
A new plant manager usually meets turbine maintenance under pressure, not in a planning meeting. The call comes after a trip, an alarm flood, or a production miss that operations wants explained before the next shift change. By that point, the team isn't debating maintenance philosophy. The team is deciding whether the problem was predictable, whether the outage could've been contained, and whether the same failure is sitting undetected in another machine.
That's why turbine maintenance has to start with decisions, not checklists. Most sites already have inspection forms, lubrication tasks, and annual shutdown routines. What they often lack is a clear method for deciding which failures deserve continuous monitoring, which ones can ride on a route, and which ones still need a scheduled overhaul because they won't announce themselves early enough to trust a condition-based approach.
A wind turbine is a useful example because it compresses the whole problem into one asset class. It has rotating assemblies, structural fasteners, lubrication systems, electrical components, remote access constraints, and a heavy penalty for unplanned work. The same decision logic applies to gas turbines at remote power sites and steam turbines inside process plants. The hardware changes. The reliability choices don't.
Table of Contents
- The High Cost of Turbine Unreliability
- Anatomy of a Turbine Failure
- Your Diagnostic Toolkit for Condition Monitoring
- Designing a Monitoring Strategy Route vs Continuous
- From Data to Decisions With Condition Based Maintenance
- Prioritizing Maintenance with RCM and FMEA
- Building Your Actionable Turbine Maintenance Plan
- Implementation Next Steps and Outsourcing
The High Cost of Turbine Unreliability
The expensive part of a turbine problem usually isn't the failed part. It's everything attached to the event. Production falls off immediately. Operations starts rescheduling loads. Maintenance scrambles for labor, access equipment, and spares. If the turbine sits in a critical utility role, the whole plant starts making worse decisions just to stay online.
Wind fleets make that reality easy to see. Routine maintenance typically happens 2–3 times per year, and one industry source estimates average maintenance cost at about $48,000 per turbine per year according to wind turbine maintenance cost and visit frequency guidance. That number matters less as a budget line than as a warning. If a site is already spending that kind of money to keep one turbine healthy, every wasted visit, repeated dispatch, and poorly scoped outage has to be questioned.
Why planned work beats urgent work
A scheduled job gives the planner options. Labor can be lined up. Tools can be staged. Oil samples can be reviewed before opening the machine. The crew can bundle multiple findings into one outage instead of touching the same asset repeatedly over a short period.
An urgent event removes those options. The team often enters the machine without enough diagnostic context, fixes the loudest symptom, and leaves the underlying failure mechanism in place.
Practical rule: Every turbine maintenance task should answer one of two questions. What failure is this preventing, or what failure is this confirming?
A plant example that repeats everywhere
Consider a process plant with a steam turbine driving a critical compressor. The machine starts showing a slight change in bearing temperature and a subtle shift in vibration behavior during load swings. Nothing looks dramatic enough to force an outage, so operations keeps running. A week later, the trip happens during a high-demand window. What could've been a planned bearing inspection becomes a forced outage with collateral schedule damage.
The same pattern shows up in wind turbines with gearbox, generator, and drivetrain issues. The lesson isn't that every small deviation needs immediate teardown. The lesson is that turbine maintenance pays when the team can separate noise from a developing fault, then act before the machine makes the decision for them.
Anatomy of a Turbine Failure
Turbines don't fail in one uniform way. Some defects creep forward through wear, contamination, looseness, or thermal stress. Others appear fast after a single process upset, lubrication problem, electrical fault, or foreign object event. A maintenance strategy only works when it matches the failure mechanism, not just the asset name.
A steam turbine in power generation is a useful running example. It has bearings, seals, rotor dynamics, coupling alignment, lubrication circuits, and generator interfaces that all degrade on different timelines. A wind turbine follows the same logic across gearbox, generator, blades, yaw system, and structural hardware.
Failure starts in different ways
Bearings usually give some warning if the team knows where to look. Rolling element bearings may show increasing defect frequencies, wear debris, or heat. Fluid-film bearings can move into instability from lubrication problems, clearance changes, or process conditions. These are rarely “surprise” failures in the pure sense. They're often missed interpretation failures.
Blades and rotating aero components are different. Erosion, cracking, impact damage, and structural defects can develop slowly, but the consequence can become urgent quickly once the defect reaches a critical point. That's why visual inspection and load-aware trending matter. Some failures start as a materials problem and finish as a dynamic problem.
Seals often get ignored because they don't look dramatic on a failure report. That's a mistake. Labyrinth seal wear, leakage path changes, and rubbing events can drive efficiency loss, contamination, heat, and downstream component stress. The machine may stay online while performance drifts and damage accumulates.
Gearboxes and generator trains fail through a mix of mechanical and electrical mechanisms. Gear tooth distress, bearing wear, misalignment, looseness, winding degradation, and insulation-related heating each leave different fingerprints. Some show up first in oil. Some show up first in vibration. Some only become obvious after the machine has already lost useful life.
Why physical inspection still matters
A key benchmark for wind turbines is that about 82.5% of all maintenance activity is hardware-related, which means technicians usually need to be on-site. The same benchmark notes that a turbine may contain as many as 25,000 bolts, underscoring the importance of mechanical integrity and inspection according to this wind turbine hardware maintenance benchmark.
That point matters far beyond wind. Data can identify a suspect machine, but data doesn't replace a torque check, a borescope inspection, a seal examination, or a close look at a loosened support.
A turbine can be digitally visible and mechanically neglected at the same time.
For a plant manager, the takeaway is simple. Don't organize turbine maintenance around component lists alone. Organize it around failure development speed, detectability, and consequence.
A practical map looks like this:
| Subsystem | Typical failure behavior | Best early clue |
|---|---|---|
| Bearings | Often gradual | Vibration trend, temperature, lubricant condition |
| Seals | Progressive performance loss or rubbing | Heat pattern, leakage signs, efficiency change |
| Gear train | Progressive wear with occasional rapid escalation | Vibration, oil debris, noise change |
| Generator | Mechanical or electrical degradation | Thermal pattern, electrical signature, vibration |
| Structural hardware | Looseness and fatigue accumulation | Physical inspection, torque verification |
Your Diagnostic Toolkit for Condition Monitoring
Condition monitoring only helps if the team picks the right tool for the right failure. Too many turbine programs treat diagnostics as a menu to buy from rather than a decision system. A better approach is to ask what physical change the team is trying to detect, then choose the method that can see that change early and clearly.
The most useful turbine toolkit usually combines mechanical, lubricant, thermal, and electrical methods. For teams building out that mix, this overview of condition monitoring for gas turbines is a practical companion to the decision logic below.

What each technology is actually good at
Vibration analysis measures dynamic behavior in rotating equipment. It's the first choice for imbalance, misalignment, looseness, resonance, rolling element bearing defects, and many gearbox problems. On a turbine train, it helps separate whether the machine has a rotor problem, a support problem, or a driven-equipment problem. Its weakness is interpretation. Vibration data is powerful, but poor sensor placement, weak baselines, and generic alarms create confusion quickly.
Lubricant analysis looks at the machine's internal wear environment through the oil. It's especially useful for gearboxes, bearings, and lubricated auxiliary systems. It can reveal contamination, degradation, and wear particles before external symptoms become obvious. Its limitation is scope. It won't diagnose every failure mode, and it often needs vibration or inspection data to confirm exactly where the wear is coming from.
Infrared thermography shows abnormal temperature patterns. It's valuable for generator terminals, electrical connections, insulation concerns, bearing housings, lube skids, and cooling-related issues. It's a strong screening tool because hot spots often point directly to resistance, friction, or heat transfer problems. Its limitation is that temperature is often a late or secondary symptom, not the first detectable sign.
Airborne ultrasound detects high-frequency sound produced by friction, turbulence, leakage, and electrical discharge. It's useful on compressed air systems around turbine auxiliaries, steam traps in steam turbine systems, some bearing checks, and certain electrical inspections. It's less helpful as a primary diagnostic for deeper turbine rotor dynamic issues.
Motor current signature analysis, often shortened to MCSA, examines electrical current patterns to infer faults in motor-driven systems and some generator-related electrical conditions. It belongs in the toolkit where electrical faults matter. It doesn't belong everywhere. It won't tell the team much about a steam chest, and it won't replace vibration on a gearbox.
Where teams misuse the toolkit
The most common mistake is expecting one technology to carry the whole program. Turbine maintenance doesn't work that way. A gearbox bearing problem may first suggest itself in vibration, gain confidence through oil analysis, and be scoped for action through inspection planning. A generator issue may present thermally and electrically before vibration becomes useful.
Another mistake is collecting data without a failure question. If the route says “take vibration” but nobody has defined the likely failure modes, the route becomes a compliance exercise instead of a reliability tool.
Field advice: If a diagnostic technology can't be tied to a specific failure mode and a maintenance decision, it's being used as a ritual.
Turbine Condition Monitoring Technology Comparison
| Technology | Primary Application | Detects |
|---|---|---|
| Vibration Analysis | Rotating mechanical condition | Imbalance, misalignment, looseness, bearing and gear defects |
| Lubricant Analysis | Lubricated component health | Wear debris, contamination, oil degradation |
| Infrared Thermography | Thermal screening of mechanical and electrical systems | Hot spots, poor connections, friction heating, cooling issues |
| Airborne Ultrasound | High-frequency leak and friction detection | Leakage, discharge, early friction signatures |
| MCSA | Electrical condition assessment | Electrical asymmetry, rotor and stator related issues |
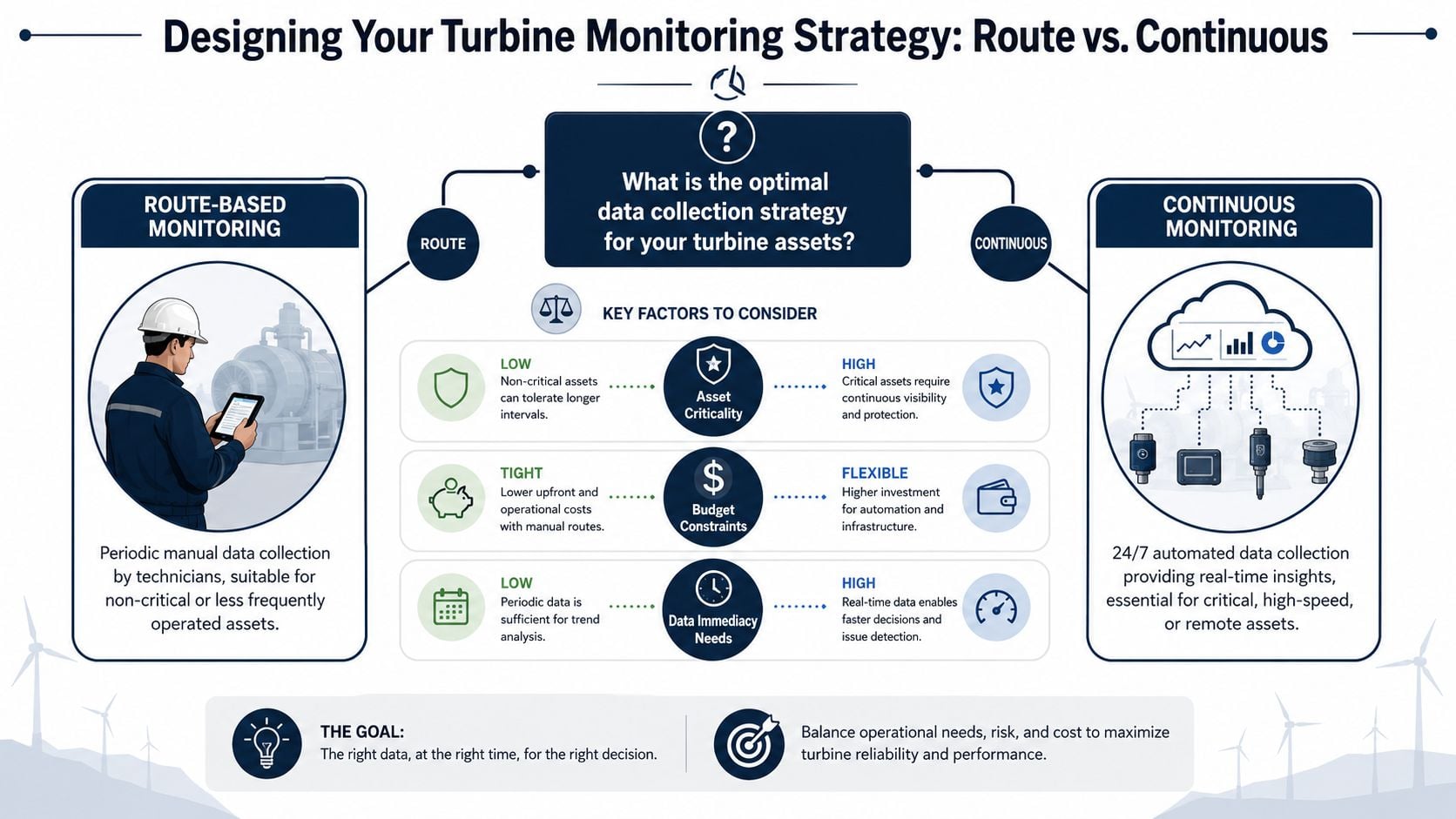
Designing a Monitoring Strategy Route vs Continuous
The right monitoring strategy depends less on technology than on consequence. A turbine that can fail without backup, in a location where access is difficult or response is slow, should not be treated like a lightly loaded spare machine in an accessible building. Route-based and continuous monitoring both work. The mistake is using either one by habit.
A useful benchmark comes from wind operations. A 2024 analysis of a 3-year SCADA database from five 2.5 MW wind turbines shows how continuous sensor data supports normal behavior models and identifies deviations before failure escalates, documenting the shift from fixed-interval service toward data-driven fault detection in this SCADA dataset analysis.
For sites building route programs, this vibration monitoring route setup guide is a practical reference for turning a loose collection schedule into a usable reliability process.
When route-based monitoring makes sense
Route-based monitoring is usually the right fit when the asset is important but not a single point of failure, the failure develops over a manageable interval, and the machine is accessible enough for regular inspection. This often fits smaller steam turbines in facilities with redundancy, or non-critical driven trains where a planned outage can be arranged without heavy production loss.
Route-based programs work well when:
- Failure modes are slow-moving: Bearing wear, lubrication drift, and alignment changes often trend over time.
- Assets are accessible: Technicians can collect repeatable data safely and consistently.
- The plant can tolerate some delay: The business impact of waiting until the next scheduled route is acceptable.
When continuous monitoring earns its keep
Continuous monitoring belongs on turbines where the business cost of not seeing the problem early is too high. That includes remote wind assets, large gas turbines supporting critical generation, and process turbines whose trip can starve a bottleneck unit or destabilize the plant.
It's especially defensible when:
- The turbine is a single point of failure: One trip creates immediate production or utility risk.
- The failure develops faster than a route can catch: A weekly or monthly visit leaves too much blind time.
- Data context matters: The machine behaves differently across load, weather, process state, or startup conditions.
Continuous monitoring isn't justified because a turbine is expensive. It's justified because delay in detection is expensive.
A practical comparison helps. A combined-cycle gas turbine feeding a critical power block usually needs continuous data because operating state changes are frequent and the consequence of missing a developing issue is severe. Several smaller redundant steam turbines in a manufacturing complex may be better served by disciplined route collection, targeted oil analysis, and defined escalation triggers.
From Data to Decisions With Condition Based Maintenance
Collecting data isn't condition-based maintenance. Acting on interpreted data is. The gap between those two is where many turbine programs stall. They install sensors, build dashboards, and still end up running mostly reactive work because nobody translated the data into decision rules that planners and supervisors can trust.
A mature CBM program uses operating data, diagnostics, and maintenance logic together. In wind turbines, SCADA data combined with machine-learning or expert-rule diagnostics can flag developing anomalies in the gearbox, generator, and drivetrain so maintenance can be scheduled around remaining useful life instead of waiting for a trip, as described in this overview of SCADA-driven fault detection.

Teams that want help structuring that logic often use services such as predictive maintenance with machine learning to combine analytics with maintenance execution rules.
A useful alarm philosophy
Good alarms are specific enough to matter and calm enough to avoid panic. That means separating simple notification from maintenance action.
A practical turbine alarm structure usually includes:
- Baseline deviation alarms: These flag that the machine no longer behaves like its own historical normal under comparable operating conditions.
- Diagnostic alarms: These point toward a likely failure family, such as bearing distress, lubrication degradation, or cooling deficiency.
- Action thresholds: These connect the alarm to a required response, such as resample, inspect, reduce load, schedule outage work, or prepare parts.
The wrong way to manage alarms is to dump every exception into one queue. That teaches the plant to ignore alarms. The better method is to pair each alarm with a defined question and a defined owner.
A gearbox example from alert to work order
Take a wind turbine gearbox with a developing outer-race bearing defect. The first sign may be a small but repeatable shift in vibration behavior at a bearing-related frequency band. Around the same period, oil analysis may show wear debris that supports a mechanical wear mechanism instead of a simple operating upset.
That combination shouldn't trigger immediate teardown by default. It should trigger a structured response:
- Validate the signal: Confirm sensor health, operating state, and repeatability.
- Cross-check another technology: Review the latest oil result or collect a targeted sample.
- Classify urgency: Decide whether the defect is stable, progressing, or accelerating.
- Convert to work: Create a scoped work order with inspection steps, expected findings, parts review, and outage timing.
The best CBM programs don't just detect faults earlier. They make earlier detection easier to act on.
That's the point. Turbine maintenance becomes profitable when the data stream ends in a planned, correctly scoped maintenance event instead of another meeting about whether the alarm is “real.”
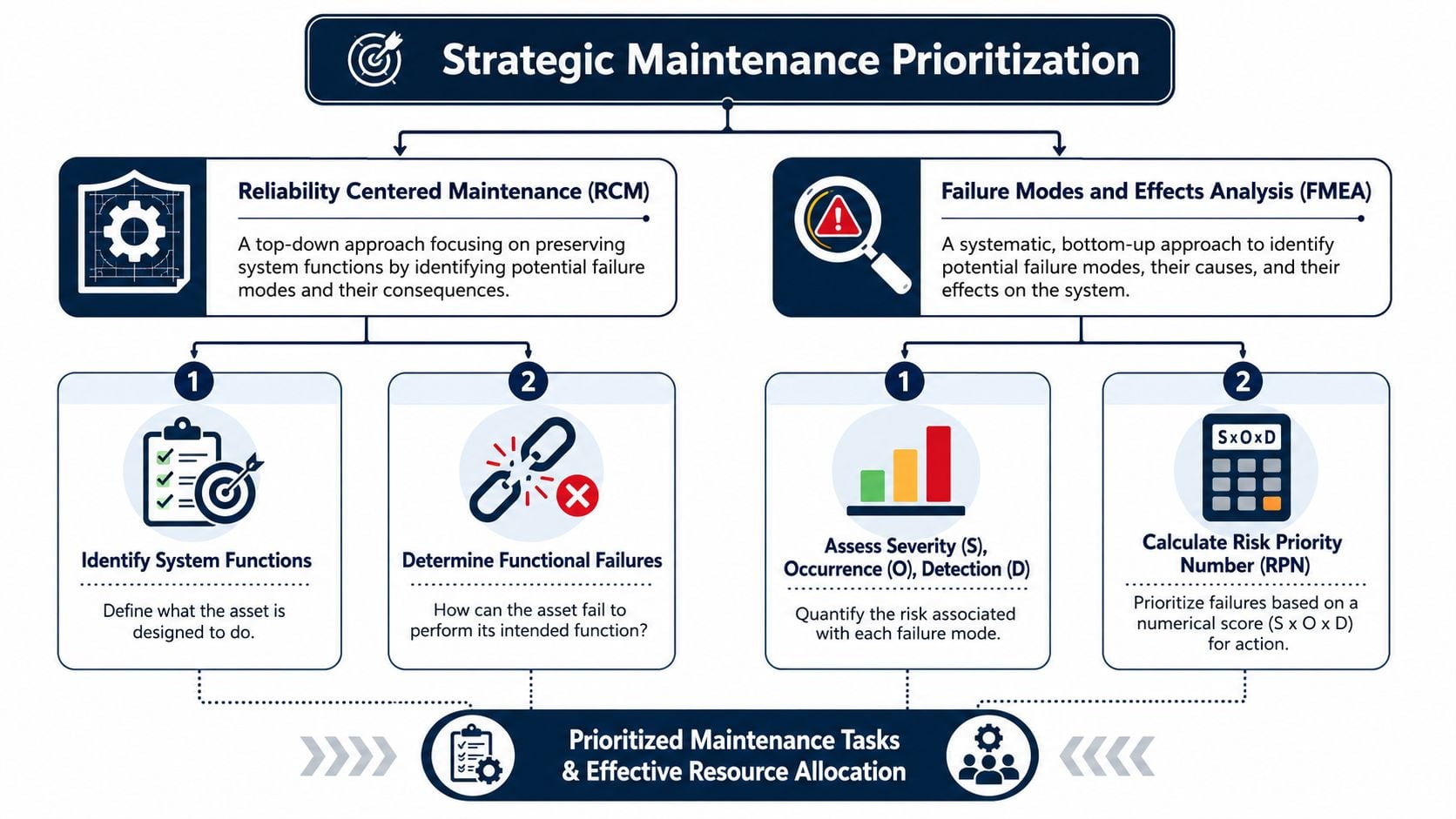
Prioritizing Maintenance with RCM and FMEA
Most turbine sites don't have a shortage of possible work. They have a shortage of capacity, outage windows, specialist labor, and management attention. That's why Reliability Centered Maintenance, or RCM, and Failure Modes and Effects Analysis, or FMEA, matter. They give the team a disciplined way to decide which failures deserve monitoring, which require scheduled restoration, and which can safely run to failure.
The key strategic issue is choosing between scheduled overhauls and condition-based maintenance. Research summarized by PNNL indicates CBM can be more cost-effective, but OSTI notes the answer depends on the failure mode. Gearbox bearing wear may be detectable early with monitoring, while faults such as generator shorts are harder to predict. That's why an FMEA is essential when selecting a maintenance strategy, as discussed in this PNNL wind maintenance strategy resource.
For teams formalizing that process, this reliability-centered maintenance implementation guide is a practical place to translate theory into plant execution.
FMEA decides what deserves attention
FMEA starts with failure modes, not maintenance tasks. On a turbine, that means listing specific ways the asset can fail. Bearing spall. Seal rub. Gear tooth distress. Winding insulation breakdown. Fastener loosening. Control fault. Then the team ranks each one by consequence, likelihood, and how likely it is to be detected before function is lost.
Many plants face the truth about their operational risks for the first time. A failure mode that sounds dramatic may be rare or easily caught. Another that seems routine may carry severe production or safety impact with poor detectability.
A useful turbine FMEA asks:
- What function is being lost: Power generation, steam balance, compressor drive, safe overspeed control, or lubrication integrity.
- What causes that loss: Wear, contamination, misalignment, electrical stress, thermal cycling, looseness, or operator response.
- What warning exists: Vibration, thermal change, oil debris, SCADA trend shift, inspection evidence, or none at all.
RCM decides what task belongs on the plan
RCM takes the ranked failure modes and chooses the maintenance response that fits each one. That response isn't always predictive. That's the point.
For a detectable, high-consequence, progressively developing failure such as gearbox bearing wear, CBM is often the right answer. For a wear-out mode with poor early detectability but known restoration interval, a scheduled overhaul may be justified. For a non-critical, low-consequence item with little downside, run-to-failure may be the smartest choice.
A new plant manager should expect those three outcomes in the same turbine program. Uniformity is comforting, but it's rarely economical.
Decision test: If a failure can't be detected with enough warning to change the maintenance outcome, monitoring alone won't save the asset.
A steam turbine example makes this clear. Journal bearing distress with good vibration and temperature observability may justify a condition-based task. Insulation failure in a generator component with limited early warning may still require scheduled testing or time-based intervention. The right answer depends on detectability and consequence, not on whether the site prefers predictive maintenance in principle.
Building Your Actionable Turbine Maintenance Plan
A usable turbine maintenance plan fits on paper, ties directly to failure modes, and tells each role what to inspect, collect, escalate, and close. If the plan only says “inspect turbine quarterly,” it's not a plan. It's a placeholder.
For turbine-heavy sites with scattered records, one practical improvement is to centralize work orders, inspection history, and parts data so supervisors can manage assets with facility management workflows instead of chasing disconnected spreadsheets and emails. The tool matters less than the discipline. One source of truth is what makes trends usable.
What should be on the plan
For a quarterly inspection on a gas turbine or steam turbine support train, the work package should define exactly what “good” and “bad” look like.
A strong plan includes items such as:
- Vibration points: Fixed measurement locations, collection direction, operating state requirements, and the alarm path if a point can't be collected repeatably.
- Thermal inspection zones: Generator terminals, bearing housings, lube system coolers, electrical cabinets, and other known heat-risk locations.
- Lubrication checks: Sample location, sample condition, contamination watch points, filter condition, and top-up or change criteria.
- Mechanical integrity tasks: Coupling guard inspection, base and hold-down condition, visible leakage, unusual noise, and support looseness.
- Control and protection verification: Alarm history review, permissive status, trip circuit health, and instrument anomalies requiring follow-up.
A wind turbine example follows the same structure. Each planned visit should have a reasoned scope for gearbox, generator, blades, bolts, corrosion, and lubrication, not just a generic service list.
What should be measured
A maintenance plan needs outcome measures, but those measures should be tied to behavior the team can influence. If the KPI can't change a decision, it doesn't belong in the review deck.
Useful turbine KPIs include:
| KPI | What it tells the team |
|---|---|
| Unplanned downtime events | Whether failure prevention is improving |
| Mean time between failures | Whether asset reliability is moving in the right direction |
| Repeat failure count | Whether root causes are being eliminated or merely repaired |
| Planned vs urgent turbine work | Whether the site is converting surprises into scheduled jobs |
| Work order scope completion quality | Whether outages are being prepared well enough to avoid rework |
Some organizations also track maintenance cost against asset value, but the primary value comes from trend and cause analysis, not from publishing a ratio without context.
A short planning rule helps. Every outage should leave the site with three things: the defect corrected, the cause understood, and the route or monitoring strategy updated so the same issue is easier to catch next time.
Implementation Next Steps and Outsourcing
The first implementation step is procedural, not technical. Predictive findings have to land in the same maintenance workflow that planners and supervisors already use. If a vibration analyst identifies a developing turbine fault but the CMMS receives only a vague note, the plant will lose the value in translation. The work order needs fault description, urgency, likely failure mode, confirming task, and outage recommendation.
The second step is training. Technicians need more than tool instruction. They need reliability context. They should know why a data point matters, what defect it supports, and what visual evidence should confirm or contradict the diagnosis.
The third step is deciding what to keep in-house. Some sites should build internal capability for routine routes, inspections, and first-level screening. Others should outsource advanced diagnostics, alarm review, and program design because turbine analysis requires specialist skill and disciplined governance. Both models can work if responsibilities are clear.
For plants weighing external support, this overview of maintenance outsourcing for gas turbines gives a realistic picture of where outside expertise fits. Forge Reliability is one option for facilities that need condition monitoring, RCM, FMEA, and turbine reliability support without building the full specialist stack internally.
The right model is the one that turns findings into action fast, keeps ownership clear, and improves uptime without creating another layer of reporting nobody uses.
If a plant is dealing with recurring turbine alarms, forced outages, or uncertainty about where CBM fits, a free reliability assessment from Forge Reliability can identify the highest-value failure modes, the right monitoring approach, and the maintenance changes most likely to reduce unplanned downtime.


