the next step is safety and controlled inspection. Lockout/tagout, or LOTO, means isolating all hazardous energy sources before work starts. On a compressor, that usually includes electrical power, stored pressure, and sometimes process gas, cooling water, or auxiliary systems.
After isolation, the inspection should follow a repeatable order rather than chasing the loudest theory in the room.
- Verify isolation first: Confirm power is removed and internal pressure is relieved. This isn't paperwork. It's what keeps troubleshooting from becoming an incident.
- Inspect intake and filtration: A blocked intake filter can create low capacity, overheating, and unstable operation that mimic internal mechanical problems.
- Check for leakage paths: Soap solution, ultrasonic listening, and careful inspection around fittings, drains, seals, and hoses can reveal faults without teardown.
- Look for thermal clues: Discolored surfaces, baked oil, overheated terminals, and hot spots around coolers or valves often narrow the failure search quickly.
- Assess lubrication condition: Low oil level, wrong oil, contamination, or degraded oil condition can affect bearings, cooling, sealing, and efficiency all at once.
Teams that want more depth on route-based measurement should build this first-pass inspection into a broader vibration analysis of air compressors program so they aren't starting from zero each time a machine trips.
What doesn't work is random part replacement. Replacing a pressure switch because pressure is low, or replacing a motor because the starter tripped, only creates a second problem if the root cause was process restriction, cooling failure, or a bad connection upstream.
Using Data to Pinpoint the Failure Mode
Once the obvious checks are done, compressor troubleshooting becomes a pattern-recognition exercise. The team's job is to separate symptoms from the actual failure mechanism. That's where condition data matters.

One fact should keep every reliability engineer cautious: up to 30% of compressors returned under warranty are later found to have no fault, which shows how often the troubleshooting process itself goes wrong rather than the compressor. That finding supports a structured diagnostic workflow before teardown or replacement, as outlined in this compressor failure diagnosis reference.
What each diagnostic method actually tells the team
Different technologies answer different questions. Problems start when teams expect one tool to answer all of them.
- Vibration analysis helps distinguish between mechanical conditions that can sound similar on the plant floor. Imbalance usually shows up as a strong once-per-turn vibration pattern. Misalignment often affects multiple directions and can couple with temperature rise at bearings or couplings. Bearing damage tends to create higher-frequency content and a rougher signal as the defect progresses.
- Thermal imaging identifies abnormal heat distribution. On compressor trains, that may expose high-resistance electrical connections, cooler fouling, overloaded motors, or a hot bearing housing that hasn't yet become audible.
- Oil analysis looks inside the machine without disassembly. It can reveal wear particles, contamination, lubricant degradation, and signs that the oil is no longer protecting surfaces the way it should.
- Ultrasound is especially effective for leak detection and for identifying friction or impact events that don't yet dominate standard vibration data.
- Motor electrical checks matter when symptoms cross the line between mechanical and electrical. A compressor that won't start may have a machine-side issue, but it may also have a control, supply, or winding problem.
Don't ask whether the machine is “bad.” Ask what physical mechanism can explain the pressure change, the temperature pattern, and the vibration response at the same time.
A useful way to train junior engineers is to make them build a failure hypothesis that connects all available evidence. If they can't explain why a suspected fault would create the observed symptoms, the hypothesis isn't ready for action.
A practical example from a process plant
Consider a centrifugal compressor in a chemical unit where operators report rising vibration and unstable discharge behavior during high-demand periods. A rushed team might blame bearings because vibration is the visible symptom. A better team gathers waveform and spectrum data, compares it to historical baselines, checks process conditions, and looks at temperature distribution across bearings, seals, and the driver.
If vibration rises only in certain operating regions, the fault may be aerodynamic rather than purely mechanical. If thermal data shows a hot electrical connection in the motor control center, the machine may be seeing an electrical supply issue that changes load behavior. If oil condition is poor and wear debris appears, the mechanical side moves back into focus.
A structured condition monitoring approach for reciprocating compressors provides a good model even beyond reciprocating machines. The principle is the same. Build a baseline, trend key indicators, and use multiple data sources before deciding whether the root cause is internal wear, process instability, or a support-system problem.
A mature troubleshooting process doesn't chase single symptoms. It looks for evidence that converges. When vibration, temperature, lubrication condition, and process data all point in the same direction, the team can act with confidence. Until then, teardown is still a theory, not a diagnosis.
Decoding Failures in Reciprocating Screw and Centrifugal Units
A common mistake in compressor troubleshooting is treating all compressors like different-sized versions of the same machine. They aren't. The troubleshooting workflow is universal, but the likely failure modes depend heavily on how the compressor makes pressure.
How failure signatures differ by compressor design
A reciprocating compressor is a positive displacement machine that relies on pistons, rings, valves, and sealing surfaces cycling under load. In oil and gas service, teams often see capacity loss, increased discharge temperature, or uneven cylinder performance. Valve leakage can mimic broader performance decline because the machine still runs, but it no longer compresses efficiently. Ring wear can present as blow-by, declining volumetric performance, or contamination patterns that suggest loss of sealing integrity.
A rotary screw compressor creates compression through rotor timing, internal clearances, and a lubrication system that does far more than lubricate. In many packaged industrial air systems, bearing health, oil condition, separator performance, and cooling efficiency drive reliability. A screw unit with high temperature and poor output may have an airend problem, but it may also have blocked coolers, degraded oil, or a control issue that keeps it operating outside its intended range.
A centrifugal compressor behaves differently because it depends on flow stability and rotor dynamics. In a chemical or power application, process upsets can create behavior that looks mechanical from a distance. Surge is a severe instability where flow reverses or oscillates because the compressor can't sustain the required operating point. Teams may hear changes in sound, see abrupt process instability, and record vibration patterns that don't fit a simple bearing-failure story. Seals and impellers also deserve close attention because damage there affects both performance and rotor behavior.
The machine design should narrow the failure tree immediately. If the team skips that step, troubleshooting turns into parts replacement with better vocabulary.
Common Compressor Failure Modes and Diagnostic Indicators
| Compressor Type | Common Failure Mode | Primary Symptoms | Key Diagnostic Test |
|---|---|---|---|
| Reciprocating | Valve leakage | Reduced capacity, abnormal cylinder temperature pattern, unstable pressure performance | Cylinder performance review, valve temperature comparison, pressure analysis |
| Reciprocating | Piston ring wear | Blow-by signs, reduced compression efficiency, oil contamination concerns | Compression trend review, oil analysis, internal inspection planning |
| Rotary screw | Bearing distress | Increasing vibration, noise change, temperature rise at bearing locations | Vibration analysis, lubricant condition review, temperature survey |
| Rotary screw | Airend performance loss | Low output, longer loaded run time, high temperature, poor efficiency | Pressure and temperature comparison, leak elimination, internal clearance assessment |
| Rotary screw | Oil contamination or wrong viscosity | Heat, poor lubrication response, accelerated wear, erratic operation | Oil analysis, maintenance record review, lubrication system inspection |
| Centrifugal | Surge or flow instability | Unstable pressure, changing sound, fluctuating vibration during certain operating regions | Process data correlation, vibration trending, control review |
| Centrifugal | Seal degradation | Performance loss, leakage concerns, temperature or vibration changes near seal areas | Seal system inspection, thermal imaging, process condition review |
| Centrifugal | Impeller damage or fouling | Reduced performance, imbalance-like vibration, process inefficiency | Vibration analysis, performance comparison, borescope or outage inspection |
That table isn't a replacement for engineering judgment. It's a way to reduce wasted motion. A team troubleshooting a screw compressor in a general manufacturing plant shouldn't jump to the same failure assumptions used for a reciprocating gas compressor. Likewise, centrifugal machines need process and aerodynamic context from the start.
For teams responsible for larger dynamic units, reference material on centrifugal compressor reliability and maintenance considerations can help align troubleshooting with machine design and service conditions.
From Repair to Reliability Choosing the Right Corrective Action
Finding the root cause is only half the job. The harder call is deciding what corrective action makes business sense. A repair that restores operation by tomorrow may still be the wrong decision if it leaves the plant with recurring downtime, unstable performance, or a machine at the end of its useful life.
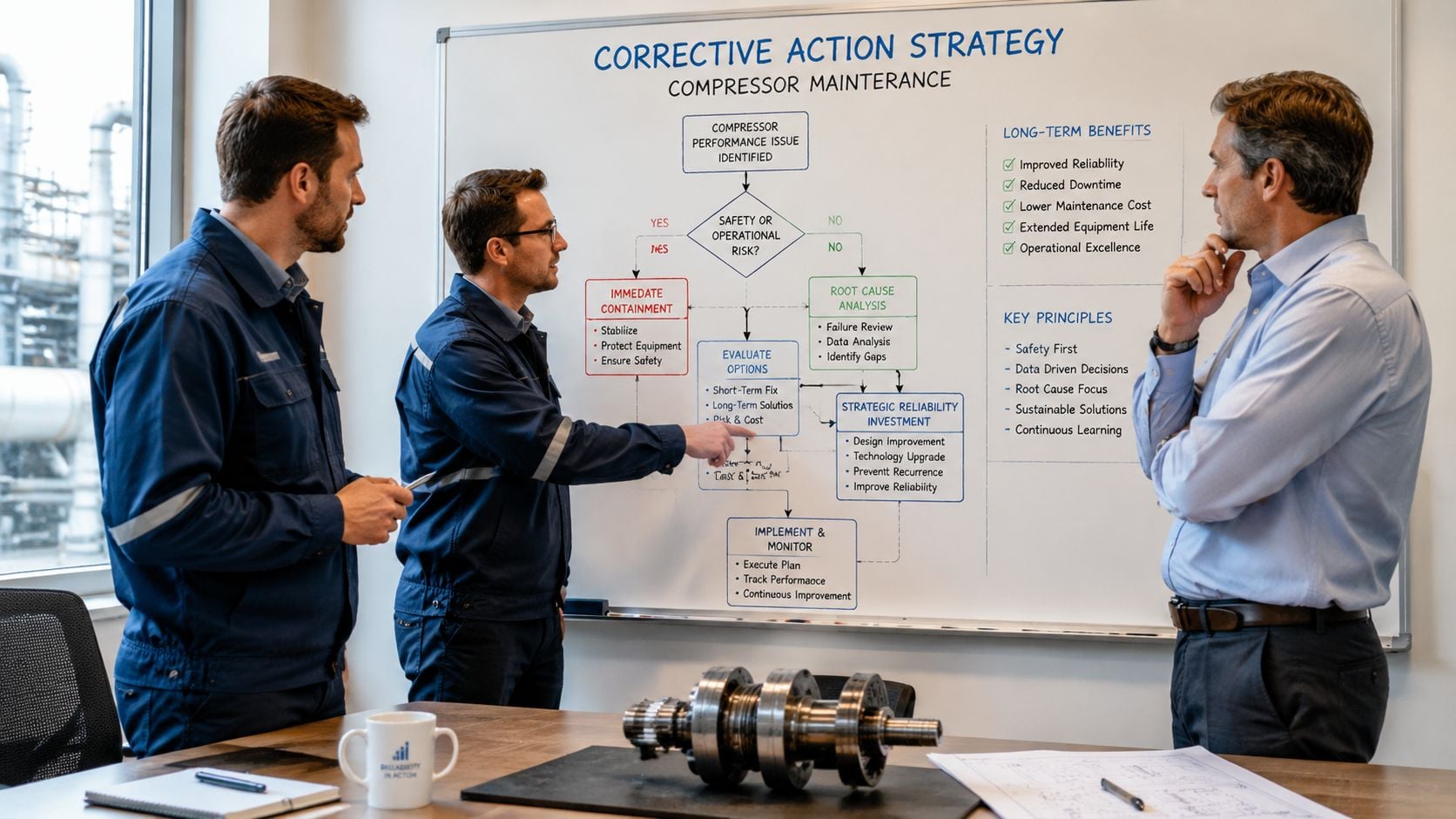
When repair is justified
Repair is usually the right move when the failure is isolated, the asset has solid service history, and the machine's operating context hasn't changed. A screw compressor with a clear cooler blockage, a failed sensor, or localized bearing issue may be a good repair candidate if the rest of the package remains healthy.
A sound repair decision usually includes these questions:
- Is the root cause known: If the team can't explain why the failure happened, repair may only buy a short interval before the next trip.
- Is collateral damage limited: A failed component in isolation is different from a fault that spread contamination or thermal damage through the machine.
- Does the machine still fit the process: Capacity, control range, and energy use still matter after the repair is done.
- Can the plant support the risk: Some assets are too critical for repeated short-term fixes.
A useful planning benchmark is the 50% repair rule. If compressor repair cost exceeds 50% of replacement value, replacement is usually considered more economical, and 10–15 years is often treated as an age range for reevaluation according to this air compressor replacement guideline.
When replacement is the smarter decision
Consider a manufacturing plant with an older screw compressor that needs a major airend rebuild. If the machine also has chronic overheating history, repeated controls work, and declining efficiency, the question isn't whether it can be repaired. It probably can. The question is whether the plant should keep investing in an asset that has already shown its failure pattern.
That's where total cost of ownership matters. The repair estimate is only one line item. Reliability leaders also need to weigh expected downtime exposure, future parts demand, supportability, and whether the plant will spend the next outage chasing the same system again.
A successful corrective action restores function and reduces future risk. If it does only the first part, it's maintenance activity, not reliability improvement.
This is also the point where structured planning helps more than emergency spending approval. A resource such as an industrial compressor maintenance guide can help teams frame the decision around lifecycle, spare strategy, and recurring failure history instead of the immediate pressure to restart.
There's room here for outside technical support when internal resources are thin. Forge Reliability provides predictive maintenance and reliability consulting for rotating equipment, including compressors, using methods such as vibration analysis, thermography, oil analysis, ultrasound, and root cause investigation. That kind of support is most useful when the plant needs evidence for a repair-versus-replace decision rather than another round of trial-and-error maintenance.
Implementing a Proactive Compressor Reliability Program
The job isn't finished when the compressor starts and pressure recovers. The repair has to be verified. If the team replaced a bearing, cleaned a cooler, corrected alignment, or fixed a leak path, the machine should be checked afterward to confirm that temperature, vibration, pressure behavior, and control response have returned to a stable baseline.
Close the loop after the machine is back online
Post-maintenance verification is where many plants lose the value of troubleshooting. They restore operation but don't confirm whether the root cause is gone. A short follow-up routine makes a major difference:
- Recheck condition data: Compare post-repair vibration, temperature, and process behavior to pre-failure and historical baselines.
- Document what changed: Record the actual cause, the physical evidence, the parts used, and any process conditions that contributed.
- Update maintenance tasks: If the failure exposed a weak inspection route or missing PM task, correct it immediately.
- Review operator observations: Their notes often help validate whether abnormal sounds, heat, or cycling behavior have disappeared.
Turn every troubleshooting event into a reliability upgrade
The plants that move out of break-fix mode treat each compressor event as new failure intelligence. They update criticality, revise spare strategy, and refine inspection methods. They also tighten handoff between operations and maintenance so that early warnings don't get buried in shift turnover notes.
That documentation work doesn't need to be complicated, but it does need follow-through. Teams that struggle to capture next steps consistently can benefit from simple digital workflows for meetings and handoffs. A practical example is SpeakNotes' AI solutions for action items, which shows a useful approach for turning discussions into assigned follow-up work so troubleshooting lessons don't disappear after the outage ends.
A proactive compressor reliability program is built one solved problem at a time. The difference is that the best plants don't stop at restoring operation. They use the event to improve diagnosis, decision-making, and prevention across the whole asset base.
If a plant is dealing with recurring compressor trips, uncertain repair-versus-replace decisions, or a maintenance program that's still too reactive, Forge Reliability can help. Schedule a free reliability assessment to review critical assets, failure patterns, and practical next steps for reducing unplanned downtime.


