
The pattern is familiar in almost every plant that's stuck in reactive mode. Operators submit vague requests. Planners chase missing details. Technicians arrive at the asset, then discover the wrong parts, the wrong craft, or no isolation plan. By the end of the week, the backlog is larger, the emergency jobs have multiplied, and nobody trusts the data in the system.
That's not just an administrative problem. It's a reliability problem. A weak work order process hides failure modes, distorts priorities, and prevents maintenance leaders from seeing whether the plant is controlling equipment risk or responding to it after the fact.
The business importance is clear. The global work order management systems market was estimated at USD 760.4 million in 2024 and is projected to reach USD 1.187 billion by 2030, growing at a CAGR of 8.2% according to Grand View Research's market outlook for work order management systems. That growth reflects a broad operational shift. Plants increasingly expect work execution data to support uptime, asset strategy, and maintenance planning, not just dispatch mechanics.
A strong work order process becomes the foundation of a reliability program when every request captures useful technical detail, every completed job adds to asset history, and every KPI exposes where control is slipping. Teams that need a structured path can align this work with a broader 12-month reliability program roadmap.
Table of Contents
- From Reactive Chaos to Proactive Control
- The Anatomy of a High-Value Work Order
- Integrating Work Orders with Your CMMS for Data-Driven Reliability
- Developing Workflows for Prioritization and Scheduling
- Essential KPIs and Dashboards for Performance Tracking
- Work Order Templates for Common Asset Failures
- Your Implementation Roadmap and Governance Checklist
From Reactive Chaos to Proactive Control
A chaotic work order process usually shows up before anyone says it out loud. Technicians spend too much time clarifying jobs. Supervisors override the schedule daily. The same assets reappear in the queue with slightly different descriptions, so nobody can tell whether the plant has one chronic defect or five unrelated problems.
In a chemical unit, for example, one operator may submit “pump leaking,” another may enter “seal issue,” and a third may call it “area cleanup needed.” If those all point to the same pump, the plant now has fragmented history, confused priority, and no clear record of failure progression. That's how reliability blind spots start.
Work orders are operating data, not clerical paperwork
A good work order does two jobs at once. It directs the immediate task, and it preserves structured evidence about asset condition, failure symptoms, labor demand, parts consumption, and follow-up risk.
That distinction matters. Plants don't improve uptime because they closed more tickets. They improve uptime because they used work order history to decide which assets need design changes, which routes need better inspections, which PM tasks are ineffective, and which crews are overloaded.
Practical rule: If a work order can't help a technician execute the job and help an engineer analyze the asset later, it's incomplete.
Control starts when the plant defines what “good” looks like
The first step out of reactive chaos is standardization. Every requester needs the same minimum fields. Every planner needs the same priority rules. Every technician needs the same closeout expectations. Without that discipline, the plant can't separate true emergencies from poor planning.
A pulp and paper mill offers a good example. A stock pump serving a paper machine doesn't just need “repair ASAP” in the request. It needs a clear symptom description, the exact asset tag, observed operating condition, risk to production, and whether leakage, noise, cavitation, or vibration has already been seen. That level of detail changes the response from guesswork to control.
Plants that make this shift stop treating work order management as an office function. They treat it as the entry point to reliability engineering.
The Anatomy of a High-Value Work Order
The greatest impact in work order management occurs at the moment the order is created. A complete work order must capture asset ID, failure symptom, priority, required skills, parts, and safety steps so the team can execute efficiently and use the data later for reporting and analysis, as described in this work order management guide from TMA Systems.
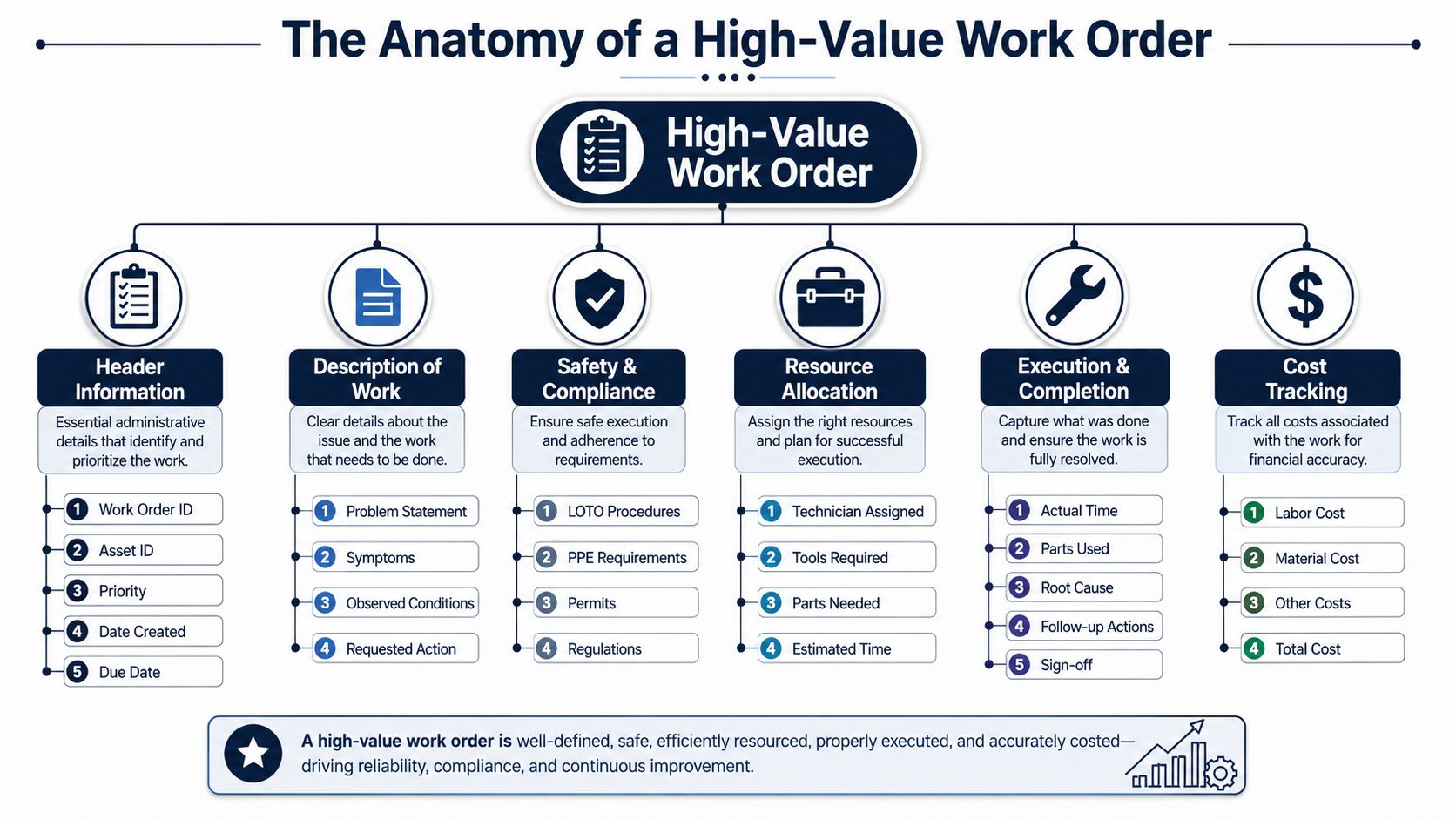
What must be captured at creation
A high-value work order isn't longer for the sake of being longer. It is specific in the fields that matter.
- Asset identification. The exact asset tag, location, and equipment class must be entered. “Pump in north line” is not enough. “P-103, bleach plant filtrate transfer pump” is usable.
- Failure symptom. The request should describe what was observed, not just that something is wrong. High vibration, seal leakage, high motor temperature, intermittent trip, and abnormal noise each point the planner toward different resources.
- Priority. Priority should reflect business risk, safety exposure, and functional impact. Without that, every requester marks the job urgent.
- Required craft and skills. A mechanical seal replacement on a slurry pump may require a millwright. A motor overheating issue may require both electrical troubleshooting and alignment verification.
- Parts and tools. If the likely parts list is omitted, technicians lose time walking back to the storeroom and planners can't stage work properly.
- Safety steps. Lockout and tagout, line isolation, confined space controls, hot work precautions, and process hazard steps belong in the order before the job starts.
A poor request versus a useful one
In a pulp and paper mill, a vague order often looks like this:
Pump #3 is broken.
That entry creates delay immediately. Which pump? What failed? Is it still running? Is the problem leakage, bearing noise, low flow, or motor overload? Does the job require mechanical work, electrical diagnosis, or both?
A high-value version looks more like this:
Centrifugal pump P-103 at the stock prep area shows high-frequency vibration at the outboard bearing. Operator reported rising noise during the last shift. No motor trip observed. Inspect bearing condition, coupling alignment, lubrication state, and base looseness. Prepare for millwright support and bearing replacement if confirmed.
That level of detail changes the quality of planning.
The dual purpose of each field
Every field should support execution now and analysis later.
| Field | Immediate value | Reliability value |
|---|---|---|
| Asset ID | Sends crew to the correct machine | Preserves asset history |
| Symptom description | Helps diagnose the problem faster | Supports failure mode trending |
| Priority | Guides response speed | Reveals whether risk rules are working |
| Required craft | Matches skill to task | Shows labor demand by asset type |
| Parts required | Reduces delays at execution | Identifies repeat component consumption |
| Safety steps | Prevents unsafe starts | Documents recurring hazard exposure |
A water and wastewater facility sees this clearly with lift station pumps. If repeated work orders say “pump alarm,” the history stays muddy. If the orders record “high amp draw,” “ragging at impeller,” or “mechanical seal leakage at flush line,” the maintenance team can separate chronic process contamination from mechanical wear and decide whether the fix is screening improvement, seal upgrade, or inspection frequency change.
Detailed work orders don't slow a plant down. They reduce avoidable second trips, replanning, and repeat failures.
The common mistake is overloading the form with fields that nobody uses while ignoring the fields that support diagnosis. The best forms are lean but technically meaningful. They force clarity where ambiguity creates cost.
Integrating Work Orders with Your CMMS for Data-Driven Reliability
A work order becomes far more valuable when it sits inside a disciplined CMMS, or Computerized Maintenance Management System. The CMMS is where individual tasks become asset history, where closeout records become trend data, and where maintenance leaders can test whether the current strategy controls failure.
Completed work orders should record labor, parts, downtime impact, and follow-up actions because those records create the historical data needed to identify recurring failure modes and improve maintenance strategy within a CMMS, as explained in this overview of work order management practices from eMaint.
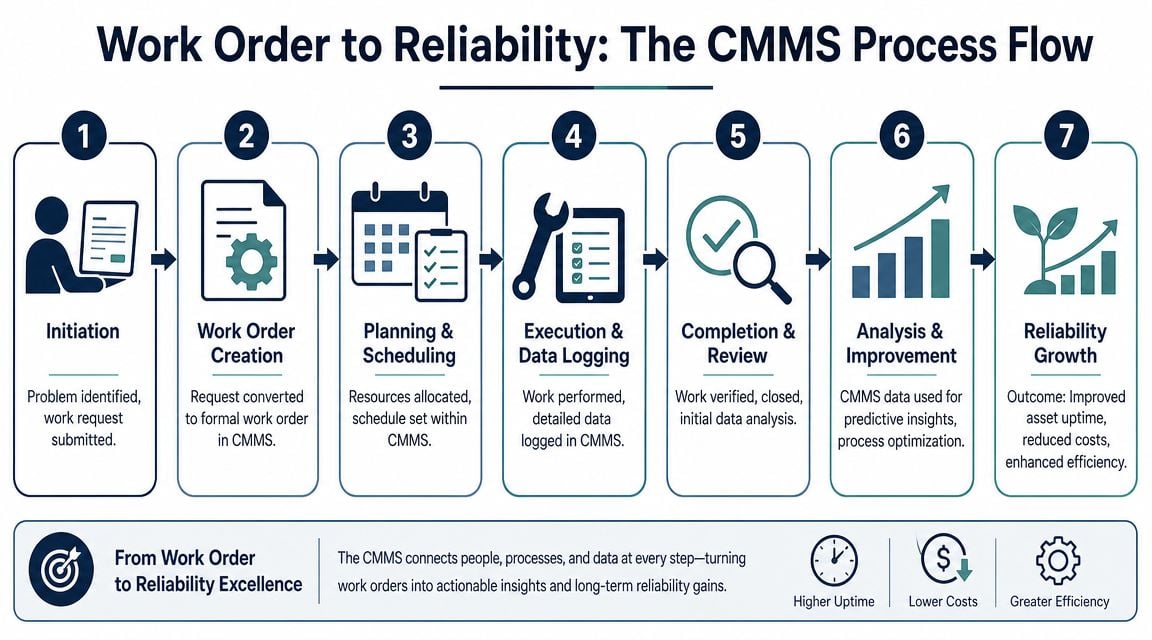
The CMMS must reflect the asset hierarchy
A CMMS only helps when the structure is clean. That starts with asset hierarchy, which means the system mirrors how equipment is organized physically and functionally. Site, area, line, system, and asset should make sense to the people doing the work.
If the hierarchy is sloppy, the data becomes unreliable fast. A gearbox may be logged under the conveyor one month, under the motor the next month, and under a generic line asset after that. When engineering reviews the history, the plant can't tell which component is causing downtime.
A food and beverage facility offers a good example. Consider a washdown conveyor on a packaging line. If the motor, gearbox, coupling, and conveyor assembly are all treated as one generic asset, the history blends mechanical, electrical, and contamination issues together. If those assets are defined clearly, the team can isolate whether the recurring problem sits in motor bearings, seal ingress, chain alignment, or sanitation practice.
For plants improving system quality, disciplined CMMS implementation services often focus first on hierarchy, naming rules, failure code structure, and closeout discipline rather than software features.
Closed work orders create reliability intelligence
The closeout stage is where many plants lose the value they worked hard to create. Technicians complete the repair, mark the job done, and leave the failure mode blank. Labor hours are entered loosely. Parts are not associated to the actual repair. Downtime impact is omitted. At that point, the plant has administrative closure but weak engineering data.
A useful closeout captures at least these items:
- What was found. Not just the symptom, but the confirmed condition.
- What was done. Inspection, adjustment, component replacement, alignment, cleaning, rebuild, or design modification.
- What was consumed. Labor, parts, and support craft.
- What happened to production. Whether the task required downtime, reduced rate, or no process interruption.
- What should happen next. Follow-up inspection, root cause review, interval change, or redesign.
A closed work order should answer one question clearly. If this asset fails again next month, what will the next technician need to know?
In a food plant, repeated conveyor motor failures may initially look like random electrical issues. But if completed work orders consistently record contamination at the non-drive end, repeated insulation degradation, and frequent washdown exposure, the pattern becomes visible. That history can justify moving to a sealed washdown-duty motor, revising the guarding, or changing the cleaning method. Without structured closeout data, the plant keeps replacing motors and calling it bad luck.
The CMMS should act as the plant's memory. If it only stores status changes, it won't support reliability decisions. If it stores technically meaningful work history, it becomes one of the strongest tools in the maintenance organization.
Developing Workflows for Prioritization and Scheduling
Most failing work order systems don't suffer from lack of effort. They suffer from lack of decision rules. When everything enters the queue the same way, the loudest request wins, not the riskiest one. That's how important preventive work gets delayed while low-consequence nuisance jobs consume planned labor.
Priority must follow risk, not noise
The priority model should tie each work order to asset criticality and consequence. Criticality is the relative importance of an asset based on safety, environmental exposure, production impact, quality risk, and repair complexity.
A simple four-level structure works well if the business rules are explicit:
- P1 emergency. Active safety risk, environmental release, forced outage, or immediate production loss. Work starts as soon as the area is made safe and the required craft is available.
- P2 high. Significant functional degradation on a critical asset, but not yet an active emergency. The job is planned immediately and scheduled at the earliest safe window.
- P3 medium. A correctable defect with manageable short-term risk. The work enters the planned schedule with parts, labor, and coordination.
- P4 low. Cosmetic issues, minor defects on noncritical assets, and discretionary improvements.
In a chemical processing plant, an active leak on a critical reactor feed pipeline is a P1 because the consequence includes process hazard and loss of containment. A noisy bearing on a redundant standby pump is not the same problem. It may be a P3 if the duty pump remains healthy and the standby unit can be repaired during the next planned window.
Plants lose schedule control when requesters assign priority based on frustration instead of consequence.
Written procedures matter here. Teams that need to tighten consistency often benefit from reviewing how standard operating procedures explained can translate decision logic into repeatable field practice. The point isn't paperwork. The point is getting every supervisor and planner to make the same call when similar risk appears.
Scheduling logic should match the work type
Not all work should be scheduled the same way. Preventive work, condition-based findings, and corrective repairs each require different planning logic.
Condition-based work deserves special attention because it often prevents the next breakdown if handled quickly and correctly. A vibration route may identify bearing defect frequencies on a cooling water pump. That doesn't mean the team should rush into a same-day repair. It means the planner should verify severity, confirm parts availability, check production constraints, and place the job into the next practical window before the defect advances.
Corrective work found during inspections should be screened for failure progression. If the fault is stable and the asset is redundant, the job can wait for a coordinated outage. If the defect is accelerating or threatens secondary damage, the work should move up.
A workable scheduling rhythm usually includes:
- Daily screening for new requests and true emergencies.
- Weekly scheduling for planned corrective and preventive work.
- Outage coordination for tasks requiring process isolation or major labor.
- Craft balancing so the plan fits actual mechanical, electrical, and instrumentation capacity.
Plants that want to improve labor efficiency often formalize these decisions through structured maintenance planning support. What matters most is not the label on the workflow. It is whether the planner can defend why one job moved ahead of another.
A refinery, mill, or packaging plant won't become proactive until priority and schedule rules are stronger than daily pressure.
Essential KPIs and Dashboards for Performance Tracking
A work order process improves when managers can see whether the system is absorbing demand or falling behind. The most durable KPI framework for work order management centers on backlog, on-time performance, and response time. In practice, backlog measures pending maintenance hours, on-time performance is the percentage of work orders completed by due date, and response time is the average time from request submission to labor start. One published example calculates 1,000 total hours across 50 service requests, which equals 20 hours per request, as shown in this maintenance KPI reference from FT Maintenance.
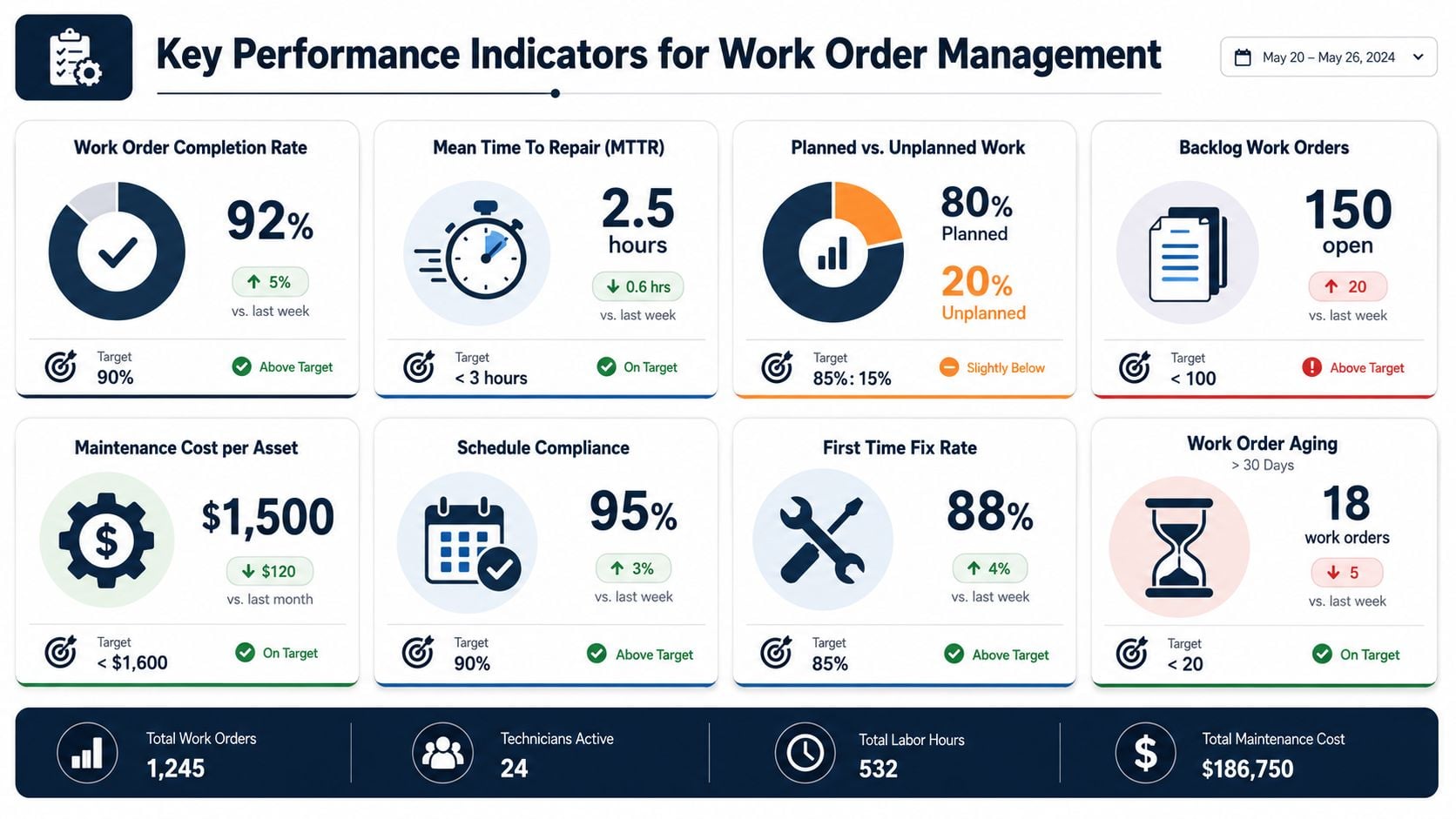
The core KPIs that expose control problems
These three measures work because they show different dimensions of discipline.
- Backlog reflects how much maintenance work remains open. If backlog keeps growing, maintenance demand is outrunning execution capacity, job scope is poor, or the plant is starving planned work of labor.
- On-time performance shows whether the team completes jobs by the promised due date. Poor results here usually point to weak planning, parts delays, bad prioritization, or overcommitted schedules.
- Response time shows how long requests wait before labor starts. A rising value often means screening and assignment are too slow, or too many emergency jobs are interrupting the workforce.
These KPIs are useful because they reveal process behavior, not just historical cost. Oracle's work-order analytics also standardize related measures such as average work order age in days, incoming, planned, and completed work order rates, and average days to complete, reinforcing that work execution should be managed as a measurable workflow discipline rather than as ad hoc dispatching. That idea is already embedded in the KPI framework described above.
What a useful dashboard looks like in practice
At a power generation facility, dashboard design should focus on decisions, not decoration. A plant manager looking at turbine-related work needs to know whether critical preventive work is slipping, whether corrective findings are accumulating, and whether labor is being consumed by interruption-driven tasks.
A practical dashboard might organize the review this way:
| Dashboard view | What the manager looks for | Reliability concern |
|---|---|---|
| Backlog by critical system | Open work on turbine auxiliaries, balance of plant, and electrical support assets | Hidden risk building around critical equipment |
| On-time completion by work type | PMs versus corrective work | Planned work being crowded out |
| Response time by priority | Whether urgent work waits too long | Screening and dispatch failure |
| Aging open work orders | Jobs sitting open without action | Weak ownership or missing parts |
| Incoming versus completed work | Whether the team is keeping up | Execution capacity mismatch |
A gas turbine support system gives a concrete example. If lube oil pump inspections and valve corrective jobs start aging while incoming work rises, the dashboard is warning the plant before a forced outage occurs. The right response may be contractor support, a schedule reset, or a focused outage plan. The wrong response is to merely close low-value tickets and claim improvement.
A KPI only matters if it triggers a management action. If nobody changes labor, schedule, scope, or strategy after the review, the dashboard is just wallpaper.
Teams that want stronger metric definitions and closer alignment with asset performance often tie work order reporting to broader reliability metrics such as MTBF, MTTR, and OEE. That connection helps maintenance managers see whether better work control is improving operating results.
The best dashboards stay narrow. They show what is slipping, where it is slipping, and who owns the correction.
Work Order Templates for Common Asset Failures
Templates are where good intent becomes repeatable execution. A strong template doesn't turn technicians into script followers. It gives planners and crafts a shared starting point so critical information isn't forgotten when the plant is busy.
In practical terms, templates should reflect real failure modes on real assets. They should include the triggering symptom or diagnostic, the likely craft needed, the key safety controls, and the minimum closeout data required for reliability analysis.
Template comparison table
| Asset Type | Failure Mode | Triggering Diagnostic | Required Craft | Key Work Steps |
|---|---|---|---|---|
| Centrifugal pump | Bearing fault | Vibration analysis indicates bearing defect pattern | Millwright | Isolate pump, verify defect, inspect bearing, check alignment and lubrication, replace components as needed |
| Centrifugal pump | Mechanical seal leak | Operator report and visual inspection of leakage | Millwright | Lock out, isolate process, inspect seal faces and flush plan, replace seal, verify alignment and restart condition |
| AC induction motor | Overheating | Thermography identifies elevated casing or connection temperature | Electrician and millwright as needed | De-energize, inspect load and cooling path, check terminations, verify alignment and driven load condition |
| AC induction motor | Suspected winding issue | Motor circuit analysis indicates electrical anomaly | Electrician | Lock out, test windings and connections, inspect insulation condition, decide repair versus replacement |
| Reciprocating compressor | Valve problem | Ultrasound indicates abnormal valve signature | Mechanical technician | Isolate compressor, inspect valve condition, replace damaged components, verify performance after restart |
For teams building better failure logic upstream, this kind of standardization pairs well with FMEA methods for maintenance decision-making, especially when chronic defects keep recurring on the same asset class.
Centrifugal pump bearing fault
A water and wastewater plant often catches this issue through route-based vibration analysis before operators feel it in process performance.
Problem description
Centrifugal pump P-204 shows high vibration consistent with bearing distress at the drive-end or non-drive-end location. No visible leakage reported. Verify condition before failure progresses into shaft damage or coupling-related secondary effects.
Initial diagnostic steps
- Confirm the location by checking measurement points against the asset tag and pump train arrangement.
- Review recent operating state such as flow changes, cavitation signs, or recent maintenance.
- Inspect for contributors including lubrication condition, soft foot, base looseness, and coupling misalignment.
Required craft
Millwright. Electrical support only if motor condition is also suspect.
Potential parts
Bearing set, seals, lubricant, coupling insert if wear is present, and hardware if fasteners or shims need replacement.
Critical safety precautions
Lockout and tagout the motor. Isolate process flow. Confirm zero energy. Address hot surfaces and slip risk near the base if leakage is present.
Key closeout fields
Confirmed bearing location, observed damage mode, lubrication condition, alignment findings, parts used, and any recommendation for follow-up vibration verification.
Mechanical seal leak on a process pump
In pulp and paper, chemical, and water service, a seal leak is often treated as routine until it becomes a chronic reliability drain.
Problem description
Process pump P-103 has active leakage at the seal area. Evaluate leakage rate, seal support condition, shaft sleeve condition, and any evidence of dry running or flush plan failure.
Work steps
- Secure the asset with electrical lockout and process isolation.
- Inspect the seal environment for flush line blockage, contamination, and evidence of overheating.
- Disassemble and inspect seal faces, sleeve, gland, and shaft condition.
- Replace and set the seal to specification.
- Verify alignment and piping strain before restart.
- Document leak source and contributing condition rather than writing only “seal replaced.”
A weak work order requests a seal change. A better one asks the technician to capture whether the failure came from contamination, misalignment, dry running, or improper installation. That is the difference between repair history and reliability history.
AC induction motor overheating
A packaging or material handling line often catches this through thermography during a route inspection.
Elevated motor temperature is a symptom, not a diagnosis. The order should force the team to inspect electrical load, cooling path, and mechanical contributors before replacing parts.
Problem description
Motor M-117 shows abnormal external temperature at the frame or terminal box during operation. Investigate electrical imbalance, overloaded driven equipment, blocked cooling, bearing drag, and alignment condition.
Required craft
Electrician first. Millwright support if alignment, coupling, bearing drag, or driven load condition appears involved.
Key work steps
- Lock out the motor and verify zero energy.
- Inspect cooling surfaces and fan path for contamination.
- Check terminations for looseness or heat damage.
- Assess the driven equipment for drag, misalignment, or process overload.
- Record findings separately for electrical and mechanical causes.
Potential winding fault on an AC motor
A motor circuit analysis result should trigger a more disciplined order than “motor bad.”
Problem description
Motor M-221 shows test results consistent with a potential winding or insulation-related defect. Confirm with electrical testing, inspect connections, and determine whether the unit can remain in service, needs repair, or should be changed out.
Diagnostic expectations
- Verify test history against previous readings on the same motor.
- Inspect the terminal box and leads for contamination, looseness, or insulation distress.
- Document the decision point clearly: continue operating with monitoring, remove for shop repair, or replace.
Critical safety precautions
Electrical lockout, arc flash boundary controls where applicable, and verification that stored energy has been addressed before testing.
Reciprocating compressor valve problem
In petrochemical and gas handling service, ultrasound often identifies an abnormal valve event before process performance makes the fault obvious.
Problem description
Reciprocating compressor C-301 shows abnormal ultrasound signature suggestive of valve leakage or valve damage. Confirm cylinder location, inspect valve condition, and assess whether operation has introduced secondary damage risk.
Required craft
Mechanical technician with compressor experience. Instrument or operations support if load or process condition must be verified.
Key work steps
- Isolate and depressurize the compressor according to site procedure.
- Open the correct access point based on the suspected valve location.
- Inspect valve components for breakage, carboning, contamination, or seat damage.
- Replace or repair components as required.
- Validate performance after restart and note any load or temperature abnormalities.
A good compressor work order also asks for the observed symptom before teardown. Was there reduced capacity, temperature deviation, or only an ultrasound indication? That distinction matters when engineering reviews whether inspection intervals are set correctly.
Templates work best when planners maintain them by asset class and failure mode, then refine them after real jobs. The template should improve every time a chronic defect teaches the plant something new.
Your Implementation Roadmap and Governance Checklist
A plant doesn't fix work order management by issuing one memo or changing one screen in the CMMS. The process improves when standards, workflow, data quality, and management review all change together.
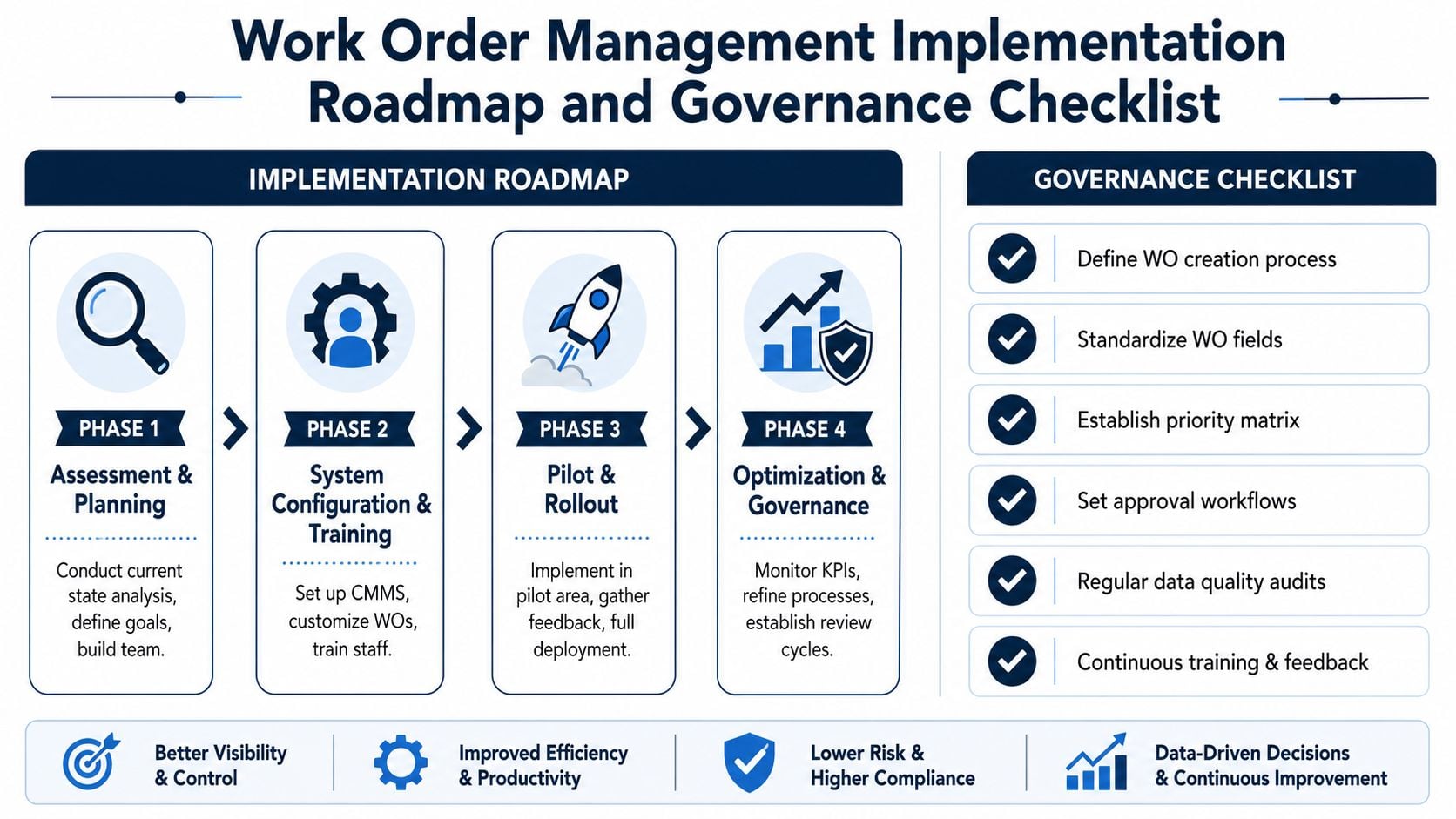
A phased rollout that plants can actually execute
A phased approach works because it reduces disruption and exposes weak assumptions early.
Phase 1: Standardization and training
Start with the work order itself. Define mandatory fields, approved priority levels, closeout expectations, and role ownership. Train operators, supervisors, planners, and technicians on what each field means. A metals plant often finds at this stage that different departments use different names for the same asset, which must be corrected before any reporting can be trusted.
Phase 2: CMMS configuration and data cleanup
Configure the system around the agreed process, not the other way around. Clean asset records, align hierarchy, define failure coding, and remove duplicate equipment entries. Pilot the process in one area such as utilities, packaging, or a single production line before broad rollout.
Phase 3: KPI and dashboard rollout
Once the data is stable enough to review, begin regular reporting. Focus on the small set of KPIs covered earlier rather than building a giant scorecard. In a cement plant, for example, weekly review of kiln support equipment backlog and on-time completion can reveal whether planners are protecting critical work or letting emergency tasks consume the crew.
Phase 4: Continuous improvement and analysis
Use completed work history to challenge existing maintenance strategy. If the same gearbox, seal system, or motor keeps failing, the plant should ask whether the issue is task frequency, task quality, operating practice, contamination control, design weakness, or spare part quality.
The process is mature when planners trust the data, technicians respect the orders, and engineers can use the history to change asset strategy.
Governance rules that keep the process from backsliding
Most plants don't lose control because they lack software. They lose control because nobody protects standards after launch.
A usable governance checklist includes:
- Creation authority. Define who can submit requests and who can convert them into approved work orders.
- Approval rules. Set clear limits for emergency release, planned approval, and deferred work.
- Field standards. Make asset ID, symptom, priority, craft, and safety steps mandatory where applicable.
- Closeout discipline. Require confirmation of findings, work performed, labor, parts, and follow-up actions before final closure.
- Data audits. Review a sample of open and closed orders on a regular cadence for completeness and coding quality.
- Role accountability. Assign ownership for request quality, planning quality, scheduling compliance, and KPI review.
- Template maintenance. Update common failure templates when actual jobs reveal better diagnostics or missing precautions.
A pharmaceutical site illustrates why governance matters. If maintenance, engineering, and operations each use different naming or approval logic, deviations and rework multiply quickly. Once a shared standard is enforced, the same work order system becomes useful for maintenance planning, compliance evidence, and failure review.
Reliable plants don't treat work orders as paperwork to be closed. They treat them as technical records that drive maintenance execution and asset decisions. That shift is what turns a backlog-driven maintenance group into a reliability program.
If the current work order process is creating backlog, repeat failures, or poor CMMS data, Forge Reliability offers a free reliability assessment to identify where the workflow, asset strategy, and maintenance data structure need to change first.


