
A lot of water treatment maintenance programs still start the same way. A critical pump trips on a weekend, an operator notices a pressure problem after the process has already drifted, maintenance gets called in from home, and the plant burns hours on emergency troubleshooting while everyone asks the same question: why wasn't this caught earlier?
That cycle is expensive, but the bigger problem is loss of control. In a water or wastewater facility, the maintenance team isn't only protecting rotating equipment. The team is protecting effluent quality, disinfection performance, permit compliance, labor stability, and confidence in the plant's operating margin. When a clarifier drive, chemical feed skid, blower, or membrane train fails unexpectedly, the consequence isn't just a repair. It can turn into a process upset.
Table of Contents
- Moving Beyond Reactive Water Treatment Maintenance
- Establishing Your Asset Criticality Framework
- Selecting the Right Condition Monitoring Techniques
- Designing Tailored PM and PdM Task Lists
- Leveraging Your CMMS for Data Governance and ROI
- Your Implementation Checklist and Next Steps
Moving Beyond Reactive Water Treatment Maintenance
A reactive culture usually shows up before anyone names it. Storerooms fill with “just in case” parts, overtime gets normalized, operators stop trusting equipment that should be stable, and planners spend more time reshuffling emergency work than building useful schedules. In water treatment, that's a dangerous place to operate because many failures hit both production and compliance at the same time.

A clarifier drive is a good example. When it starts wearing internally, the warning signs are often available early: rising motor load, abnormal gearbox noise, dirty lubricant, or slower sludge removal performance. If nobody is watching those indicators, the plant often learns about the problem only after the drive stalls. Then the team is forced into the worst version of maintenance: urgent labor, uncertain root cause, rushed parts decisions, and process risk while the unit is impaired.
Reliability-centered maintenance changes the question
Reliability-centered maintenance, or RCM, asks a different question than “How often should this asset be serviced?” It asks, “How does this asset fail, what happens when it fails, and what maintenance task will prevent or detect that failure mode?”
That shift matters. A raw water pump doesn't fail for the same reasons as a hypochlorite dosing pump. A blower motor doesn't degrade the same way as a membrane rack. Treating every asset with the same calendar PM creates busy work on low-risk equipment and blind spots on permit-critical systems.
Practical rule: Reactive work should be the exception reserved for low-consequence assets, not the default operating model for process-critical equipment.
There's also a budget argument for changing course. A published water treatment industry article notes that scheduled inspections, chemical dosing pump calibration, and membrane cleaning can cost about $10,000 per year for a plant program, while disciplined preventive maintenance can reduce total maintenance costs by up to 25% to 30% versus reactive maintenance according to this water treatment maintenance cost comparison. That's why mature programs treat maintenance as risk control, not overhead.
Stable plants rely on planned upkeep
The strongest maintenance teams don't chase every symptom. They set rules for what gets monitored, what gets inspected, and what gets rebuilt before failure becomes a process event. That includes obvious assets like influent pumps and less obvious ones like analyzer sample pumps, valve actuators, and standby power systems that only reveal weakness when the plant needs them most.
Drainage and solids handling are another area where preventive thinking pays off. Facilities that need to prevent blockages with scheduled drain upkeep are dealing with the same reliability principle. A known recurring failure mode is cheaper to control on a schedule than to fight during an upset.
For teams trying to move from emergency response to a structured program, this is the operational model behind water and wastewater reliability support. The work starts by defining which failures matter most, then matching the right maintenance strategy to each asset.
Establishing Your Asset Criticality Framework
At 2:00 a.m., a small metering pump drops out on a chlorine feed skid. The motor is inexpensive. The swap is simple. The consequence is not. If residual control is lost long enough to miss permit limits, the event matters more than a much larger failure on a non-process utility. That is why asset criticality has to start with process consequence, not asset size, horsepower, or replacement cost.
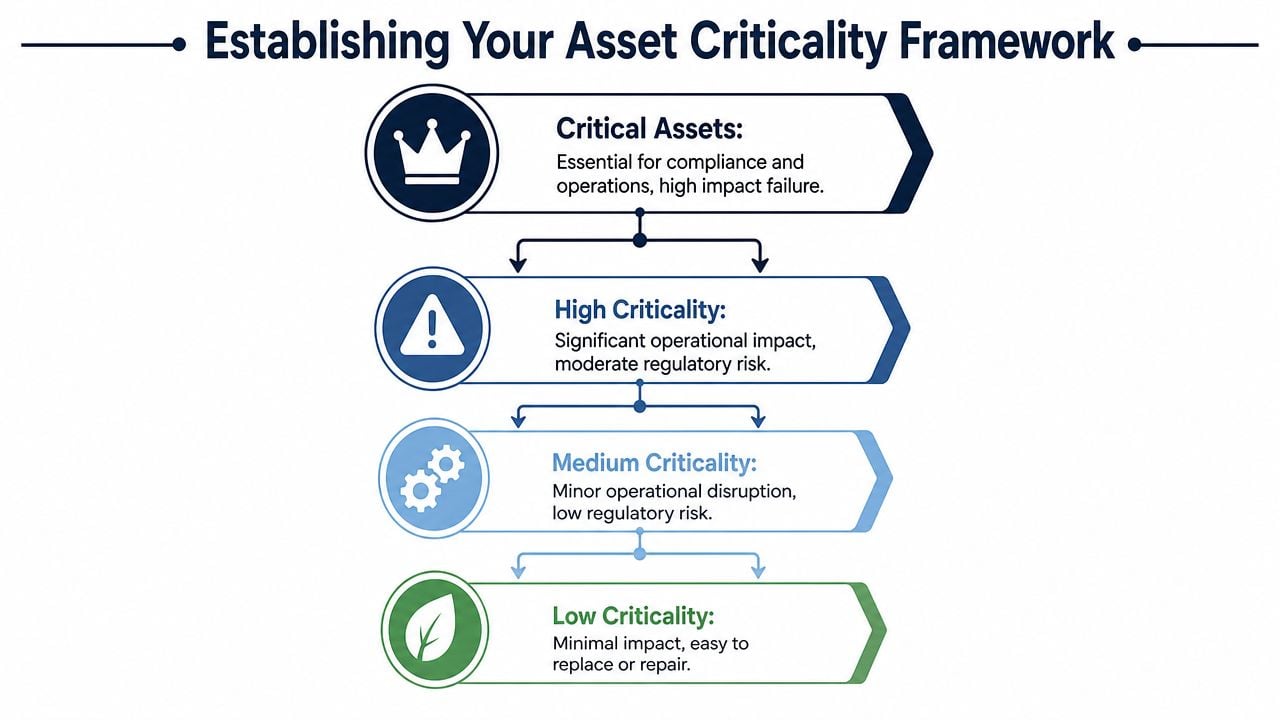
In water treatment, the top tier usually includes assets that can drive a permit event, create an immediate safety exposure, or remove a treatment barrier without enough warning or backup. That often means raw water intake pumps, high-service pumps, disinfectant feed systems, filter valves, membrane feed trains, residual analyzers, and standby power for process-critical loads. The point is to rank equipment by what failure does to water quality, capacity, and operator risk. A practical asset management approach for water treatment equipment makes that link explicit.
Permit consequence should outrank inconvenience. EPA guidance on sanitary surveys and capacity, management, operation, and maintenance reviews places strong emphasis on treatment barriers, monitoring, and operational control because failure in those areas can compromise compliance and public health, as described in the EPA overview of sanitary surveys for public water systems.
Start with consequence, then examine failure behavior
A useful criticality model for a treatment plant asks five questions.
- Compliance impact. If this asset fails, can the plant lose disinfection, filtration performance, chemical dose control, alarm visibility, or sample integrity?
- Safety exposure. Does failure increase the chance of chlorine release, electrical fault, confined-space work, or unsafe manual intervention?
- Production impact. Does the plant lose flow, lose one treatment train, or run at reduced quality margins?
- Recovery difficulty. Can operations restore function with stocked spares and standard labor, or does repair depend on a specialty technician, crane work, or long-lead parts?
- Failure detectability. Will degradation show up early in vibration, pressure, current, residual, or trend data, or does the asset tend to fail abruptly?
The last point gets missed often. Detectability changes the maintenance strategy. A blower bearing that gives warning through vibration and temperature can be managed very differently from an analyzer sample line that plugs unnoticed and leaves operators with false confidence in a residual reading.
Use equipment-specific failure modes, not generic labels
Reliability work becomes more useful than a simple red-yellow-green list. Criticality should reflect how the asset fails in a water plant.
A centrifugal pump is not "critical" in the abstract. Its failure modes matter. Seal wear can cause leakage and contamination. Bearing degradation can progress into shaft damage. Cavitation can destroy hydraulic performance long before the motor trips. On a membrane train, fouling and scaling raise transmembrane pressure and reduce throughput. On a clarifier drive, lubrication breakdown or torque overload can damage the gearbox and create a much larger outage than the original fault. On a sodium hypochlorite skid, loss of prime, crystallization, or check valve fouling can turn a small component issue into a disinfection control problem.
That failure-mode view is what connects high-level methods like RCM to plant decisions that operators and maintenance planners can use. If the consequence is high and the degradation is detectable, the asset usually belongs in a condition-based strategy. If the consequence is high and failure is hidden, the plant needs functional checks or proof testing. If the consequence is low and repair is easy, run-to-failure may be the right call.
A practical ranking example
Consider three common assets.
| Asset | Likely consequence of failure | Criticality reasoning |
|---|---|---|
| Raw water intake pump | Loss of flow into the process train | Top-tier if redundancy is limited, source conditions are variable, or restart time is long |
| Primary clarifier drive | Reduced solids removal, process instability, sludge handling disruption | High because process performance degrades first, then mechanical damage grows if repair is delayed |
| Lab HVAC unit | Comfort loss or drift in a non-process space | Lower unless it supports required testing conditions, reagent stability, or sensitive instrumentation |
The same logic applies inside a single package system. On a chlorination skid, the metering pump, calibration method, suction piping, and residual verification loop usually rank above washdown components and enclosure accessories. On a membrane system, feed pumps, automatic valves, differential pressure instrumentation, and clean-in-place transfer equipment usually deserve tighter control than general utility piping.
One more check matters. Find the hidden single points of failure.
I have seen plants with N+1 process pumps that still had only one healthy motor control center bucket, one sticky discharge valve, or one unreliable instrument air header serving the whole train. On paper, the plant had redundancy. In practice, it had a common-cause failure path that belonged near the top of the criticality list.
Selecting the Right Condition Monitoring Techniques
Once the plant knows which assets matter most, the next decision is how to watch them. Many programs then either overcomplicate the process or choose a technique because it's popular rather than because it fits the failure mode. Condition monitoring works only when the method matches the physics of degradation.
Match the method to the failure mode
A centrifugal pump with rolling element bearings usually gives mechanical warning through vibration. A gearbox often reveals distress through oil condition and wear debris. An overloaded electrical connection shows temperature rise. A membrane train loses performance through fouling and process restriction, so pressure and flow trends are often more useful than traditional rotating-equipment diagnostics alone.
That means one plant may use several predictive methods at once:
- Vibration analysis for bearing wear, looseness, misalignment, cavitation signatures, and hydraulic instability on influent pumps, high-service pumps, and blower trains.
- Oil analysis for clarifier gearboxes, drive reducers, and enclosed gear sets where contamination, oxidation, or internal wear can be detected before catastrophic damage.
- Infrared thermography for motor control centers, disconnects, overloaded breakers, VFD cabinets, and terminations that develop resistance heating.
- Acoustic ultrasound for compressed air leaks, valve leakage, steam traps in support utilities, and slow-speed mechanical assets where conventional vibration can miss early defects.
- Process condition monitoring for assets whose health shows up in operating variables such as differential pressure, turbidity, flow stability, amperage, and transmembrane pressure, often shortened to TMP.
A membrane rack is a good example of why process data matters. Mechanical inspection can tell the team whether valves, pumps, and actuators are functioning, but it won't by itself explain fouling progression. TMP trending can reveal when membrane resistance is rising, when cleaning intervals need adjustment, or when one train is drifting from the rest of the process. That's predictive maintenance too. It uses process evidence rather than only machine diagnostics.
Don't force every asset into the same predictive workflow. Pumps, chemical feed systems, clarifier drives, and membrane trains each reveal failure through different signals.
Condition Monitoring Techniques for Water Treatment Assets
| Equipment | Common Failure Mode | Primary PdM Technique | Secondary Technique |
|---|---|---|---|
| Centrifugal influent pump | Bearing wear, imbalance, misalignment, cavitation | Vibration analysis | Motor current review or thermography |
| Aeration blower | Bearing degradation, belt problems, airflow instability | Vibration analysis | Ultrasound or thermography |
| Clarifier gearbox | Gear wear, lubricant contamination, overheating | Oil analysis | Thermography |
| Chemical feed pump | Seal wear, check valve issues, loss of dosing accuracy | Performance trend review | Visual inspection and calibration checks |
| Membrane filtration train | Fouling, plugging, valve or control drift | TMP and differential pressure trending | Water quality trend review |
| MCC and VFD sections | Loose terminations, overloaded circuits, heat buildup | Infrared thermography | Ultrasound for arcing-related screening |
| Conveyor or slow-speed drive | Slow-speed bearing distress, chain problems | Acoustic ultrasound | Oil inspection |
The practical trade-off is labor. Plants can't apply every technique to every asset. Critical pumps and blowers usually justify route-based vibration collection. Low-speed sludge conveyors may be better served by ultrasound and targeted inspection. Chemical feed skids often need a combination of calibration discipline, leak checks, and process deviation review more than a full vibration program.
For teams that need a structured path, condition monitoring for water treatment equipment usually works best when route design follows the criticality ranking rather than organizational charts or trade boundaries.
Designing Tailored PM and PdM Task Lists
At 2 a.m., an influent pump starts running hotter than normal. Operators hear a slight change in sound, but the monthly PM only says “inspect pump.” That wording does not tell anyone what to measure, what failure mode they are screening for, or what action should follow. A useful task list closes that gap. Each task should either prevent a specific failure or detect it early enough to plan the repair.

Calendar-based PMs rarely fit the way water treatment plants operate. Wet weather changes loading. Source water changes membrane fouling rates. Duty and standby rotation changes pump run-hours. For that reason, task triggers should match the failure pattern. Run-hours often fit bearings and seals better than calendar intervals. Differential pressure and TMP fit filters and membranes better than fixed dates. Process deviation checks often catch chemical feed problems earlier than a mechanical teardown, as described in this preventive maintenance guidance for water treatment equipment.
Build tasks around function loss
Start with the asset's required function, then define how that function is lost in service.
A high-service pump must deliver flow and pressure without excessive leakage or vibration. The failure modes are usually straightforward. Mechanical seal wear causes leakage. Bearing defects raise vibration and temperature. Coupling misalignment increases load on bearings and seals. Suction problems create cavitation that damages hydraulic surfaces and destabilizes flow. Once those failure modes are clear, the task list becomes more precise. Seal flush inspection addresses seal reliability. Vibration routes screen bearings and alignment condition. Suction and discharge pressure checks help identify hydraulic problems before the pump fails in service.
The same logic applies to process equipment.
A membrane train loses function through fouling, plugging, valve problems, and bad instrumentation. A good PdM task for membranes is not “inspect skid weekly.” It is daily TMP review, train-to-train comparison, conductivity trend review, and verification that the pressure instruments used for those decisions are reading correctly. If the pressure transmitter drifts, the plant can miss a developing fouling problem and clean too late.
Four questions keep task development disciplined:
What function must the asset deliver?
Define it in operating terms. Flow, pressure, dose accuracy, solids removal, air delivery, level control.How does that function fail in this plant?
Use actual plant history when possible. Pump seal leaks, blower bearing defects, clarifier gearbox overheating, diaphragm pump check valve wear, membrane fouling, instrument drift.What inspection, PM, or PdM task can address that failure mode?
Choose the task that gives the earliest useful warning at a reasonable labor cost.What trigger fits the way the failure develops?
Time, run-hours, starts, pressure differential, lab trends, operator rounds, vibration trends, oil condition, or calibration interval.
Examples from common water treatment assets
For an influent pumping station, the task list should separate operator care, technician inspection, and condition monitoring. Daily rounds should check suction stability, visible leakage, seal water condition, and abnormal noise. Mechanics should verify alignment after motor or coupling work and inspect base hardware if vibration increases. Vibration collection should be route-based on the duty and standby units if the pump is critical enough to justify it. Lubrication should follow bearing type and operating hours, not a blanket monthly schedule copied across the plant.
For chemical feed pumps, the failure mode matters more than the asset class. A metering pump can look mechanically sound and still fail its real function by underdosing. The PM should include stroke or speed verification, calibration against actual output, leak inspection at tubing and fittings, check valve inspection, and review of process deviation that could point to loss of dosing accuracy. That is often more valuable than adding a formal vibration task to a small skid-mounted unit.
For clarifier drives and gearboxes, use inspections that match slow-speed equipment behavior. Operators can check for abnormal noise, oil leakage, and torque arm condition during rounds. Maintenance can add housing temperature checks, lubricant level and cleanliness review, and periodic oil sampling when failure consequence warrants it. Slow-speed assets often reveal problems through lubrication condition and mechanical looseness before they show a clean vibration signature.
For above-ground storage and distribution assets, the task list should also reflect material and environment. UV exposure, support settlement, nozzle stress, and fitting leaks drive a different inspection plan than rotating equipment. Plants responsible for tanks can borrow useful ideas from guidance on extending poly tank lifespan, then adapt those checks to local water quality, chemical compatibility, and exposure conditions.
The best task lists are written so two technicians can perform the same job, record the same observation points, and reach the same maintenance decision.
Platform support can be relevant here. Some plants build task libraries internally. Others use engineering support such as Forge Reliability to map pump seal wear, membrane fouling, gearbox lubrication problems, and instrument drift to the right PM, PdM, and operator inspection steps. The important part is the method. Every task should trace back to a known failure mode and a defined decision.
Leveraging Your CMMS for Data Governance and ROI
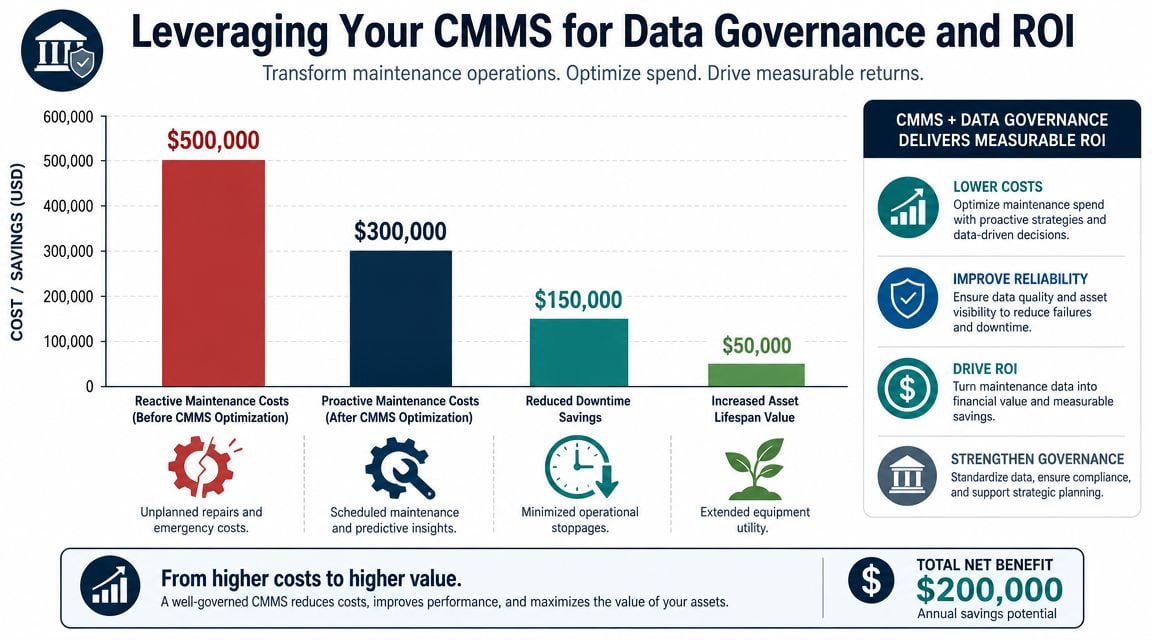
A CMMS becomes useful when it stops acting like a ticket queue and starts acting like a reliability record. Many plants already have the software. What they don't have is data discipline. If work orders are vague, failure descriptions are inconsistent, and asset names don't match field reality, the system can't support better decisions.
Good CMMS data starts on the plant floor
The first governance rule is asset hierarchy. A plant shouldn't bury a critical process pump under a vague location name or mix process assets with building utilities in ways that hide consequence. The hierarchy should reflect how the plant operates: system, sub-system, asset, and maintainable component.
The second rule is work order quality. “Pump repaired” tells management nothing. A useful closeout identifies what failed, how it failed, what symptom triggered discovery, what action corrected it, and whether the failure was planned or emergency work. That level of detail is what makes bad actors visible over time.
Three practical controls help:
- Standardize failure codes so seal leaks, bearing defects, electrical faults, valve sticking, and instrument drift aren't all dumped into “mechanical.”
- Require symptom detail from operators and technicians. Noise, temperature rise, pressure instability, and visible leakage each point to different root causes.
- Tie PM completion to evidence. If vibration was collected, the reading should be attached or entered. If calibration was performed, the as-found and as-left condition should be recorded.
A similar principle applies to storage assets. Teams responsible for chemical or water storage often benefit from specific maintenance guidance on extending poly tank lifespan, especially when those tanks support process continuity and inspection history needs to be documented inside the same maintenance system.
KPIs that actually help maintenance decisions
The most useful KPIs are the ones that drive action, not presentation slides.
- Mean time between failure for critical pumps and drives helps identify whether reliability is improving on the assets that matter most.
- PM compliance matters when the PMs are technically valid. High compliance on weak tasks doesn't improve plant health.
- Planned versus emergency work mix shows whether the organization is gaining control over labor and scheduling.
- Repeat failure count by asset points directly to poor repair quality, wrong task selection, or unresolved operating issues.
A CMMS should answer three questions quickly: what failed, why it failed, and whether the same thing is starting to happen somewhere else.
When teams implement CMMS workflows for water treatment equipment, the payoff usually comes from better decisions first. Cost reduction follows after the plant can trust its data, tighten PM scope, and focus engineering effort on the assets with recurring loss.
Your Implementation Checklist and Next Steps
At 2:00 a.m., a high-service pump trips, the standby unit starts late, and the operator logs a pressure upset with no clear cause. By morning, maintenance has three work orders, no failure codes worth trusting, and no agreement on whether the problem started with the pump, the drive, or the control sequence. That is what a weak rollout looks like. A controlled rollout starts smaller, ties every task to a known failure mode, and proves that the plant can detect degradation before it loses process stability.
Start with one system where the failure consequence is obvious and the diagnostics are practical. A membrane train, influent pump station, or disinfection system usually works well because the failure modes are familiar and the process gives fast feedback. Membrane fouling shows up in transmembrane pressure and permeability trends. Pump bearing defects and misalignment show up in vibration, temperature, and power draw. Chlorine feed problems often show up first in analyzer drift, injector plugging, or loss of vacuum. Build the program around those signals, then expand once the team can collect, review, and act on them consistently.
A rollout usually works best in phases instead of a plant-wide launch. The exact timing depends on asset count, data quality, and crew capacity, but the sequence should stay disciplined: define the pilot scope, clean up the asset register, write failure-mode-based tasks, train the people doing the work, then review what the pilot uncovered.
Use this checklist:
Pick one pilot system with high operational consequence.
Choose equipment that can create permit risk, service interruption, or expensive emergency work. Common starting points are raw water intake pumps, membrane skids, UV disinfection trains, high-service pumps, chemical feed systems, standby generators, and solids-handling equipment.Rank assets inside that system before writing tasks.
Do not give every asset the same maintenance depth. A membrane feed pump, its motor, VFD, suction valve, and differential pressure instrumentation deserve more attention than a non-critical washdown pump because they have a direct effect on flow, water quality, and downtime exposure.Define the dominant failure modes and match the task to the physics of failure.
For rotating equipment, separate seal leakage, bearing wear, imbalance, misalignment, cavitation, and motor electrical defects. For membranes, separate fouling, scaling, chemical attack, and integrity loss. For analyzers, separate sensor drift, sample line blockage, reagent issues, and calibration error. Then choose the task that can detect each condition early enough to plan the repair. That may mean vibration routes for pumps and blowers, oil analysis for gear reducers, infrared checks for MCC connections, ultrasound for air leaks and bearing friction, and TMP trending for filtration assets.Write job plans that produce usable evidence.
Each task should tell the technician what to inspect, what reading to collect, what limit or abnormal condition matters, and what action to trigger. "Inspect pump" is too vague. "Record inboard and outboard vibration, note seal leakage rate, verify suction pressure stability, and create a follow-up work order if readings exceed site limits" gives the technician something repeatable.Set up the CMMS so failure history can be trusted.
Use clear asset hierarchy, consistent naming, failure codes tied to actual modes, and required closeout fields. If a pump work order can be closed without noting whether the failure was seal wear, bearing damage, cavitation, or control-related short cycling, the plant loses the chance to improve the task list.Train operators and technicians on their separate roles.
Operators usually catch process symptoms first. Technicians usually confirm the equipment condition and complete the corrective scope. Make that handoff explicit. An operator noticing rising TMP, unstable discharge pressure, or abnormal chemical consumption should know exactly what to log and when to escalate.Run the pilot long enough to test the workflow, not just the paperwork.
The question is not whether the PMs were completed. The question is whether the inspections found real degradation early enough to avoid an unplanned event, whether planners could schedule the follow-up work, and whether the failure coding was good enough to improve the next revision.Revise tasks based on what the pilot exposes.
If technicians collect a reading that never changes maintenance decisions, remove it. If membrane differential pressure trends repeatedly flag fouling before visual inspection does, make that trend a primary trigger. If repeated seal failures trace back to dry running or poor flush plans, correct the operating condition and update the standard job plan.
The trade-off is straightforward. A narrow pilot feels slower at the start, but it prevents a larger failure later, where the plant has hundreds of PMs in the system and still cannot explain why pumps keep losing seals or why membrane cleaning frequency keeps rising.
Water treatment plants improve maintenance performance when they connect reliability methods to the equipment faults that drive loss. RCM is useful here only if it ends in specific actions. For a vertical turbine pump, that means deciding whether vibration, motor current, discharge pressure instability, or operator rounds will detect the likely failure mode first. For membranes, it means deciding which TMP trend, conductivity check, or cleaning trigger gives enough warning to act before capacity drops.
A free reliability assessment from Forge Reliability can help identify permit-critical assets, tighten PM and PdM task design, and build a practical program around the failure modes already driving downtime in the plant.


