
A maintenance manager gets the same radio call again. The process pump on a critical line is down, production is stacking up, and the crew is already rolling the spare into place. Last outage, the team changed the seal. The time before that, they replaced the coupling. The pump returned to service both times. The failure pattern did not.
That is what recurring failure looks like in a plant. The damaged part changes, but the cause chain stays in place.
Root cause failure analysis is the discipline used to break that cycle. It goes past symptom-based troubleshooting and asks a harder question. What had to be true for this pump to fail in this way, at this time, under these operating conditions? In practice, that means proving causality, not collecting likely explanations.
That distinction matters on the floor. A failed bearing, leaking seal, high vibration alarm, or hot motor winding is a failure mode or a symptom. None of those, by themselves, explain why the asset keeps dropping out of service. The underlying cause may involve several conditions acting together: pipe strain after a maintenance job, suction instability at low tank level, poor lubrication control, and a PM task that checked vibration but never verified alignment. Teams that stop at the first believable answer usually replace parts faster. They do not eliminate repeat failures.
At Forge Reliability, we treat RCFA as a thinking process before we treat it as a method. The tools matter, but the hard part is separating correlation from cause in a plant where bad actors rarely show up one at a time. A pump may fail at the seal, while the evidence points upstream to operating practice, installation error, or an asset selected for the wrong duty. That is why failure elimination starts with clear failure definition, disciplined fact gathering, and a cause path the team can verify in service. For a useful frame on recurring behavior over time, see these equipment failure patterns and the six failure curves.
Table of Contents
- Beyond the Band-Aid Why Recurring Failures Demand RCFA
- When to Initiate a Root Cause Failure Analysis
- Choosing the Right RCFA Method for the Job
- The RCFA Workflow A Step-by-Step Example
- Effective Data Collection for Equipment Diagnostics
- From Cause to Cure Corrective Actions and Verification
- Integrating RCFA into Your Reliability Program
Beyond the Band-Aid Why Recurring Failures Demand RCFA
A recurring pump failure usually looks random only from a distance. Up close, the pattern is often obvious. The same pump runs hot after washdown shifts. The same bearing housing shows signs of contamination. The same work order history says “replace seal,” “replace bearing,” or “return to service,” but never explains why the damage happened.

That's where root cause failure analysis earns its keep. Instead of asking what part broke, RCFA asks what chain of conditions made the failure possible. On a process pump, that chain might include off-design operation, cavitation, pipe strain, poor alignment, lubricant contamination, or a maintenance practice that resets the machine without correcting the source of stress.
What reactive repair misses
Replacing the damaged part solves the symptom. It doesn't solve recurrence.
A pump with repeated seal failures is a good example. The seal may be the failed component, but the actual problem may sit upstream in the process or installation. If suction conditions are unstable, if the shaft is moving because of misalignment, or if operators are cycling the unit in a way the seal system can't tolerate, another seal replacement won't change the outcome.
Practical rule: If the same asset fails in the same way more than once, the plant likely has a cause problem, not a parts problem.
Plants that want to move out of firefighting mode need a structured way to judge whether the failure belongs to early life behavior, wearout, or an operating pattern. That broader context is useful when reviewing equipment failure patterns across the six common curves.
What RCFA changes on the plant floor
A strong RCFA process changes the conversation in meetings and in work orders.
- From replacement to elimination: The team stops closing jobs with “bearing changed” and starts asking what damaged the bearing.
- From opinions to evidence: Mechanics, operators, and engineers test explanations against data, physical condition, and event sequence.
- From local fixes to system fixes: The plant addresses the machine, the work practice, and the management condition that allowed the failure to repeat.
That last point matters most. A recurring breakdown is rarely just a machine problem. It usually reflects a system that accepted weak evidence, rushed startup, or incomplete follow-through.
When to Initiate a Root Cause Failure Analysis
A pump trips on low suction pressure during the night shift. Maintenance resets it, changes a worn seal the next morning, and production gets back online. Two weeks later, the same pump fails again. At that point, the question is no longer whether the seal was bad. The question is whether the plant is looking at a part failure, an operating problem, or a process condition that keeps creating the same damage.

RCFA should start when the cost of guessing is higher than the cost of investigating. That decision usually comes down to three factors. Consequence, repeatability, and uncertainty. If the event hurts production, threatens safety, or keeps returning without a proven explanation, the plant needs more than a repair.
Clear triggers that justify the effort
A formal RCFA is warranted when one or more of these conditions show up:
- The failure repeats: The same asset fails in the same mode again, or sister assets start showing the same pattern after similar repairs.
- The business impact is high: The event causes lost throughput, overtime, missed shipments, or forced schedule changes.
- Risk exposure is unacceptable: The failure creates a safety hazard, environmental release potential, or a near-miss that cannot be closed with a simple work order.
- The asset is operationally critical: The machine sits on a bottleneck, utility header, or process step that the plant cannot easily bypass.
- The cause is still unproven: Performance degrades, vibration rises, temperatures drift, or trips increase, but the team cannot yet show a causal chain with evidence.
A recurring bearing failure on a main plant air compressor fits this screen. So does a transfer pump that keeps losing seals after startup changes. The repair may be routine. The pattern is not.
Why consequence matters as much as recurrence
Some events deserve RCFA the first time because the plant cannot afford a wrong conclusion. A single gearbox seizure on a packaging bottleneck can stop shipments. One lubrication system trip on a critical turbine auxiliary train can put the site in a vulnerable operating state. One pump failure on a hazardous service can create a containment problem even if maintenance can rebuild it in a day.
The mistake in these cases is treating the first visible failure as the root cause. A wiped bearing is a physical result. The underlying cause may be oil contamination from a breather location, a preload error during assembly, intermittent overload from process upsets, or a design condition that leaves no margin during startup. Good RCFA starts when the team needs to prove which of those drove the damage.
That distinction matters on the plant floor. Correlated symptoms show up fast. Proven causes take work.
A practical screening question
Use this question before opening the analysis:
If this exact event happens again next month, will the plant have a defensible reason for not investigating it today?
If the answer is no, start the RCFA.
Failure history helps make that call. Reviewing mean time between failure for the affected asset can show whether the event is an isolated defect or the early stage of a repeat pattern. MTBF will not identify the cause, but it helps the team decide when a nuisance failure has crossed into a reliability problem that needs evidence, not another replacement.
Choosing the Right RCFA Method for the Job
Teams waste time when they overcomplicate a simple failure. They also miss root causes when they force a simple tool onto a complex event. The method has to fit the failure.
For industrial assets, RCFA is strongest when event reconstruction is combined with structured methods like 5 Whys, fishbone diagrams, and fault tree analysis. Fault tree analysis is especially useful because it shows how lower-level cause combinations can lead to a top-level failure event, as described in this overview of root cause analysis methods for industrial assets.
RCFA Method Selection Guide
| Method | Best For | Complexity | Example Use Case |
|---|---|---|---|
| 5 Whys | Narrow failures with a likely single causal path | Low | Repeated motor overload after a process change |
| Fishbone diagram | Multi-factor failures that need structured brainstorming | Medium | Pump vibration involving alignment, operation, lubrication, and installation questions |
| Fault tree analysis | High-consequence failures with interacting causes | High | Turbine trip, compressor shutdown logic event, or utility system failure |
Use 5 Whys when the causal path is narrow
5 Whys works well when the team can trace one path backward without too many branching conditions. It's useful for a recurring pump coupling failure, for example, if the evidence points toward a straightforward path such as poor alignment after each maintenance intervention.
The mistake is treating 5 Whys like a script. Asking “why” five times doesn't guarantee a root cause. If the answers are generic, opinion-based, or unsupported by evidence, the team is only documenting assumptions.
A better use of 5 Whys looks like this:
- Start with the event: Pump tripped on high vibration.
- Ask what directly caused it: Coupling insert failed.
- Trace to the condition: Angular misalignment increased load.
- Trace to the practice: Alignment was checked cold only.
- Trace to the latent issue: No standard existed for thermal growth verification.
That last step matters because the actual prevention action isn't “replace insert.” It's changing the alignment process.
Use fishbone when the team needs a broad cause map
Fishbone, or Ishikawa analysis, is useful when the failure could sit in several categories at once. For a recurring gearbox issue on a conveyor, the branches might include machine condition, lubrication method, operating load, installation practice, and environmental contamination.
This method is strong early in the investigation because it keeps the team from locking onto one favorite theory too soon. It's weak when teams stop at brainstorming and never test what they listed.
Fishbone is for generating possible causes. It is not proof by itself.
Use fault tree analysis when multiple conditions can combine
Fault tree analysis is the right choice when a top event depends on several lower-level conditions aligning. A turbine control trip, nuisance shutdown on a compressor train, or failure in a safety-related interlock often falls into this category. One signal by itself may not cause the event. Two or three conditions together might.
In those situations, the logic matters. AND and OR relationships force the team to ask whether the event required multiple failures, one failure with one permissive, or one hidden design weakness plus an operating trigger.
Plants that need a more visual example of this logic can review fault tree analysis examples for industrial reliability work.
The RCFA Workflow A Step-by-Step Example
A practical RCFA follows a disciplined sequence. Define the problem. Gather facts. Generate possible causes. Verify the most likely cause. Implement corrective actions. Validate the result. The investigation isn't complete until the fix is proven in the field, following the standard workflow described in this manufacturing-focused RCFA guide.
Use a recurring conveyor gearbox failure as the example. The gearbox drives a critical packaging conveyor. It has returned to service after repair more than once, but each time the bearing damage comes back.
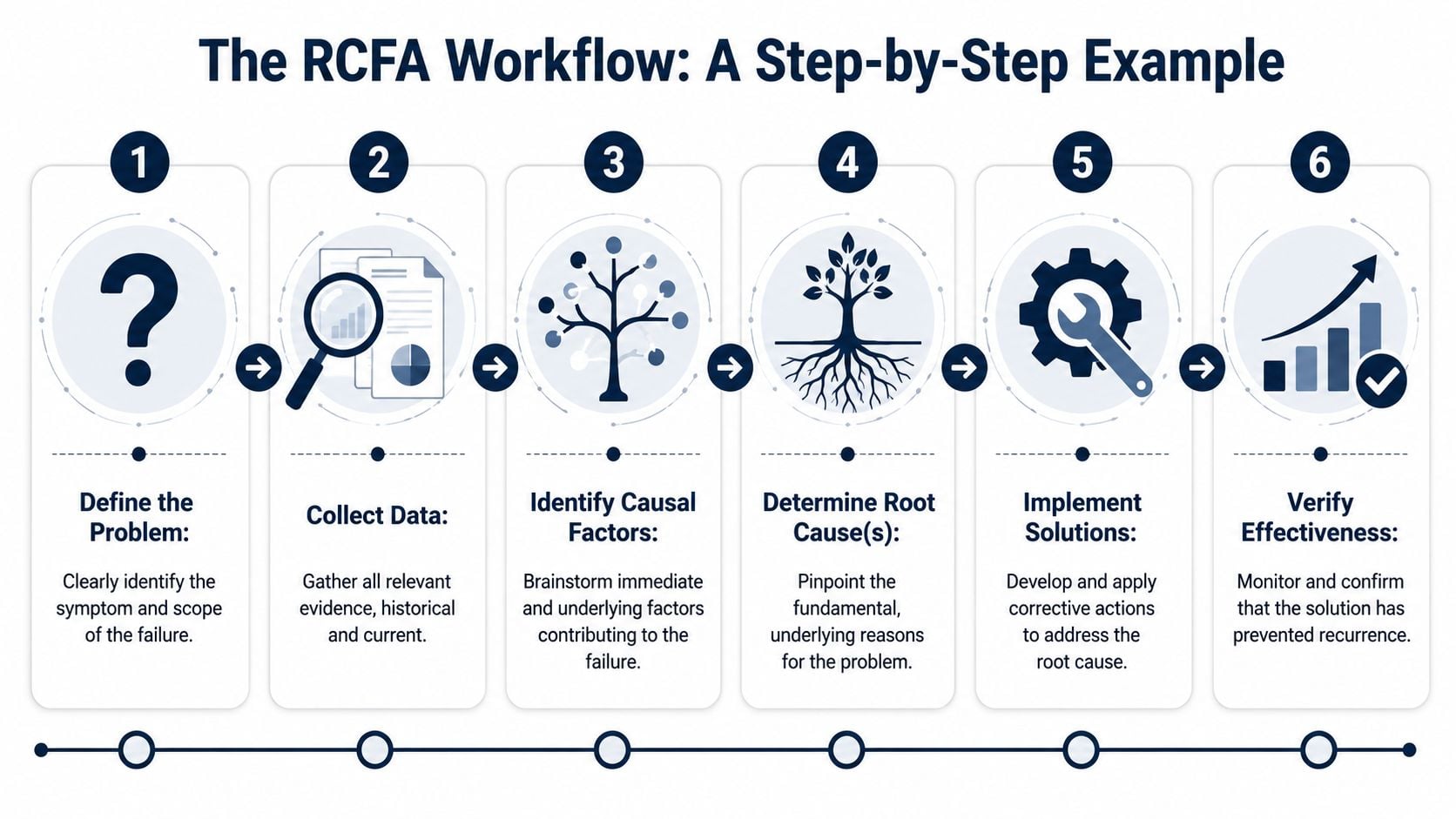
Step 1 and Step 2 define the failure and gather facts
The first job is to define the event precisely. Not “gearbox failed.” That statement is too broad to investigate well. A usable problem statement sounds more like this: gearbox on conveyor C-101 shut down due to bearing seizure after rising temperature and noise during production.
Then the team gathers facts without trying to force a conclusion early. On this gearbox, that would include:
- Condition data: Vibration history, temperature trends, oil sample condition, and any thermal images.
- Maintenance history: Work orders, previous rebuild notes, lubrication records, and parts used.
- Operating context: Product load, upset conditions, jam events, cleanup practices, and shift reports.
- Physical evidence: Bearing surfaces, oil appearance, breather condition, seals, and housing cleanliness.
A lot of investigations fail here because the team collects only what's easy. They pull the failed bearing, see damage, and stop. That only tells them how the part died. It doesn't tell them why the system allowed it.
Step 3 and Step 4 test the cause chain
Once facts are collected, the team reconstructs the event sequence. What changed before temperature rose. When was the oil topped up. Was the breather damaged before or after the shutdown. Did the vibration trend shift after a maintenance intervention or after a process upset.
For this gearbox, the likely branches include contamination, lubrication condition, misalignment, overloading, and assembly practice. The investigation should test each branch against real evidence.
A disciplined team would ask:
- Was the bearing damaged by overload, lubrication failure, contamination, or installation error?
- What evidence supports each path?
- Which factor, if removed, would have prevented recurrence?
In this example, the strongest evidence points to contaminated lubricant. The oil sample shows debris and moisture. The housing breather is damaged. The gearbox sits in a washdown area. Work order history shows repeat oil top-ups, but no action on contamination control. That combination is stronger than a generic conclusion like “bearing wear.”
Field note: If the proposed root cause can't be tied to a physical mechanism and an event sequence, it's probably still a symptom.
Step 5 and Step 6 implement and validate
The corrective action should match the cause chain, not the visible damage. For this conveyor gearbox, replacing the bearing is a repair. Replacing the damaged breather with a contamination-control design, correcting the lubrication practice, and updating inspection standards are corrective actions.
Validation is what closes the loop. After return to service, the team monitors oil condition, housing temperature, vibration trend, and breather condition through normal operation. If those indicators remain stable and the failure pattern disappears, the RCFA is doing its job. If not, the team goes back and challenges its assumptions.
Effective Data Collection for Equipment Diagnostics
An RCFA is only as good as the evidence behind it. Opinions are cheap on the plant floor. Evidence takes work. The team has to collect machine data, process data, maintenance history, and operator observations in a way that can support or reject each hypothesis.
For equipment failures, the investigation shouldn't stop at the failed component. The team has to trace backward through lubrication, contamination, alignment, and maintenance processes until the originating weakness is identified, as explained in this reliability reference from Texas A&M.
Rotating equipment needs condition evidence and context
On pumps, motors, compressors, and gearboxes, condition evidence usually starts with vibration, lubrication, and temperature.
- Vibration data: Helps separate patterns that suggest imbalance, misalignment, looseness, or rolling element bearing distress.
- Oil analysis: Shows contamination, lubricant degradation, and wear debris that point toward the damage mechanism.
- Thermal evidence: Identifies localized heating, overloaded zones, and possible friction-related problems.
- Motor and load context: Confirms whether the machine is being stressed by process demand, poor control, or repeated starts.
A motor-driven pump is a good example. Rising vibration at the bearing housing means something is wrong, but not necessarily what. The trend only becomes useful when it is tied to alignment history, base condition, process flow, and operator observations. Teams looking for a more detailed diagnostic breakdown can review vibration analysis of motors in industrial service.
Modern inspection programs also benefit from better visual evidence and anomaly review. In quality-sensitive environments or lines with repeated component damage, teams may borrow ideas from strategies for AI-powered defect detection to improve how they capture and classify visible defects around equipment and process outputs.
Static equipment failures need process evidence
Static equipment requires a different evidence set. A fouled heat exchanger, leaking vessel nozzle, or corroded piping circuit won't reveal itself through vibration signatures alone.
The team should pull:
- Process trends: Temperature, pressure, differential pressure, flow, and product condition before and during the event
- Inspection evidence: Wall thickness readings, internal condition reports, visual findings, and leak path observations
- Cleaning and operating history: What changed in duty, chemistry, cycle length, or cleaning method
- Human evidence: Operator logs, shift notes, and CMMS comments that explain what happened in the field
Good RCFA work includes operator interviews early, before memory gets rewritten by the meeting room.
That last point gets overlooked. Sensor data tells the machine story. Operators often tell the event story. Both matter.
From Cause to Cure Corrective Actions and Verification
A lot of teams do solid failure analysis work and still don't eliminate recurrence. The breakdown happens in the handoff between diagnosis and action. Someone identifies a likely cause, maintenance replaces a part, operations restarts the line, and the plant declares victory too early.
The harder standard is this: the corrective action should remove the verified cause that allowed the event. In complex systems, that requires a causal chain, evidence behind the chain, and a fix aimed at the cause that would prevent recurrence if removed, as noted in the root cause analysis overview discussing causal verification.
A repair is not the same as a corrective action
Take a pump with repeated bearing failures caused by contamination ingress.
Replacing the bearing is the repair. Installing a proper sealing or breather solution, correcting washdown exposure, updating lubrication practice, and changing inspection criteria is the corrective action. If the analysis showed a process or management weakness, those items belong in the action list too.
Good corrective actions usually work at more than one level:
- Physical level: Change the hardware, setup, or operating condition that produced the damage.
- Human level: Correct the work practice, inspection routine, startup method, or maintenance task.
- Latent level: Fix the standard, planning process, training gap, or design assumption that allowed the practice to continue.
This is one area where a provider like Forge Reliability can fit as one option among others, especially when a plant needs field diagnostics, condition monitoring, and formal RCFA support tied directly to implementation.
Verification is where most teams fall short
The plant has to prove the fix worked. That means deciding in advance what evidence will count as success.
For a gearbox contamination problem, verification may include stable oil condition, acceptable vibration behavior, normal temperature profile, and no repeat distress during comparable service. For a pump alignment issue, the team may check post-repair vibration, coupling condition, and operation across the normal load range.
A useful verification plan answers four questions:
- What variable should improve if the root cause was removed?
- What period of operation is enough to judge the result?
- Who owns the follow-up checks?
- What will trigger reopening the analysis?
A fix that isn't verified is still a hypothesis.
Integrating RCFA into Your Reliability Program
Root cause failure analysis shouldn't live as a stack of closed reports in a file share. It should feed the rest of the reliability system. A new failure mode discovered in RCFA belongs in FMEA. A bad maintenance task uncovered in RCFA belongs in PM optimization. A repeated operating upset belongs in operator standards and control strategy review.
That's how plants move from isolated problem solving to a reliability program that learns. Teams building that structure often use broader references like SaberTask's preventive maintenance guide to align failure elimination work with day-to-day maintenance discipline, then map the findings into a larger 12-month reliability program roadmap.
RCFA works best when operations, maintenance, and engineering all own the result. The machine failed in one place. The cause often lives somewhere else.
If recurring pump, gearbox, motor, or compressor failures are still being handled as one-off repairs, it's time to challenge the pattern. Forge Reliability offers a free reliability assessment to help plants identify repeat-failure drivers, strengthen diagnostics, and build corrective actions that hold up in the field.


