A new plant manager usually meets gas turbine maintenance at the worst possible moment. The unit is due for an outage, operations wants every available megawatt, maintenance wants parts approved before lead times become a problem, and finance wants to know whether the next intervention is necessary. This is the core task. Not building a prettier checklist, but deciding which work protects availability and which work only adds cost.
Gas turbines punish vague maintenance strategy. A machine that runs clean and steady can stay predictable for a long time. The same frame under frequent starts, ambient swings, fuel variability, and rushed shutdowns can consume life much faster. That's why smart gas turbine maintenance starts with an economic question: what failure is most likely, what would it do to production, and what is the lowest-risk way to catch it before it becomes a forced outage?
Table of Contents
- The High Stakes of Gas Turbine Maintenance
- Decoding Common Gas Turbine Failure Modes
- Choosing Your Maintenance Strategy with RCM and FMEA
- Essential Condition Monitoring Techniques in Practice
- Planning Major Inspections and Overhauls
- Post-Outage Troubleshooting and Performance KPIs
- Partnering for Peak Turbine Reliability
The High Stakes of Gas Turbine Maintenance
A combined heat and power plant, a pipeline compressor station, and a peaking power unit can all own gas turbines. Their maintenance decisions look different on paper, but the pressure is the same. Every outage decision affects output, staffing, spare parts exposure, and confidence in the next start.
That's one reason the market around turbine service keeps expanding. A 2025 estimate values the global industrial gas turbine maintenance and repair service market at USD 727 million, with projections to reach USD 911 million by 2034, while broader data place the global gas turbine service market at $19.6 billion in 2021 with a projection of $32.1 billion by 2031. Maintenance isn't a back-end support task anymore. It sits in the middle of operating cost, asset risk, and production planning.
For a new plant manager, the first trap is treating every turbine decision as a choice between “run” or “repair.” Most of the time, the more accurate choice is between different levels of intervention. Should the team keep monitoring a vibration trend and wait for the next planned outage? Should the unit come down early for a focused inspection? Should the plant combine several tasks into one larger event because the startup risk from repeated openings is worse than the extra scope?
Practical rule: The cheapest outage on paper often becomes the most expensive outage if it leaves the underlying failure mode in place.
A simple example comes from a cogeneration site with one gas turbine carrying both electrical and steam obligations. The machine developed subtle signs of compressor performance loss and higher operator attention during starts. A checklist-only program would have split the issue into separate work orders. A reliability-focused program treats the turbine as a business-critical system and asks harder questions:
- What's the production consequence? Lost electrical output may be tolerable. Lost process steam may not be.
- What's the failure path? Fouling, combustion instability, and hot section stress don't stay isolated for long.
- What's the timing risk? Deferring work can be sensible. Deferring blind is not.
- What's the outage package? Combining inspection, verification, and known corrections often beats repeated small interruptions.
That shift in thinking matters more than any individual maintenance task. Good gas turbine maintenance doesn't try to eliminate spending. It tries to place spending where it protects availability, avoids repeat work, and preserves component life.
Decoding Common Gas Turbine Failure Modes
A gas turbine almost never goes from healthy to failed in one shift. What hurts plants is slower degradation that gets misread as a nuisance issue, normal aging, or a problem that can wait until the next outage. That mistake is expensive because the failure mode often starts in one subsystem and gets paid for somewhere else, through lost output, higher heat rate, emissions instability, or a forced outage that arrives before the budget is ready.

Repeated defects after a "successful" outage usually point to weak failure elimination, poor scoping, or both. In those cases, the plant needs a stronger process such as gas turbine root cause analysis so the team corrects the mechanism, not just the damaged part.
Compressor and inlet losses
Compressor problems usually show up first as a business issue, not a mechanical one. The plant sees reduced megawatt output, higher exhaust temperatures, rougher starts, or less operating margin on hot days. By the time someone confirms fouling, erosion, or inlet restriction, the unit has often been burning more fuel for the same work for weeks.
Fouling comes from airborne contaminants, process carryover, moisture, and weak inlet housekeeping. Erosion and blade damage come from particle ingestion and long exposure. These defects do not need to look severe to be costly. A thin layer of deposits can cut airflow enough to shift combustion behavior and raise thermal stress downstream.
The maintenance decision is not limited to "wash or do nothing." Online washing may recover some performance with little interruption, but it will not solve hard deposits, inlet sealing problems, or erosion. Offline cleaning gives better access and recovery, but it consumes outage time and labor. The right choice depends on what the lost output is worth, how quickly degradation is progressing, and whether the compressor issue is isolated or already affecting combustor tuning and turbine temperatures.
Useful field checks include:
- Inlet filter differential pressure: Higher restriction reduces available airflow and can look like a general efficiency problem.
- Compressor wash history: Extended intervals without a condition-based reason usually mean the plant is accepting hidden performance loss.
- Borescope or visual inspection findings: Deposits, erosion, and foreign object damage change the economic case for early intervention.
Combustion distress and fuel-side issues
Combustion problems create some of the worst cost surprises in turbine maintenance because they often begin as manageable operating deviations. Fuel nozzle fouling, liner cracking, hot spots, transition piece distortion, and ignition or flame detection issues may first appear as temperature spread, tuning drift, startup difficulty, or emissions excursions.
Those symptoms matter because combustor distress rarely stays local. Poor fuel distribution and unstable flame patterns increase thermal loading on parts that are already life-limited. If the plant keeps replacing nozzles or patching liners without addressing fuel quality, operating profile, or prior tuning changes, the same distress pattern returns and usually takes more hardware with it on the next cycle.
Plant context matters. A cycling unit with frequent starts consumes combustor hardware differently than a steady baseload machine. A dual-fuel unit can develop repeatable issues on one fuel and look healthy on the other. Maintenance planning improves when the team asks a harder question than "what failed?" Ask what operating condition made that failure economical to expect.
A combustor defect left in service too long often returns as a hotter, more expensive hot section problem.
Hot gas path damage and rotating risk
Delayed decisions cost the most in the hot gas path. Blade and nozzle erosion, cracking, coating loss, creep, tip-clearance growth, and thermal fatigue all begin as life-consumption issues. If they continue unchecked, they become reliability and safety issues, and the repair scope usually expands with them.
Operators may first notice higher exhaust temperature spread, lower efficiency, or a unit that no longer carries load the way it used to. Inspection teams may then find that the machine has been consuming component life faster than the operating plan assumed. Guidance from the Electric Power Research Institute on gas turbine maintenance and inspection practices supports focused attention on compressor condition, combustion hardware, turbine hot section parts, and support systems because degradation in those areas drives both performance loss and outage risk (EPRI gas turbine maintenance guidance).
Bearing and lube system defects follow a similar pattern, but they move faster once the condition turns. Vibration changes, rising bearing temperatures, contamination, varnish, or lubrication breakdown can push a machine from watchlist to immediate outage in short order. The financial trade-off is straightforward. Early correction usually means targeted work and controlled downtime. Late correction often means collateral damage, schedule disruption, and a much larger parts bill.
A practical way to classify what you are seeing is to tie each failure mode to the first consequence the plant can feel:
| Area | Typical failure mode | What the plant usually notices first |
|---|---|---|
| Compressor | Fouling, erosion, blade damage | Lost output, reduced efficiency, harder starts |
| Combustion | Nozzle fouling, liner cracking, hot spots | Temperature spread, unstable operation, emissions concern |
| Hot gas path and rotor support | Coating loss, creep, cracking, bearing distress | Vibration change, thermal behavior shift, outage findings |
Good failure-mode analysis does more than support inspection planning. It helps the plant decide whether to keep running, clean, tune, inspect early, or bundle work into the next outage. That is the difference between maintenance that spends money and maintenance that protects margin.
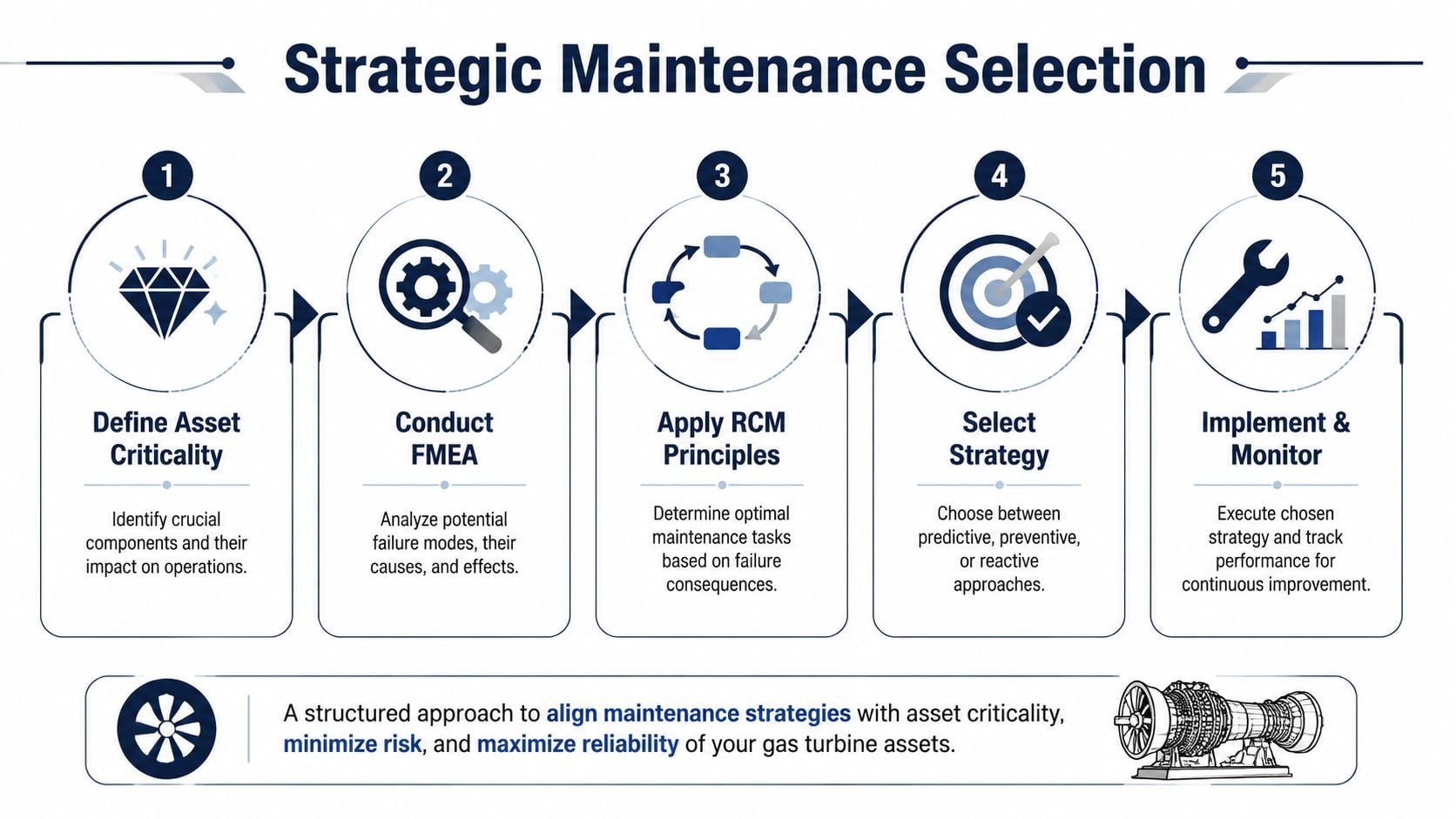
Choosing Your Maintenance Strategy with RCM and FMEA
Most turbine programs become expensive for one reason. They confuse activity with strategy. A plant can complete every scheduled task and still make poor maintenance decisions if the schedule doesn't reflect how the unit consumes life.
Why calendar-based plans miss the real wear mechanism
Gas turbine maintenance is usually organized around factored first starts (FFS) and factored fired hours (FFH), not simple calendar time. FFS reflects start-stop fatigue damage. FFH reflects cumulative thermal exposure during operation. Units that cycle often can reach inspection thresholds much faster than baseload units, which is why a one-size-fits-all interval is technically weak and economically inefficient (FFS and FFH guidance for interval planning).
That distinction matters immediately for a new plant manager. Two turbines can show similar annual run hours while consuming component life very differently. One may need routine inspection and standard service planning. The other may need earlier combustion or hot section attention because starts, load swings, ambient conditions, and firing profile are harder on parts than the calendar suggests.
Plants often miss money in both directions:
- They intervene too early on healthy components because the calendar says it's time.
- They intervene too late on stressed components because runtime alone looks acceptable.
- They mis-scope outages because they don't connect observed condition to likely failure consequence.
How RCM and FMEA change the decision
Reliability-Centered Maintenance (RCM) asks what function the asset must perform, how it can fail, what happens when it fails, and what maintenance task prevents or mitigates that consequence. Failure Modes and Effects Analysis (FMEA) forces the team to document the failure mode, cause, local effect, system effect, and required action.
That discipline changes outage planning from habit to logic.
A peaking power unit is a good example. Frequent starts make combustion and thermal fatigue concerns more important than they would be on a similar baseload machine. An FMEA on that asset may show that not every detected issue deserves immediate invasive work. Some conditions justify online monitoring and tighter review. Others demand an earlier outage because the consequence is a trip, secondary damage, or restart unreliability.
A practical RCM and FMEA screen for gas turbine maintenance should answer these questions:
- What function must the turbine perform? Baseload power, peaking support, process steam support, mechanical drive, or some mix.
- Which failure modes threaten that function first? Compressor fouling, combustion distress, hot gas path cracking, lube contamination, coupling misalignment, controls issues.
- Can the failure be predicted? If yes, condition monitoring should drive timing.
- What's the consequence of getting the timing wrong? Lost output is one consequence. Secondary damage is another.
- What task is justified? Inspection, online monitoring, redesign, operating change, or planned replacement.
Field judgment: The right maintenance strategy isn't the most conservative one. It's the one that reduces consequence at the lowest total lifecycle cost.
For plants that need help building that logic, RCM services for critical assets can structure the decision around actual failure consequences and operating duty. Forge Reliability provides that type of support for industrial assets using RCM, FMEA, and condition-based planning.
Essential Condition Monitoring Techniques in Practice
A plant manager usually sees the problem after production does. Heat rate drifts. Starts get less predictable. An operator mentions a new vibration pattern that does not quite cross an alarm. By then, the question is not which inspection method exists. The question is which signal gives enough confidence to act early, avoid secondary damage, and stay out of an unnecessary outage.
That is why condition monitoring has to be tied to economics, not just instrumentation. A useful program does not try to collect every possible data point. It focuses on the failure modes that can force lost generation, expand repair scope, or shorten the next run cycle. For gas turbines, that usually means watching the compressor and inlet section, combustor, hot gas path, and bearing and lube systems with methods that can separate routine degradation from action-worthy risk.
What to watch first
Start with the components where timing matters most.
If bearing distress is developing, waiting for an operator round to catch it is a poor bet. In many cases, oil results show contamination, viscosity change, or wear debris before vibration reaches a clear alarm state. If combustion hardware is degrading, a borescope often gives better decision quality than broad operating data alone because it shows whether the unit can safely run to the next planned stop or needs earlier intervention. Each method answers a different question, and the cost of choosing the wrong one is real.
The main techniques used in practice include:
- Vibration analysis: Best for imbalance, misalignment, looseness, bearing defects, and some rotor-related issues. Trend quality matters as much as the absolute reading. A startup spectrum that shifts from the established baseline after maintenance deserves review before the team accepts it as the new normal.
- Oil analysis: Useful for contamination, lubricant breakdown, and early internal wear. This method often gives the earliest warning on bearing and lube system problems, which makes it valuable when the goal is to plan a repair before debris causes wider damage.
- Thermography: Helpful for abnormal surface temperatures, support system issues, and thermal imbalance around auxiliaries and associated equipment. It is usually more useful on accessible supporting systems than on internal turbine components.
- Borescope inspection: Used to verify cracking, erosion, coating loss, fouling, and clearance-related concerns in the combustor and hot gas path without opening the machine. It is often the fastest way to confirm whether a suspected problem is cosmetic, manageable, or outage-defining.
- Motor current signature analysis: More relevant for electrically driven auxiliaries than for the turbine core itself, but still useful where motor-driven lubrication, cooling, or support systems can become the main source of unreliability.
Relying on vibration alone leaves blind spots. A turbine can carry acceptable overall vibration while oil condition worsens, deposits build, or combustion hardware starts to deteriorate in ways that only visual inspection will confirm.
Plants that want a disciplined framework can use condition monitoring for gas turbines to decide where continuous monitoring, route-based data collection, and outage inspections each provide enough value to justify the effort.
How the main techniques differ
The methods are not interchangeable. Each has a different labor burden, detection window, and decision value.
| Technique | Primary Failures Detected | Implementation Complexity | Best Application |
|---|---|---|---|
| Vibration analysis | Imbalance, misalignment, looseness, bearing distress, rotor-related problems | Medium to high | Rotating condition trending before and after maintenance |
| Oil analysis | Wear debris, contamination, lubricant degradation | Medium | Bearing and lube system health, early wear detection |
| Thermography | Abnormal temperature patterns, hot spots, thermal imbalance in accessible areas | Medium | Auxiliary systems and follow-up on suspected thermal issues |
| Borescope inspection | Cracking, erosion, coating loss, fouling, tip-clearance concerns | Medium to high | Combustor and hot gas path assessment without full teardown |
| Motor current signature analysis | Electrical and load-related anomalies in motor-driven auxiliaries | Medium | Supporting motor systems tied to turbine reliability |
In practice, the trade-off is simple. Continuous systems can catch change sooner, but they cost more to install, maintain, and interpret. Route-based collection is cheaper, but it can miss fast-moving failures or transient behavior during starts and load changes. Outage inspections give high-confidence evidence, but only after the unit is already offline. Good programs mix these methods based on consequence. High-consequence failure modes get earlier and more frequent visibility. Lower-consequence modes can tolerate slower detection.
A few rules keep the program useful:
- Build a real baseline before maintenance work. Post-outage readings have limited value if no one captured what healthy looked like under comparable load and ambient conditions.
- Link each alarm or trend change to a decision. The team should know whether a deviation means monitor more closely, inspect at the next stop, reduce load, or pull scope into an earlier outage.
- Use multiple indicators before making expensive calls. A borescope finding supported by vibration change and oil contamination is a stronger basis for action than any single signal by itself.
- Keep operating context in the review. Start frequency, fuel quality, ambient swings, water wash effectiveness, and recent maintenance all affect what normal looks like.
The strongest monitoring programs help plants spend outage dollars where risk is highest, and avoid tearing into machines that can still run safely to a better planning window. That is the point. Better timing, fewer forced events, and lower total maintenance cost.
Planning Major Inspections and Overhauls
Outage planning fails when teams treat scope as a shopping list. A major turbine event should be planned as a risk-control exercise. Every task needs a reason, every spare needs a lead-time owner, and every inspection finding needs a path back into the maintenance strategy.
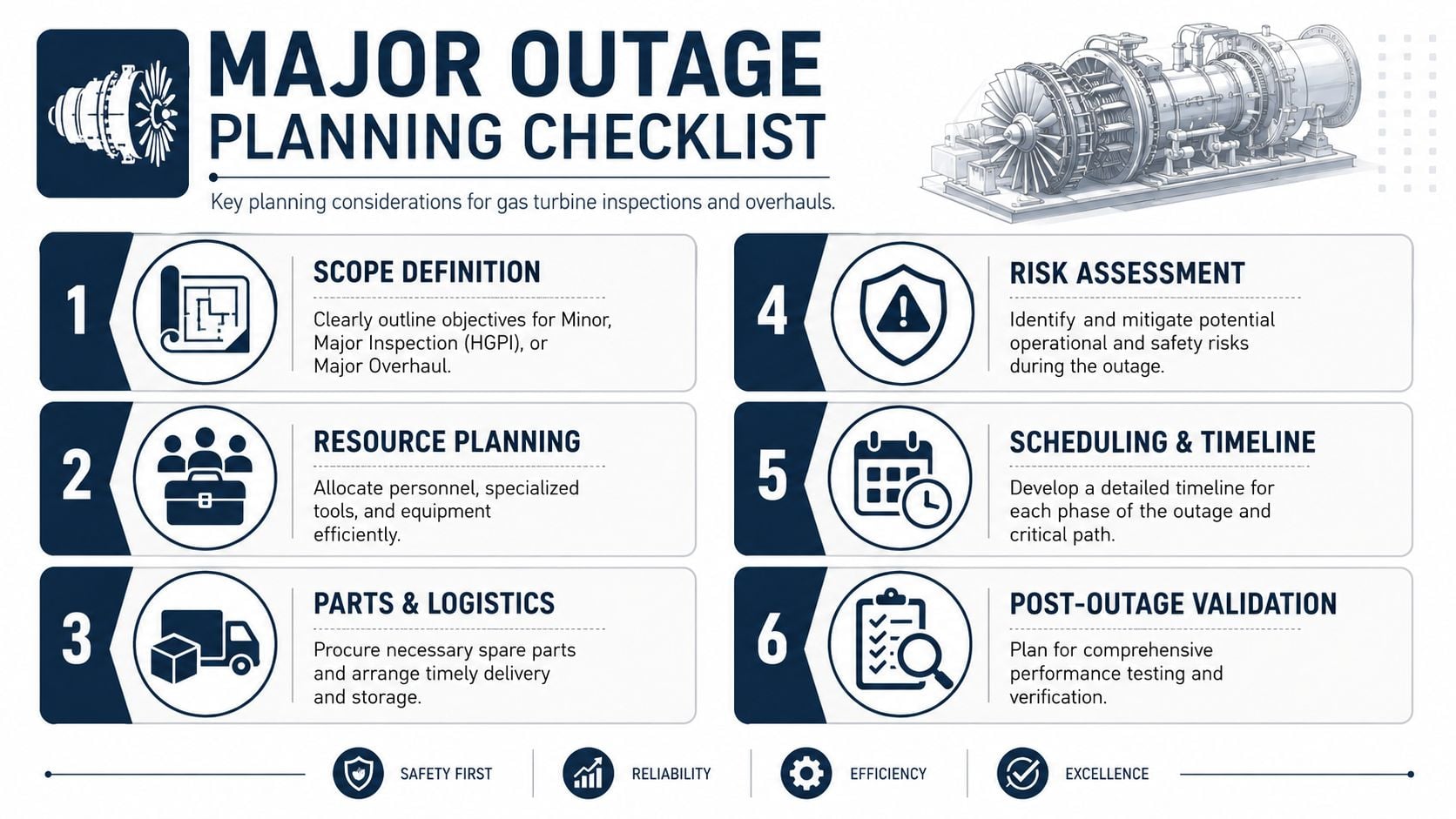
The installed base itself explains why outage planning has become more complicated. In the gas-fired fleet, about 77 GW of capacity was over 50 years old as of 2020, while more than 672 GW of operating gas turbine installed capacity was less than 10 years old. The same market view notes that maintenance is the largest segment in the gas turbine MRO market, holding roughly 45% of total market share in 2024. Younger units need disciplined planned inspections. Older units drive heavier repair, refurbishment, and overhaul demand.
What each outage type is really for
Three planned inspection categories matter most in practice.
- Combustion inspection: Focuses on components such as fuel nozzles, liners, crossfire tubes, and transition pieces. Plants use this event to catch fuel-side and combustor distress before it becomes broader turbine damage.
- Hot gas path inspection: Extends into blades, nozzles, and shrouds. Life consumption, coating condition, and thermal damage in these areas start driving major cost decisions.
- Major inspection: Involves deeper disassembly including compressor and rotor components. This is less about routine access and more about resetting confidence in the machine's structural and rotating integrity.
A pulp and paper cogeneration plant illustrates the difference. On an older unit, a hot gas path inspection may uncover enough distress that the actual decision is no longer “repair or not.” It becomes “refurbish this package, replace selected components, or reconsider long-term asset strategy.” That's a lifecycle question, not just an outage question.
Planning choices that lower outage risk
The most effective outage plans usually include these elements:
- Scope discipline: Separate mandatory work from desirable work. If the plant can't explain why a task belongs in the outage, it shouldn't consume critical path time.
- Parts strategy: Long-lead components and consumables should be reviewed against actual condition findings from prior outages, not broad assumptions.
- Inspection hold points: The team needs predefined decision gates for accept, repair, refurbish, or escalate.
- Quality checks during assembly: Torque verification, alignment checks, cleanliness controls, and configuration confirmation are where many “new” failures are created.
- Return-to-service planning: Startup procedures, alarm review, and post-outage monitoring should be written before the outage starts.
Plants managing these events often benefit from a structured gas turbine maintenance planning approach that ties outage scope to reliability consequence, not just OEM interval language.
Older turbines usually don't fail because the plant skipped one task. They fail because the plant made overhaul decisions without a clear view of residual life, parts condition, and post-outage risk.
Post-Outage Troubleshooting and Performance KPIs
Many plants still behave as if outage completion equals problem solved. It doesn't. The machine isn't healthy because the work order is closed. It's healthy when startup, loading, vibration response, thermal behavior, and early operating trends confirm that the intervention successfully removed the failure mechanism.

A common gap in turbine programs is the lack of a post-work verification strategy that answers a simple question: how does the plant prove the turbine is healthy after maintenance? That gap matters because recurring failures and maintenance-induced downtime often begin there, especially after complex coupling and alignment work (post-maintenance verification concerns in gas turbine service).
Proving the machine is healthy after the work
A food and beverage cogeneration site can have the same post-outage problem as a utility plant. The turbine starts, loads, and then shows a recurring vibration issue that wasn't present before shutdown. The root cause often isn't exotic. It's missed verification.
A useful acceptance workflow includes:
- Baseline comparison: Compare startup spectra and temperature behavior to the last known healthy condition.
- Mechanical checks: Confirm alignment, coupling runout, soft foot, fastener condition, and foundation behavior where relevant.
- Early trend capture: Watch the first operating period closely instead of assuming normal load means normal condition.
- Alarm review: Distinguish nuisance settings from real deterioration, but don't suppress alarms to make the startup look cleaner.
Healthy after outage means verified, not assumed.
KPIs that matter after startup
A turbine reliability program needs a small set of KPIs that maintenance and operations both trust. Availability, start reliability, repeat defect rate, forced outage frequency, and post-outage defect recurrence are more useful than long dashboards full of weak indicators.
Teams that need a simple refresher on mastering key performance indicators may find it helpful to revisit how KPIs should connect to decision-making rather than reporting.
The key is using KPIs to expose maintenance quality, not just equipment status. If the turbine repeatedly develops the same startup vibration after every outage, the KPI problem isn't availability alone. It's workmanship, verification, or scope control. Once the team sees that pattern clearly, troubleshooting becomes much faster and far less political.
Partnering for Peak Turbine Reliability
Strong gas turbine maintenance programs don't rely on one tactic. They connect failure-mode knowledge, operating context, inspection history, condition monitoring, outage execution, and post-work verification into one decision system.
That's what separates a plant that manages outages from a plant that manages reliability. The first one reacts to the next maintenance event. The second one decides, with evidence, when to inspect, when to defer, when to monitor harder, and when to escalate. For teams also responsible for broader fleet discipline, these best practices for managing equipment are a useful reminder that asset decisions work best when maintenance, lifecycle planning, and documentation stay connected.
Some plants can build that capability in-house. Others need outside support for the technical depth and execution bandwidth, especially when rotating-equipment expertise is thin or repeated post-outage issues keep surfacing. In those cases, gas turbine maintenance outsourcing support can make sense when it's scoped around specific gaps such as monitoring, outage planning, verification, or reliability analysis.
The core principle stays the same. Gas turbine maintenance should be judged by what it prevents, what it proves, and what it costs over the full asset lifecycle. Anything less usually turns into repeat outages, avoidable repair scope, and hard conversations after the next trip.
Forge Reliability offers a free reliability assessment for plants that need a clearer gas turbine maintenance strategy. If a turbine program is stuck between calendar-based overhauls, recurring defects, and uncertain condition data, that assessment can help identify the highest-risk failure modes, the monitoring gaps, and the maintenance decisions most likely to improve uptime and reduce avoidable cost.