
A maintenance manager usually doesn't start looking for predictive maintenance machine learning because of curiosity. The search starts after a night call, a missed shipment, a seized pump, or a gearbox that gave warning signs nobody connected in time. The frustration isn't just the failure itself. It's knowing the machine was likely talking through vibration, temperature, current, oil condition, or process behavior long before production stopped.
That gap between raw signal and maintenance action is where most programs succeed or fail. Plenty of plants already collect data. Far fewer turn that data into a reliable decision about what's failing, how urgent it is, and whether the right response is inspection, planned repair, alignment correction, lubrication work, or immediate shutdown. Predictive maintenance machine learning matters because it helps convert condition data into a decision framework that operations and maintenance can trust.
Table of Contents
- From Reactive Repairs to Intelligent Reliability
- Mapping Sensor Data to Physical Failure Modes
- Building a High-Quality Industrial Data Pipeline
- Feature Engineering for Rotating Equipment Data
- Choosing the Right Machine Learning Model Family
- Deploying Models and Integrating with Maintenance Workflows
- Common Pitfalls in PdM Machine Learning Projects
- Frequently Asked Questions
From Reactive Repairs to Intelligent Reliability
Reactive maintenance always feels expensive because the plant pays several times for the same event. First comes the failure. Then the production interruption. Then overtime, expedited parts, quality risk, and the follow-on damage that often spreads beyond the original component. A failed process pump can take out a seal, damage a coupling, overload a motor, and force operators into unstable process conditions.

Predictive maintenance machine learning changes the sequence. Instead of asking, “What broke?” after the event, the plant asks, “What measurable condition change is happening now, and when does it justify action?” That's a different operating model than either break-fix work or time-based PMs. For teams weighing that shift, a practical comparison of predictive vs preventive maintenance helps clarify where machine learning belongs and where simple preventive tasks still make sense.
The business case is no longer theoretical. According to McKinsey-cited analysis on predictive maintenance AI outcomes, implementing a predictive maintenance AI program can cut overall maintenance costs by 10% to 40% and reduce unplanned equipment downtime by up to 50%.
Why reliability teams care about the shift
Calendar-based maintenance still has a role, especially for statutory tasks, obvious wear parts, and low-criticality assets. But calendar logic struggles with variable loads, inconsistent operating environments, process upsets, and machine-to-machine differences. Two identical motors on paper can age very differently in service.
Machine learning becomes valuable when the asset gives detectable precursors before failure. That's common in rotating equipment such as pumps, motors, fans, compressors, and gearboxes. Bearings generate vibration changes. Lubrication problems alter temperature and particle behavior. Misalignment changes radial and axial response. Cavitation creates unstable hydraulic and vibration signatures.
Practical rule: Don't treat machine learning as a replacement for reliability fundamentals. It works best when the plant already knows which assets are critical, which failure modes matter, and what intervention options are available.
A strong PdM program doesn't just identify abnormality. It creates a maintenance decision with enough context to act before the failure becomes an outage.
Mapping Sensor Data to Physical Failure Modes
Machine learning can't infer plant reality from bad framing. If a team feeds sensor data into a model without linking it to actual failure mechanisms, the result is usually an alert stream that sounds advanced but doesn't support planning. The starting point is always the same. Define the failure mode first, then identify which signals should change as that failure develops.
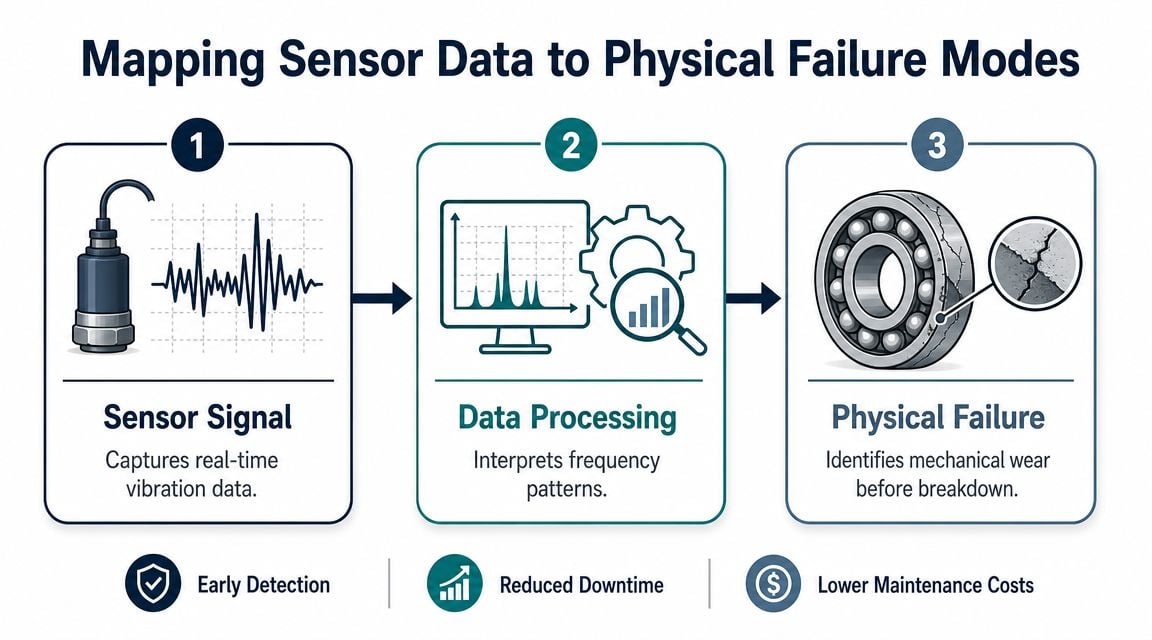
Failure signatures have to match real mechanics
Take a motor-driven gearbox conveyor in a packaging plant. If the concern is bearing wear, the machine often shows rising vibration energy, especially in frequency bands tied to bearing defect behavior. If the concern is shaft misalignment, the response may show stronger synchronous vibration with directional changes across horizontal, vertical, and axial measurements. If the concern is gear tooth pitting, the pattern can include changes around gear mesh behavior and sideband activity as load passes through damaged teeth.
A process pump gives a different profile. Cavitation may produce unstable vibration and acoustic behavior tied to hydraulic disturbance. Seal degradation may show as thermal change, leakage evidence, or changing shaft behavior. Flow restriction often changes operating context before it shows up as a hard mechanical failure. That's why process tags matter alongside mechanical data.
For motor assets, teams often get more value when they tie signals back to known electrical and mechanical failure paths. Practical motor diagnostics matter more here than generic AI claims. A detailed guide to condition monitoring for induction motors is useful because it keeps the analysis grounded in actual motor failure behavior.
The translation layer sits between alarm and action
The useful question isn't whether vibration is “high.” The useful question is whether the vibration pattern indicates a developing defect with a maintenance window wide enough to plan around. That's where the translation layer earns its keep. It converts a signal change into a probable failure mode, urgency, and action path.
High-value models need more than sensor streams. As noted in this discussion of AI in predictive maintenance, high-value ML models work best when they fuse condition-monitoring signals like vibration and temperature with failure-history labels from a CMMS or EAM. Without that link to repair logs and operating context, the model may detect an anomaly but still fail to prioritize the asset, failure mode, or intervention window that matters for uptime.
That point is critical on the plant floor because the same sensor pattern can mean different things under different loads or process states.
- Load matters: A gearbox under heavy throughput won't present exactly like the same gearbox in idle or low-demand service.
- History matters: A repaired motor with known soft foot or repeated alignment drift should be interpreted differently than a stable machine with no recurring issues.
- Failure mode matters: An anomaly that points to bearing lubrication degradation needs a different work order than one pointing to rotor imbalance.
The best models don't just say something changed. They say what likely changed, where, and what the maintenance team should check next.
Many plants already understand the P-F curve qualitatively, even if they don't label it that way. There's a period between potential failure and functional failure when degradation becomes measurable before the machine can no longer do its job. Predictive maintenance machine learning is most effective when it detects that measurable degradation early enough to support scheduling, parts planning, and risk-based decisions rather than emergency response.
Building a High-Quality Industrial Data Pipeline
Many predictive maintenance projects get framed as model-selection problems. In practice, most early failures come from data collection, timestamp alignment, naming inconsistency, and missing operating context. The model doesn't struggle because machine learning is weak. It struggles because the data pipeline doesn't reflect how the plant runs.
The scale of investment shows that industry has moved beyond experimentation. The global predictive maintenance market was valued at $5.5 billion in 2022, with a projected 17% CAGR, according to industry analysis on predictive maintenance market growth. That growth reflects the need for sensors, historians, integration layers, and workflow-ready data, not just analytics software.
Route-based and continuous data serve different jobs
A route-based program works well when assets are moderately critical, failure modes develop gradually, and the plant needs broad coverage without instrumenting every machine full-time. A technician collects measurements on a defined route, often focusing on vibration, temperature, ultrasound, or lubrication condition. Many plants start here because it's practical and forces discipline around asset hierarchy and inspection quality. A useful reference is this guide to vibration monitoring route setup.
Continuous monitoring fits a different need. It's the better choice for assets with short failure development windows, severe downtime consequences, unstable operating conditions, or remote locations. A high-speed compressor, critical cooling water pump, or heavily loaded gearbox may change too quickly for monthly or even weekly route data to catch the useful intervention window.
A simple way to think about the trade-off:
| Data approach | Best fit | Strength | Limitation |
|---|---|---|---|
| Route-based monitoring | Broad asset populations with slower degradation | Lower instrumentation burden and strong technician context | Gaps between readings can miss rapid events |
| Continuous monitoring | Critical assets with fast or costly failure modes | Better visibility into evolving behavior and transients | More integration, governance, and alarm management work |
Most data problems are plant problems, not model problems
A reliability engineer may have vibration data in one system, temperature in another, process load in a historian, and repair history in a CMMS with inconsistent failure coding. That isn't unusual. It's also why many machine learning pilots stall.
Common pipeline issues include the following:
- Timestamp mismatch: Sensor clocks, historian clocks, and CMMS event times often don't line up cleanly. If a bearing replacement appears to happen before the abnormal trend began, the label is useless.
- Bad asset hierarchy: Sensors may be assigned to the line, not the exact motor, pump, or gearbox. The model then learns vague site behavior instead of asset behavior.
- Dropouts and noise: Wireless gaps, loose sensors, poor mounting, and electrical interference create false patterns.
- Missing operating context: Speed, throughput, valve position, suction condition, ambient temperature, and batch changes all affect interpretation.
What a usable pipeline looks like
The strongest pipelines usually share a few traits:
- Clear asset identity across sensor tags, historian records, and work orders.
- Consistent event labeling so the team can distinguish bearing change, lubrication correction, alignment work, process upset, and confirmed failure.
- Context tagging for speed, load, product grade, or operating mode.
- Data quality rules that flag stale signals, impossible values, and sensor drift.
A plant doesn't need perfect data to start. It does need data that matches physical assets, known failure events, and the timing of real maintenance actions.
If those basics aren't in place, the analytics team usually ends up modeling noise from the maintenance system rather than degradation in the equipment.
Feature Engineering for Rotating Equipment Data
Feature engineering is where predictive maintenance machine learning becomes useful to reliability teams instead of remaining a data-science exercise. Raw signals carry information, but they rarely line up in a form that directly answers a maintenance question. A waveform, temperature stream, current trace, or oil sample record has to be translated into features that capture condition changes linked to failure modes.

Raw waveforms rarely answer a maintenance question
A vibration waveform from a gearbox is dense, noisy, and heavily shaped by speed, load, sensor location, and structural response. A model trained directly on unmanaged raw data may still find patterns, but plant teams often struggle to interpret the result or trust the recommendation. Features solve that by summarizing the raw signal into measures that align with machine behavior.
This is also why reliability and data work can't be separated. Feature engineering requires knowledge of how machines fail, what the sensors can observe, and what maintenance action follows from the change. Teams that want a broader primer on building better datasets for AI projects will recognize the same principle. Better features produce better decisions because they encode the most useful information from the raw data.
For rotating equipment, this usually means deriving features from vibration, thermal behavior, current, oil condition, and operating state. A practical field reference for vibration analysis and vibration monitoring equipment helps tie those feature choices back to collection quality.
Examples that turn signals into usable model inputs
A motor and pump train in a wastewater plant provides a good example. The plant may collect radial vibration at both bearings, casing temperature, motor current, and oil sample results from the coupled gearbox.
Useful feature choices might include:
- Vibration severity features: RMS and overall amplitude help indicate general condition change. They're often useful for broad screening but weak on their own for fault isolation.
- Impact-sensitive features: Crest factor or related impulsiveness measures can help expose early bearing or mechanical contact behavior before overall levels rise substantially.
- Frequency-band energy: Summarizing energy within targeted bands can isolate where defect activity is growing. This is often more useful than a single overall value when the goal is to distinguish bearing, gear, or structural effects.
- Temperature trend features: Absolute temperature matters, but rate of change can matter more. A gradual thermal drift after lubrication degradation may be more meaningful than a stable high operating temperature that has always been normal for that service.
- Current-derived features: For motors, current behavior can add electrical context that vibration alone won't provide. Motor current signature analysis can help surface certain rotor or load-related issues.
- Oil condition features: Particle counts, contamination indicators, or changes in lubricant condition can provide strong evidence for wear progression in a gearbox when paired with mechanical and operating data.
Feature engineering also means choosing the right windowing and normalization logic. If a blower runs at multiple speeds, the team may need speed-normalized vibration features. If a pump cycles on and off, startup and steady-state data shouldn't be blended into the same health score without context.
A practical workflow often looks like this:
| Signal type | Example feature | Why it matters | Typical maintenance value |
|---|---|---|---|
| Vibration | RMS, crest factor, band energy | Captures severity and defect behavior | Supports inspection, alignment, bearing checks |
| Temperature | Rate of rise, stabilized operating band | Separates chronic heat from changing heat | Helps identify friction, cooling, lubrication issues |
| Motor current | Signature changes under load | Adds electrical and driven-load context | Supports motor and process-side troubleshooting |
| Oil analysis | Wear debris and condition indicators | Tracks internal wear and lubrication health | Helps plan gearbox inspection or lubricant correction |
Field note: The most useful feature isn't always the most complex one. A well-defined trend tied to a known failure mode usually beats a mathematically elegant feature that nobody can explain or act on.
Good feature engineering creates explainability. When a planner asks why the model flagged a gearbox, the answer should connect to observable machine behavior, not just an abstract score.
Choosing the Right Machine Learning Model Family
The model family should match the maintenance question. That sounds obvious, but many PdM efforts still start by picking an algorithm before anyone defines the decision the plant needs to make. Reliability teams don't need a model because a model is available. They need one because they're trying to answer a specific operational question with enough confidence to trigger action.
Start with the reliability question, not the algorithm
A packaging line gearbox, for example, may raise several different questions:
- Is the machine behaving abnormally compared with its own baseline?
- Is the issue more likely to be bearing damage, gear wear, or load-related disturbance?
- How long can the asset likely run before the risk becomes unacceptable?
- Is the condition changing fast enough to justify an urgent work order?
Those are not the same problem, so they shouldn't be handed to the same model type by default.
According to guidance on machine learning models for predictive maintenance, common production models include classification algorithms such as SVM and Random Forest, regression models such as XGBoost, and sequence models such as LSTMs for time-series forecasting. The same guidance notes that fast, transient events favor classification or anomaly detection, while gradual wear-out mechanisms are better suited for regression.
Matching model family to asset behavior
The comparison below gives a practical way to frame model selection with plant teams and analytics teams in the same room.
| Model Family | Reliability Question Answered | Common Algorithms | Best For |
|---|---|---|---|
| Classification | What fault is this most likely to be? | SVM, Random Forest | Labeled failure modes such as bearing fault, misalignment, or gear damage |
| Regression | How is the health variable trending, and when is it likely to cross a limit? | XGBoost | Gradual degradation, wear progression, or remaining-life style estimates |
| Anomaly detection | Is this asset operating outside its learned normal pattern? | Statistical and ML anomaly methods | Rare faults, unknown faults, or limited failure labels |
| Sequence modeling | What is the next state of this signal or condition trend? | LSTM | Time-dependent patterns where history shape matters |
A classification model is useful when the plant has decent labels and the maintenance response changes by fault type. If the system can distinguish probable bearing damage from probable misalignment, the planner can assign the right technician, parts, and outage window. That's valuable on a motor-pump train where alignment correction, bearing replacement, and hydraulic correction are different jobs.
Regression is better when the main concern is progression over time. A slowly degrading gearbox with consistent load may lend itself to trend-based prediction if the team has enough history linking engineered features to maintenance outcomes. Regression can also support threshold planning, such as estimating when a risk index will enter a response zone.
Anomaly detection earns its place when labels are sparse, especially on critical assets that rarely fail and therefore don't generate much supervised training data. This is common with turbines, large compressors, or protected process equipment. The model learns normal behavior and flags departures from that baseline. The trade-off is straightforward. It may detect abnormality well but still need expert review to identify the exact failure mode.
Sequence models fit assets whose history shape matters. A rolling mill gearbox or variable-speed fan may show condition patterns where a single snapshot is less meaningful than the trajectory over time. Sequence methods can capture those temporal relationships, but they demand cleaner, better-structured time data than simpler models.
A few selection rules keep teams out of trouble:
- Choose the simplest model that answers the maintenance question. If a clear classifier or regression model works, there's no value in adding complexity for its own sake.
- Match model behavior to failure physics. Sudden, short-window failure signatures don't behave like slow wear-out curves.
- Prefer explainable outputs where action is expensive. If the prediction triggers a shutdown or major outage planning, the maintenance team needs transparent reasoning.
- Account for data reality. A model that depends on rich labels won't perform well if work-order closure codes are inconsistent.
Don't ask one model to do everything. Plants usually need a layered approach, with screening, diagnosis, and planning logic separated instead of forced into one score.
That layered approach mirrors how experienced analysts already work. They first notice abnormal behavior, then identify the likely defect, then decide how urgently to act.
Deploying Models and Integrating with Maintenance Workflows
A strong model with weak deployment discipline won't change reliability results. Plants don't get value from predictions sitting in an analytics dashboard that nobody reviews during shift turnover, planning meetings, or weekly scheduling. Value appears when the model output is inserted into the same maintenance workflow that already governs inspection, prioritization, and repair execution.

Deployment architecture changes response time
The first deployment choice is usually edge versus cloud. Edge deployment runs analytics on or near the asset. Cloud deployment centralizes processing for broader visibility and heavier compute tasks. Neither is automatically right.
Edge deployment makes sense when latency matters, connectivity is unreliable, or the plant wants local action near the machine. A rapidly changing compressor train or an isolated utility asset may benefit from immediate local detection. Cloud deployment is usually better for fleet-level learning, model management, historical analysis, and cross-site standardization.
The architecture should follow the operational need:
- Use edge processing when the plant needs rapid local screening, resilience during network interruptions, or lightweight anomaly detection close to the equipment.
- Use cloud or centralized processing when the team needs richer historical context, model retraining, fleet comparison, or multi-site reporting.
- Use a hybrid design when local detection must feed broader learning and planning workflows.
A prediction only matters if someone can act on it
Many projects become science exercises because, while the system generates a risk score, no one has defined what score triggers inspection, what score triggers a planned work order, and what score requires immediate review by reliability and operations.
The deployment layer should answer four practical questions:
| Workflow need | What the plant should define |
|---|---|
| Alert trigger | What signal, score, or trend change creates a notification |
| Ownership | Who reviews the alert first, and within what operating rhythm |
| Response path | What inspection or maintenance action follows each alert class |
| Closure feedback | How the actual finding gets written back into the system |
A useful output isn't “Asset risk = 0.83.” A useful output is “Gearbox on filler line shows a rising defect trend consistent with bearing degradation. Inspect during next available window. Verify lubrication condition, bearing housing temperature, and axial vibration.”
That output can then feed a CMMS work order, planner review queue, or exception dashboard. Some plants build this internally. Others use external reliability support where model review and condition interpretation are tied to maintenance execution. In that context, predictive maintenance services from Forge Reliability are one example of a program structure that combines condition monitoring with reliability workflow support.
If the alert doesn't tell a supervisor what to do next, it isn't ready for operations.
Deployment also changes how success is measured. Model accuracy matters, but plant leadership will care more about whether the program changed scheduling quality, reduced emergency work, improved repair timing, and prevented disruptive failures. Those are maintenance workflow outcomes, not just analytics outcomes.
Common Pitfalls in PdM Machine Learning Projects
Most failed programs don't fail because machine learning is impossible in industrial settings. They fail because the plant skips the hard operational disciplines and assumes the model will compensate. It won't.
The pattern behind most failed programs
A common failure pattern starts with broad ambition. The team wants to monitor everything, label everything, and predict every failure mode at once. That usually produces shallow coverage, inconsistent data, and little trust from maintenance crews.
Another frequent mistake is choosing assets by convenience instead of consequence. If the first project targets easy-to-sensor equipment with low downtime impact, the analytics may work but the business case stays weak. Teams then conclude predictive maintenance machine learning is overhyped when the actual issue was asset selection.
The third pitfall is separating the project from maintenance practice. If reliability engineers, planners, and craftspeople aren't involved in failure definitions, alert logic, and closure codes, the project ends up producing technically interesting outputs with no practical response path.
What disciplined teams do differently
The strongest programs usually look narrower at the start and more rigorous in execution.
- They begin with critical assets: High-consequence pumps, compressors, motors, and gearboxes make it easier to justify instrumentation and review effort.
- They define failure modes before analytics: Bearing wear, lubrication failure, looseness, misalignment, cavitation, and gear damage each need different data and different response logic.
- They clean the CMMS language: Work orders need useful closure detail. “Repaired” isn't enough for model feedback.
- They build review ownership: Someone has to decide whether an alert becomes an inspection, a plan, or a monitored exception.
- They protect credibility: Early false alarms can damage confidence fast, so thresholds and review discipline matter.
A plant should trust a smaller set of actionable alerts more than a larger set of unexplained scores.
There's also a cultural issue. Some teams present PdM as if it will replace analyst judgment. That usually creates resistance for good reason. Machine learning should support reliability work, not bypass it. The most successful sites use models to improve prioritization and timing while keeping mechanical diagnosis grounded in known failure behavior.
Programs also stall when they ignore integration effort. It's easier to build a proof of concept than to maintain signal quality, update asset metadata, retrain models after process changes, and keep alert logic aligned with current maintenance practices. A PdM program is an operating capability. It isn't a one-time software install.
Frequently Asked Questions
Which assets should get predictive maintenance machine learning first
Start with assets that combine three things: operational criticality, detectable failure precursors, and a realistic maintenance response window. In most plants, that points to rotating equipment such as critical pumps, motors, fans, compressors, and gearboxes. If a failure happens too quickly to detect or the asset has little production consequence, machine learning usually isn't the first lever to pull.
Do plants need continuous sensors everywhere
No. Many facilities get strong results from a mixed strategy. Route-based monitoring covers a broad population efficiently, while continuous monitoring is reserved for assets where failure develops quickly or downtime cost is severe. The decision should follow asset criticality and failure behavior, not a blanket technology preference.
How much historical data is enough
There isn't a universal threshold. What matters is whether the history includes usable examples of normal operation, changing condition, maintenance intervention, and confirmed fault outcomes. Clean labels and operating context often matter more than raw volume. A smaller, well-structured dataset can outperform a large but poorly coded one.
Who should own the program
Ownership should be shared, but not vague. Reliability engineering usually owns failure logic, data interpretation, and alert governance. Maintenance planning owns workflow response. Operations provides process context and access windows. IT or automation teams support integration and data flow. Programs work better when one accountable leader coordinates those groups instead of assuming the platform will manage itself.
| Question | Answer |
|---|---|
| Which assets should go first? | Critical assets with measurable precursors and meaningful downtime risk |
| Is continuous monitoring always required? | No, many plants use a mix of route-based and continuous strategies |
| Is more data always better? | No, better labels and context often matter more than volume |
| Who owns PdM ML? | Reliability leads the logic, with planning, operations, and technical support aligned |
A predictive maintenance machine learning program only pays off when it connects failure physics, clean data, and maintenance execution. For plants that want help identifying where that connection is strongest, Forge Reliability offers a free reliability assessment to review critical assets, current condition monitoring practices, and the highest-impact opportunities for a practical PdM roadmap.


