
A plant manager usually starts paying attention to asset lifecycle management right after a painful failure. The main process pump trips. The standby unit won't carry full load because its minimum flow line has been sticking for months. Operators start throttling around the problem. Maintenance scrambles for seals, bearings, and labor. Production loses a shift, quality drifts, and the next morning turns into a capital discussion nobody planned to have.
That's the moment asset lifecycle management stops sounding like an administrative term and starts looking like operating discipline. In practice, asset lifecycle management means treating equipment as a managed business system from selection through retirement, not as a purchase that disappears into the plant until it breaks. When teams manage the full life of a motor, pump, compressor, turbine, or packaging line, they gain better control over downtime, maintenance cost, and replacement timing.
The plants that stay stuck in break-fix mode usually know their bad actors by nickname. What they often don't have is a repeatable framework for deciding what to monitor, what to maintain, what to rebuild, and what to replace. That framework is what separates recurring emergencies from defensible reliability decisions.
Table of Contents
- Beyond Break-Fix Mentality
- The Five Stages of the Asset Lifecycle
- Connecting ALM to Modern Reliability Practices
- Your Four-Phase ALM Implementation Roadmap
- Measuring What Matters With ALM KPIs and Dashboards
- Common Pitfalls and Industry-Specific Considerations
- Calculating the ROI of ALM and Planning Your Next Step
Beyond Break-Fix Mentality
It is 2:10 a.m. on a Saturday, and the bottleneck line is down. The main drive motor had been running hot for weeks. Operators heard a rougher start. An electrician kept resetting nuisance trips to protect output. Then the insulation failed during the highest-volume run of the month.
The repair bill is only part of the loss.
Production misses the shift target. Packaging crews wait on product. Maintenance pulls labor off planned work. Expediting starts. Customer orders slip. By the time the motor is back, the plant has spent far more on disruption than on the motor itself. That is the day many sites realize asset lifecycle management is not a paperwork exercise. It is a way to make better operating and capital decisions before a failure forces them.
On the plant floor, ALM is the discipline of managing an asset from selection to retirement with cost, risk, maintainability, and production impact in view at the same time. For a plant manager, that changes the conversation. The question is no longer, "How fast can we fix this?" It becomes, "Should we monitor it, maintain it, rebuild it, redesign it, or replace it, and what does each choice do to cost and uptime over the next few years?"
That is the gap many plants struggle with. Finance talks about lifecycle cost. Reliability teams deal with bearings, seals, overloads, contamination, and misalignment. Good ALM connects those two worlds. A chronic pump seal failure is not only a maintenance issue. It can point to poor duty definition, bad flush arrangement, repeated off-curve operation, or a replacement decision that should have happened a year earlier.
What reactive plants miss
Reactive sites usually manage the event they can see, not the chain of decisions that created it.
- The purchase decision focused on price: The team selected the lowest bid, but ignored accessibility, spare part standardization, motor efficiency, and the cost of repeated callouts.
- The asset operated outside its intended duty: A pump ran near minimum flow, or a conveyor gearbox saw shock loads it was never sized for, and nobody owned the operating limits.
- The maintenance plan did not match the failure mode: Calendar PMs kept firing even when the better answer was condition monitoring, precision maintenance, or a design change.
- The replacement decision came after the plant had no good options left: The site waited for forced outage, premium freight, overtime labor, and collateral production loss.
Practical rule: If lifecycle cost only shows up after a major failure review, the plant is still reacting. It is not controlling the asset lifecycle.
The shift away from break-fix starts with one simple habit. Treat each critical asset as an operating decision with a financial consequence. A chilled water pump affects energy use, process stability, seal inventory, technician time, and future capex. A packaging line servo motor affects throughput, changeover performance, and customer service. A compressor affects the whole plant when pressure dips start tripping valves and starving instruments.
That is why maintenance strategy selection matters so much in ALM. If a failure mode has a detectable warning period, condition-based work often costs less than time-based replacement. If the failure is random and hidden, the right answer may be inspection, protection, or redesign instead. For teams sorting out that line in practical terms, this guide on predictive vs preventive maintenance strategies gives a useful plant-level comparison.
Plants improve ALM when they stop treating maintenance, operations, and capital planning as separate conversations. The best sites make replacement timing, PM scope, spare holdings, and operating discipline part of the same decision. That is how reliability work on the floor turns into lower lifecycle cost on the balance sheet.
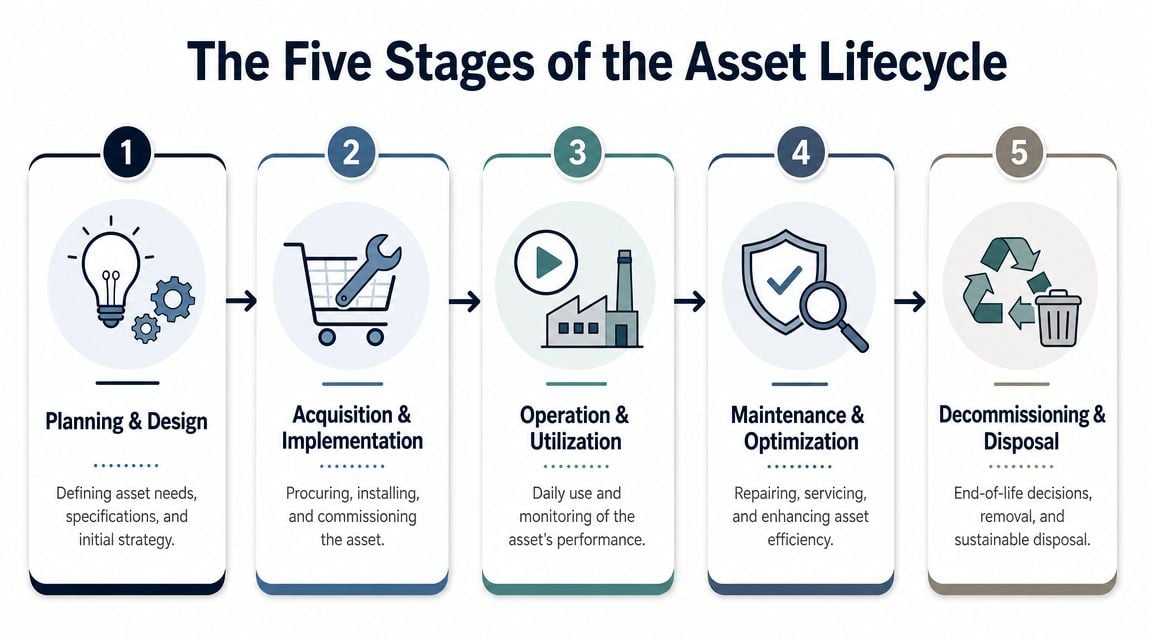
The Five Stages of the Asset Lifecycle
A plant buys a new process pump to solve a capacity problem. Six months later, the seal system is giving trouble, vibration is creeping up, and operators are throttling discharge to keep the process stable. Finance sees rising repair cost. Maintenance sees repeat work. Operations sees lost throughput. The asset did not suddenly become unreliable. The lifecycle was set up poorly from the start.
That is why I split ALM into five stages on the plant floor. The textbook version often combines startup with operation. In practice, commissioning deserves its own stage because many chronic reliability problems begin between installation and handover.
A centrifugal pump in a chemical plant makes the point clearly. It is common equipment, easy to underestimate, and expensive to get wrong.
Planning and acquisition for the right pump
The first stage is planning. During this stage, lifecycle cost starts to move, long before a work order exists.
For a pump, the primary question is not just required flow and head. The vital question is how the pump will live in the system. Suction conditions, fluid temperature, solids content, turndown, seal support, minimum flow exposure, and upset operation all matter. Plants that miss those details often buy a pump that looks acceptable on the datasheet and performs badly in service.
The failure pattern is familiar. Seal failures show up early. Bearings run hotter than expected. Operators compensate with valve positions that were never intended to be normal. Maintenance keeps restoring the asset, but the asset was a poor fit from the day it arrived.
A stronger acquisition process changes the discussion:
| Decision area | Weak approach | Strong ALM approach |
|---|---|---|
| Duty definition | Uses nominal process point only | Reviews full operating envelope, including startup, upset, and low-flow periods |
| Selection basis | Chooses lowest purchase price | Compares repair exposure, energy use, maintainability, and expected service life |
| Spare parts | Waits until first failure | Defines critical spares and lead times before startup |
| Data setup | Stores nameplate only | Builds asset hierarchy, BOM, cost fields, and failure coding before handover |
This stage also decides whether the plant will manage the asset as a financial object or just own it. Teams that want consistency across pumps, compressors, motors, and utilities usually need a formal asset management program for reliability and lifecycle cost control so criticality, CMMS records, spare strategy, and capital planning are working from the same logic.
Commissioning with a usable baseline
Commissioning is the second stage because startup data becomes the reference point for every later decision.
For the centrifugal pump, that means recording baseline vibration, suction and discharge pressure, flow, bearing temperature, motor amperage, alignment condition, lubrication condition, and seal support status while the machine is healthy and operating near intended duty. If the pump is commissioned while recirculating, cavitating, or running off curve, the baseline is already misleading.
A pump with no startup baseline gets judged by memory and opinion.
Good commissioning also checks the basics that often get skipped under schedule pressure. Pipe strain. Rotation. Foundation integrity. Soft foot. Guarding. Instrument scaling. Seal flush arrangement. None of these items are expensive to verify. All of them can create years of unnecessary maintenance if missed.
Operation under real process conditions
Operation is the longest stage, and it is where design assumptions meet plant reality.
Reliability engineers and operators need to work from the same picture. A pump that runs well at one process rate may become unstable at another. A suction source change can alter NPSH margin. A valve lineup change can push the machine toward minimum flow. On paper, the asset is still available. On the floor, it is operating in a way that shortens seal life, raises energy use, and increases the chance of a trip.
The practical question is simple. Is the pump operating where it was intended to operate?
A few checks carry more value than a long generic inspection route:
- Hydraulic behavior: Confirm the pump is not spending extended time near shutoff, minimum flow, or unstable recirculation zones.
- Mechanical condition: Trend vibration by location and direction so the team can separate hydraulic problems from bearing or alignment issues.
- Thermal condition: Watch bearing and seal temperatures for drift, especially after process changes.
- System effects: Verify whether clogged strainers, altered valve positions, or production changes have shifted the duty point.
ALM holds practical implications for the plant manager. Operating discipline affects lifecycle cost just as much as maintenance quality. If operators routinely use a pump far from best efficiency point, the budget will show it later in power draw, repair frequency, and lost production.
Maintenance and renewal decisions
Maintenance is the fourth stage. The job here is to control known failure modes at the lowest practical cost.
For a chemical pump, that usually means condition monitoring for bearings and imbalance, seal system inspections, coupling checks, lubrication control, and motor electrical checks. It also means knowing when not to intervene. Replacing bearings too early can create infant mortality through contamination, poor fit, or installation error. Waiting too long can turn a planned repair into shaft damage, casing damage, or a safety event.
The trade-off is not theoretical. Plants make it every week.
A mature ALM program uses condition, consequence, and repair history together. If the pump has one isolated bearing issue, repair may be the right call. If the same unit has repeated seal failures, poor efficiency, and chronic mismatch to process demand, another rebuild may only preserve a bad decision.
Decommissioning and replacement
The fifth stage is decommissioning or disposal, a process by which plants either remove chronic cost from the system or keep funding it.
Replacement should not be triggered by age alone. It should be triggered when the asset no longer fits the duty, no longer meets risk tolerance, or consumes more money and production time than a replacement would. For pumps, that case often becomes clear after repeated repairs, declining hydraulic performance, obsolete parts, or process changes that made the original selection wrong.
A useful review at this stage asks four direct questions:
- Is the asset still the right machine for the current duty?
- Does the next repair restore reliable service or repeat the same failure pattern?
- Has continued operation crossed an acceptable risk threshold for production, safety, or environmental exposure?
- Will replacement remove a recurring operating constraint?
Those questions bridge ALM theory and daily reliability work. They turn lifecycle cost from a spreadsheet term into specific decisions about PM scope, condition monitoring, repair limits, spare holdings, and replacement timing. That is what plant teams need. Not a model on the wall. A way to make better calls on real equipment.
Connecting ALM to Modern Reliability Practices
Asset lifecycle management becomes useful when reliability methods are tied directly to each lifecycle decision. Otherwise, ALM stays at the level of policy language while the plant continues to fight the same failures.
A fleet of rooftop air handlers shows this clearly. On paper, they're simple assets. In practice, they fail in ways that affect comfort, product quality, electrical load, filtration performance, and sometimes regulatory exposure. Bearings degrade, belts loosen, coils foul, dampers stick, and motors overheat. The lifecycle strategy improves only when those failure modes are connected to the right reliability tools.

Planning with failure modes in mind
The planning stage should include a failure mode review. In practical terms, that means asking what can fail, how it fails, what the plant would notice first, and what consequence follows. This is the logic behind failure mode and effects analysis, or FMEA, which is a structured method for identifying likely failure paths and their operational impact.
For rooftop air handlers, that exercise often surfaces issues that generic PM programs miss:
- Belt drive problems: Misalignment, tension loss, and sheave wear create vibration and airflow drift.
- Bearing distress: Lubrication problems and contamination cause rising vibration and heat.
- Damper failures: Actuator or linkage issues disrupt control stability.
- Motor electrical defects: Connection problems and insulation weakness raise heat and current imbalance.
- Coil fouling: Reduced heat transfer forces the unit to work harder and can affect downstream conditions.
From there, reliability-centered maintenance, or RCM, determines what maintenance task makes sense. Some failure modes justify condition monitoring. Some need a scheduled restoration. Some call for operator checks. Some are better addressed by redesign.
Teams formalizing this logic across the plant often use a broader reliability-centered maintenance implementation guide to keep the analysis from turning into a one-time workshop with no field impact.
Using condition data to control intervention timing
For industrial operations, lifecycle management becomes a financial and reliability optimization problem. Enterprise asset management and maintenance systems centralize lifecycle data so teams can make condition-informed decisions, and predictive maintenance uses real-time sensor data and AI or ML models to detect degradation before failure, allowing teams to extend useful life when data supports it or replace early when risk crosses a threshold, as outlined in this discussion of asset lifecycle management best practices.
That matters because modern reliability work is really about timing. The team doesn't win by doing more maintenance. It wins by intervening at the right point in the degradation curve.
For an air handler fleet, the practical pairing looks like this:
| Reliability method | What it does in ALM | Example |
|---|---|---|
| FMEA | Defines likely failure modes | Identifies bearing contamination as a recurring risk |
| RCM | Chooses the right maintenance task | Assigns vibration checks instead of arbitrary bearing replacement |
| Predictive monitoring | Detects change before functional failure | Flags rising vibration on a supply fan bearing |
| Root cause analysis | Prevents recurrence | Finds that ingress from poor sealing drove the repeated defect |
Condition data should change a work order decision. If it doesn't, the site is collecting signals without running a reliability program.
ALM transcends its role as a finance concept to become a field decision model. The planner sees whether to kit a repair or hold. The supervisor sees whether the machine can survive to the next window. The plant manager sees whether repeated interventions justify redesign or replacement.
Your Four-Phase ALM Implementation Roadmap
Most sites don't need a massive reset. They need an orderly path from scattered asset records and reactive work to a usable lifecycle program. A four-phase roadmap works because it lets one plant pilot the model before a multi-site company tries to standardize it everywhere.
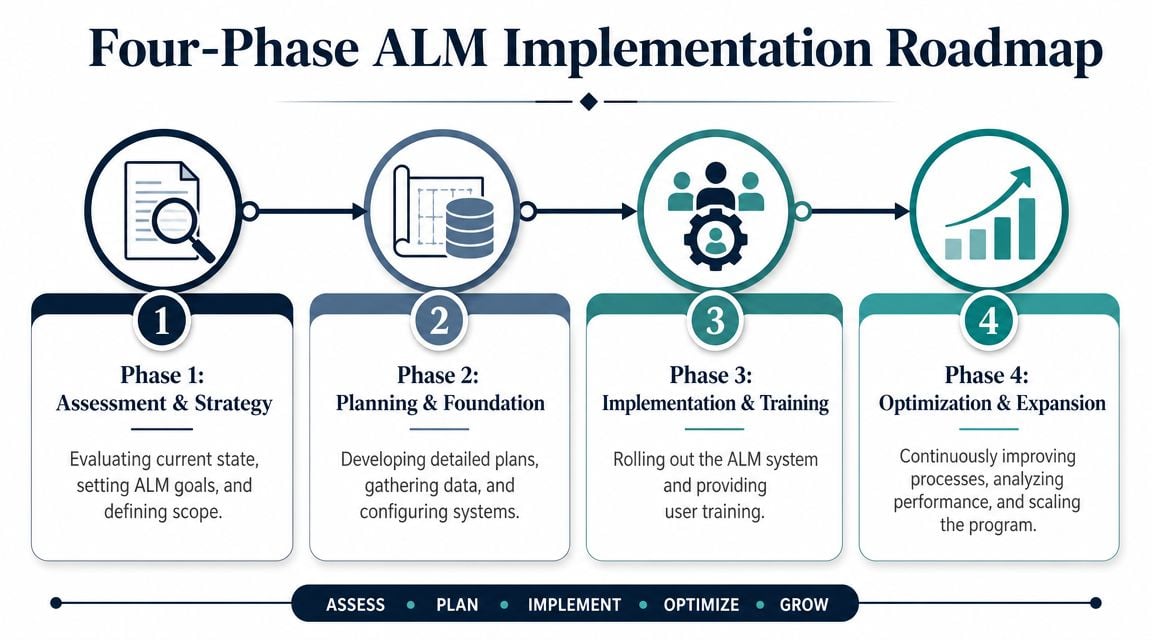
Phase 1 and Phase 2 build control
Phase 1 is foundation. In this phase, the team cleans up the asset hierarchy, confirms naming standards, identifies critical assets, and fixes missing ownership. A program can't manage lifecycle cost or maintenance history if the same pump appears under three names and two locations.
A technically effective asset lifecycle management program depends on maintaining a single, authoritative asset record across request, provisioning, operations, maintenance, and retirement. When governance fields such as owner, lifecycle status, and cost center drift between systems, workflows break down and audit gaps appear, as described in this discussion of authoritative asset records and governance fields.
For an industrial site, the same principle applies inside the maintenance system:
- Asset hierarchy: Each motor, pump, gearbox, and driven system needs a clear parent-child structure.
- Ownership: Someone must own the record, not just the machine.
- Status control: In-service, standby, mothballed, and retired assets need distinct lifecycle states.
- Cost integrity: Labor, parts, and outside service costs must land on the right asset.
Phase 2 is standardization. Once the records are trustworthy enough, the site defines standard job plans, failure codes, work order closeout rules, and baseline KPIs. This is also where many sites discover how inconsistent technician feedback has been. “Repaired pump” tells leadership almost nothing. “Replaced inboard bearing after high vibration and confirmed soft foot correction” is useful.
A practical 12-month reliability program roadmap can help sequence this work so the site doesn't try to launch advanced monitoring before the underlying records are stable.
Phase 3 and Phase 4 make the program useful
Phase 3 is optimization. In this phase, predictive methods and mobile execution start to matter. The plant adds route-based condition monitoring on critical assets, improves planning and scheduling discipline, and uses alarms or inspections to trigger more precise work.
A pilot plant often starts with a focused asset class such as:
- Process pumps with repeated seal and bearing issues
- Compressors with high downtime consequence
- Large motors driving bottleneck equipment
- Utility systems that create plant-wide disruption when they fail
Phase 4 is continuous improvement. At this point, the team should be reviewing trends, not just events. Which assets are consuming the most labor? Which failures repeat despite PM compliance? Which replacements are being deferred without technical justification? In this phase, root cause analysis, interval optimization, and capital planning need to connect.
The roadmap only works when each phase produces a usable output. Clean records, standard job plans, condition routes, and capital triggers are all deliverables, not side benefits.
A multi-site manufacturer should resist the urge to standardize everything at once. One plant with disciplined records and a repeatable decision process teaches more than a corporate template rolled out into bad data.
Measuring What Matters With ALM KPIs and Dashboards
Most plants already have metrics. The problem is that many dashboards mix activity, reliability, and finance without showing cause and effect. Asset lifecycle management works better when the dashboard tells a decision story. What is drifting, why it matters, and what action should follow.
In a power generation setting, that story might start with a steam turbine or large motor-driven auxiliary system. The plant manager doesn't just need to know that vibration increased. The manager needs to see whether the change affects availability risk, maintenance scope, and operating cost.

Leading indicators that show whether control exists
Leading indicators show whether the site is doing the work that prevents future failure. They don't prove success on their own, but they reveal whether the process is under control.
Key ALM leading indicators often include:
- Planned maintenance percentage: Shows how much work is planned instead of reactive.
- Schedule compliance: Indicates whether the weekly schedule is realistic and protected.
- Condition route completion: Confirms whether inspections and data collection are completed.
- Asset utilization rate: Helps identify overused, underused, or badly matched equipment.
- Compliance rate: Matters in regulated environments where records are part of operational risk.
A useful dashboard separates these from lagging results. If a site reports poor MTBF and high emergency work, the first question should be whether the plant is executing planned work consistently and collecting reliable condition data.
Lagging and financial indicators that shape capital decisions
Lagging indicators report what already happened. They still matter because they show whether the maintenance strategy is producing reliability.
The common ones are well known, but they need interpretation:
| Metric | What it means | Common misuse |
|---|---|---|
| MTBF | Average operating time between failures | Used without defining what counts as a failure |
| MTTR | Average time to restore function | Treated as a technician-only issue when spares and planning often dominate |
| MTTF | Average time to failure for non-repairable items | Applied loosely to repairable systems |
| Uptime vs downtime | Availability view of asset performance | Reported at plant level without isolating critical assets |
| Total asset lifecycle cost | Full ownership view across life stages | Reduced to maintenance spend only |
The strongest ALM dashboards also bring in financial context. A turbine with rising maintenance cost may still be worth keeping if condition and duty remain acceptable. A smaller auxiliary pump may deserve replacement sooner if repeat failures cause disproportionate process loss, cleanup labor, or quality impact.
For teams that need a sharper handle on how reliability metrics should be used, this guide to MTBF, MTTR, and OEE is a practical companion to lifecycle decision-making.
A dashboard should help the plant answer one question quickly. Keep running, repair at the next window, redesign, or replace.
When that answer isn't visible, the site usually has data without management logic.
Common Pitfalls and Industry-Specific Considerations
Most ALM failures aren't caused by lack of software or lack of effort. They fail because the plant tries to manage lifecycle decisions on top of bad records, unclear ownership, and a culture that still rewards emergency response over prevention.
Where ALM programs usually fail
The first problem is poor data discipline. If the CMMS record doesn't match the machine in the field, every downstream decision gets weaker. Spare parts planning suffers. Failure history becomes unreliable. Labor and material cost attach to the wrong asset. By the time leadership asks whether an asset should be rebuilt or replaced, the record can't defend either choice.
The second problem is cultural. Plants often say they want proactive maintenance, but supervisors still praise heroic repairs more than planned execution. That creates a hidden incentive to stay reactive.
The third problem is communication with leadership. Maintenance teams frequently explain ALM in maintenance language, not operating or financial language. Plant leaders need to hear how the strategy reduces forced outages, stabilizes throughput, protects compliance, and improves capital timing.
A broader market signal explains why this topic keeps gaining attention. In a 2022 IDC survey, 51% of respondents said increasing operational efficiency was their top priority, and that helps explain investment in ALM approaches that combine IoT and AI to use real-time asset performance data and intervene before failure, according to this IBM summary of asset lifecycle management trends.
How industry context changes the maintenance decision
The framework is the same across industries. The failure consequences are not.
- Pharmaceutical manufacturing: Documentation, validation, and change control heavily influence lifecycle decisions. A mechanically simple replacement can become a major event if the asset touches validated process conditions or product quality.
- Oil and gas: Asset integrity, corrosion, containment, and safety consequence drive the strategy. A pump or exchanger may remain mechanically operable while still becoming unacceptable from a risk standpoint.
- Food and beverage: Sanitary design, washdown exposure, and rapid changeovers matter. Bearings, seals, and motors often fail because the environment is harsher than the original selection assumed.
- Power generation: Availability risk is tied directly to dispatch readiness and maintenance windows. Small degradations in rotating equipment can have outsized operational effect.
- Water and wastewater: Duty variability, ragging, corrosion, and standby readiness shape the lifecycle decision more than simple runtime hours.
The right maintenance strategy depends less on the asset type than on the failure consequence in that industry.
A hygienic pump in a food plant and a transfer pump in a chemical plant may look similar on a P&ID. They do not live under the same constraints. That's why strong asset lifecycle management never copies PM templates from one business unit to another without checking process reality first.
Calculating the ROI of ALM and Planning Your Next Step
A plant usually sees the value of asset lifecycle management on a bad day. A boiler feed pump trips, production stops, operations wants a restart estimate, maintenance is hunting for parts, and finance is asking why the same asset has consumed labor and spares for two years without a clear replacement plan. ALM improves that moment before it happens. It gives the plant a basis for deciding when to maintain, when to rebuild, and when to replace, using cost and consequence instead of habit.
Where the return comes from
The first return comes from avoiding expensive downtime and controlling the scope of repairs. If vibration or oil analysis catches bearing damage early on a critical motor, the team can schedule the outage, stage the correct parts, and inspect the coupling, base, and lubrication system before a small defect turns into a rotor failure. That lowers overtime, reduces secondary damage, and makes startup more stable.
The second return comes from better repair-versus-replace decisions. Reliability teams make these calls every week on pumps, gearboxes, air compressors, and heat exchangers. Without lifecycle cost visibility, plants tend to swing between two bad choices. They keep rebuilding an asset that has become a chronic bad actor, or they replace equipment too early because no one trusts the maintenance history. ALM puts a financial frame around the decision by combining failure history, condition trend, spare parts usage, labor burden, and production consequence.
Capital planning improves too.
Many sites spend money in the wrong sequence. They pour maintenance hours into low-consequence equipment while a production-critical asset runs with known repeat failures and no replacement plan. A structured ALM approach helps plant leaders rank investments by business impact, not by who complained last week or which asset failed most recently.
Digital maturity affects how fast those decisions improve. Leaders looking at broader AI transformation impacts will see the same pattern inside reliability work. Better data collection matters when it leads to better work selection, tighter outage planning, and clearer replacement timing for assets that drive cost and uptime.
A practical next move for plant leaders
Start with one asset class that causes repeated operational pain. Pick something tangible, such as process pumps in a corrosive service, conveyor gearboxes in a dusty area, or fan motors exposed to washdown. Then trace the full lifecycle story from purchase decision to failure mode to maintenance cost to production consequence.
A useful first pass looks like this:
- Identify the assets driving the most lost production, repeat callouts, or maintenance spend.
- Confirm that the asset hierarchy, failure codes, and work history in the CMMS are reliable enough to support a decision.
- Review how those assets fail in the field, not how the PM says they should fail.
- Compare the current maintenance strategy with the actual failure pattern and operating context.
- Set clear trigger points for overhaul, redesign, or replacement based on cost and risk.
Many plants encounter the core problem. The issue is not just a bad pump, a weak motor, or an aging compressor. The issue is a repeated pattern of poor lifecycle decisions around that equipment.
A free reliability assessment from Forge Reliability gives plant teams a practical starting point. It helps identify critical assets, recurring failure modes, condition monitoring opportunities, CMMS data gaps, and repair-versus-replace decisions that are leaving uptime and money on the table.


