
A lot of teams in pulp and paper mills are dealing with the same pattern right now. A roll bearing starts running hot during a heavy production stretch, operators fight sheet stability, maintenance gets pulled into an urgent call, and the machine finally trips after the defect has already spread into alignment, lubrication, and product-quality problems. By the time the machine is back, the plant hasn't just replaced a bearing. It has burned hours, stressed the crew, and lost confidence in the plan.
That cycle is common because mills punish weak maintenance systems. The process is wet, abrasive, hot, chemically aggressive, and tightly linked from one unit to the next. A small fault in a fan motor, seal water line, felt roll bearing, or liquor pump can move fast and hit far more than the asset that failed.
The answer isn't “do more predictive maintenance” in the generic sense. The answer is to connect specific mill failure modes to the right diagnostic signature, then build a response process that the site can sustain with the people and budget it has.
Table of Contents
- The High Cost of Unreliability in a 24/7 Industry
- The Unique Reliability Landscape of a Mill
- Critical Assets and Their Common Failure Modes
- Targeted Diagnostics for Early Fault Detection
- From Data to Decisions with FMEA and RCM
- Your Starter Plan for Predictive Maintenance
- Build Your Mill's Future on Reliability
The High Cost of Unreliability in a 24/7 Industry
The failure usually starts small. A press roll bearing develops contamination from moisture ingress. Lubrication film weakens, the defect grows, and vibration increases enough to disturb sheet runnability. Operators first see the symptom as instability. Maintenance later finds the cause in the bearing housing.
In a pulp and paper mill, that single defect doesn't stay single for long. A bearing issue can trigger a sheet break, force a shutdown, overheat a coupling, damage a journal, and leave the crew rushing through restart under pressure. The maintenance cost is only one part of the event. The harder hit is usually the chain reaction through production, quality, and schedule.
Practical rule: In continuous-process mills, the true cost of a failure is almost never the part that failed. It's the process disruption around it.
That's why reactive maintenance loses in this industry. Modern mills were built to run continuously, not to stop gracefully every time a small defect gets ignored. Plants trying to control costs by delaying inspections often end up paying more through secondary damage, emergency labor, rushed parts decisions, and unstable machine conditions after restart. Teams looking for a disciplined way to break that cycle usually start with tighter work selection and failure elimination, not just more wrench time. A useful reference on that side of the problem is this guide to maintenance cost reduction strategies.
Electrical losses add another hidden layer. A failing connection in a motor control center, poor drive setup, or overloaded fan motor may not trip immediately, but it raises heat, stresses insulation, and shortens the margin before the next upset. Mills that are serious about uptime usually pair mechanical reliability work with the basics of reducing industrial electrical losses, because wasted electrical energy and premature component failure often show up together.
Why this hits harder in mills
Pulp and paper mills don't operate like batch plants with comfortable recovery windows. They run with interdependent assets, narrow process tolerances, and production targets that don't wait for perfect maintenance timing. Once one critical component slips, everybody feels it. Operations loses stability, maintenance loses control of the work queue, and planners lose the ability to schedule the next shutdown cleanly.
The Unique Reliability Landscape of a Mill
Some industries have harsh equipment. Pulp and paper mills combine almost every harsh condition in one place. Corrosive chemicals in pulping areas, saturated humidity around wet ends, high heat in dryer sections, abrasive fiber slurry in stock prep, and long operating runs all attack equipment in different ways at the same time.
That operating context matters because Overall Equipment Effectiveness, or OEE, is more than a reporting metric in a mill. It's a practical measure of how availability, performance, and quality hold together under constant process stress. A machine can stay “running” while poor bearing condition, unstable vacuum, or weak steam control steadily erodes performance and quality.
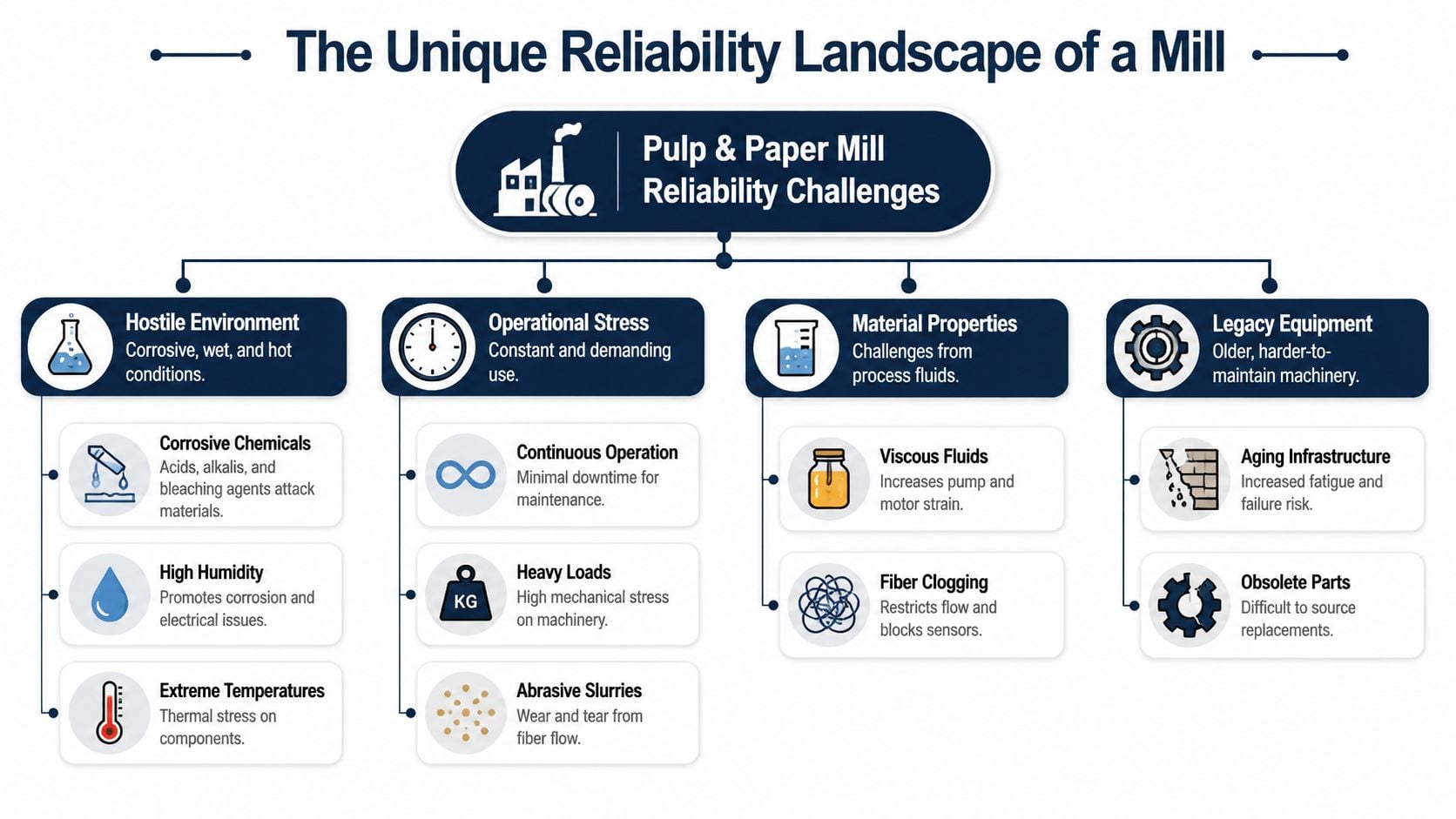
Why the environment changes everything
A mill's environment changes what good maintenance looks like. Standard motor storage practices, ordinary sensor placement, and generic lubrication intervals often fail because the local conditions are anything but standard.
Three examples show up repeatedly on the plant floor:
- Wet-end exposure: Water intrusion gets into bearings, terminal boxes, and junction points. The defect may first appear as increased bearing temperature, grease washout, or intermittent electrical faults.
- Chemical attack: White liquor, black liquor, bleaching chemicals, and process vapors degrade elastomers, coatings, seals, and some metal surfaces. The wrong material choice survives in the storeroom but not in service.
- Thermal cycling: Dryer section rolls, steam systems, and hot process lines expand and contract constantly. That movement works fasteners loose, shifts alignment, and opens small leaks that become larger failures.
A good industry overview from Forge Reliability on reliability support for pulp and paper operations reflects that reality well. The problem isn't just “aging equipment.” It's equipment aging under combined mechanical, chemical, thermal, and moisture stress.
Why one failure rarely stays local
Resource intensity raises the stakes. A typical Kraft mill uses about 20,000 gallons of water per ton of pulp and requires about 9,000 MJ per ton of pulp, while a mechanical pulp mill uses about 8,000 gallons per ton and about 2,000 kWh per ton of pulp (National Academies review of pulp and paper resource intensity). When a washer pump, filtrate pump, refiner drive, seal water system, or recirculation loop degrades, the loss isn't isolated to maintenance hours. It also shows up in water handling, energy use, and process stability.
A mill can stay online with a sick asset for a while. It usually can't stay efficient.
That's one reason reliability teams in mills need to think system-first. A clogged stock line affects pump load. A pump load change affects motor temperature. Motor temperature shifts bearing life. Bearing degradation changes vibration. Vibration starts changing product quality before the asset fails. In this environment, condition monitoring works best when the team understands the process connection, not just the machine.
Critical Assets and Their Common Failure Modes
Modern U.S. paper mills evolved to produce as much as 5,000 tons per day, and the industry has invested about $130,000 per employee per year in plant and equipment to sustain that output (historical paper mill scale and capital intensity). At that scale, small defects in common assets become expensive very quickly.

Paper machine rolls and dryer section equipment
Rolls fail in familiar ways, but mills often miss the early warning because operators first notice product symptoms rather than machine symptoms.
Common failures include:
- Felt roll bearing wear: Moisture ingress, grease contamination, and poor sealing drive fatigue and corrosion. In vibration data, the first clue is often a rise in bearing defect frequencies such as BPFI, or Ball Pass Frequency Inner race, when the inner race starts degrading.
- Dryer bearing distress: Heat and lubricant oxidation reduce film strength. High-frequency acceleration data often shows early bearing distress before overall velocity rises enough to trigger a simple route alarm.
- Roll unbalance or buildup: Sheet contamination, coating buildup, or uneven wear creates 1x running-speed vibration. If that condition is left alone, it starts loading bearings and couplings harder than the base machine design intended.
A practical paper machine example is the suction roll area. The machine may show recurring sheet instability, but the mechanical root cause can be bearing looseness or imbalance that only appears clearly under loaded operating conditions.
Pumps in stock, filtrate, and liquor service
Pumps in mills fail because the process attacks them from several directions at once. The fluid can be abrasive, corrosive, entrained with gas, or variable in consistency.
The usual trouble spots are:
- Mechanical seal failure: Black liquor, stock, and abrasive contaminants wear seal faces, plug flush paths, or upset pressure balance. Teams often replace seals repeatedly without fixing shaft movement, base softness, or seal water quality.
- Cavitation and recirculation damage: Restricted suction, poor level control, clogged strainers, or process changes produce a distinct broadband sound and vibration pattern. Left alone, cavitation erodes impellers and destabilizes flow.
- Bearing overload from pipe strain: This one gets missed constantly. Maintenance changes a seal or coupling, but the actual issue is suction or discharge piping forcing the casing out of alignment.
For teams working in these environments, machine-specific vibration analysis for pulp and paper equipment is often the fastest way to separate hydraulic problems from mechanical ones.
Refiners and stock preparation equipment
Refiners are unforgiving. They run with high loads, changing stock characteristics, and narrow internal clearances. A small upset can turn into expensive contact damage fast.
Watch for these failure modes:
- Plate clashing: Feed inconsistency, control issues, or mechanical looseness can close the gap unexpectedly. The machine often shows a sudden change in vibration character and process load.
- Shaft and bearing distress: High radial and axial loads, combined with contamination, accelerate fatigue.
- Foundation or looseness problems: These machines transfer force into the base. If hold-down conditions degrade, the vibration pattern gets messy and misleading, and analysts can chase the wrong fault.
The first question on a refiner isn't “what does the spectrum say?” It's “did the process upset the machine, or did the machine upset the process?”
Motors, drives, and power transmission
Motor-driven assets dominate reliability work in mills because they're everywhere. Pumps, fans, conveyors, refiners, and roll drives all depend on them, and many operate under variable load.
Frequent failures include:
- Bearing fluting in VFD-driven fan motors: Electrical discharge through the bearing creates washboard-like damage patterns. In service, the motor often develops high-frequency vibration and a distinct tonal roughness before the damage becomes visible during teardown.
- Rotor or stator electrical defects: These can appear as heat rise, unstable current, or torque irregularity before there is a complete trip.
- Misalignment and belt problems: Sheave wear, improper tension, and soft foot produce sideband activity and increased radial vibration.
Digesters, vessels, and steam systems
Static equipment still drives reliability risk in mills, especially where thermal cycling, chemical exposure, and steam service combine.
Key concerns include:
- Weld cracking and fatigue: Repeated thermal movement creates stress at attachment points, supports, and weld transitions.
- Valve leakage and steam trap failure: These don't always stop production immediately, but they destabilize temperature control and waste energy.
- Condensate handling problems: Poor condensate removal in steam-heated sections can create water hammer, erratic heating, and secondary damage to piping and supports.
Targeted Diagnostics for Early Fault Detection
General predictive maintenance language doesn't help much on a mill floor. Reliability teams need to know which diagnostic method sees a fault first, what the fault looks like in the data, and what action should follow. That's the difference between a saved outage and an interesting report nobody uses.
Because motors are major electricity consumers in mills, applying condition monitoring alongside adjustable-speed drives on pumps and fans can deliver 30–35% savings on pumps and fans while also reducing mechanical wear and improving process control (EPRI guidance on motors and adjustable-speed drives in pulp and paper mills).

When vibration analysis is the first tool to use
For rotating assets, vibration is usually the first line of defense because it tells the team whether the problem is mechanical, structural, or process-induced.
Use vibration first for:
- Rolling element bearing faults: Look for defect frequencies such as BPFI, BPFO, and harmonics, especially with sidebands if load modulation is present.
- Imbalance: A strong 1x running-speed peak with stable phase often points to buildup, roll contamination, or mass eccentricity.
- Misalignment: Increased 1x and 2x components, plus axial activity, often indicate coupling or sheave alignment problems.
- Looseness: Multiple harmonics and an unstable spectrum can indicate structural looseness, foot issues, or bearing fit problems.
A felt roll bearing is a good example. If acceleration and envelope data start showing inner-race activity while process operators report rising sheet instability, the right response isn't “watch it.” It's to verify lubrication condition, inspect seals, and plan the correction before the defect migrates into the housing or shaft.
When heat, sound, and oil tell the story faster
Not every problem starts as a clean vibration signature.
Infrared thermography works well when resistance, friction, or insulation breakdown creates heat before vibration changes enough to notice. That makes it useful for motor control centers, cable terminations, overloaded disconnects, bearing housings, and steam system anomalies.
Ultrasound is often the fastest way to catch compressed air leaks, steam leaks, early bearing friction, and cavitation. In mills, it's especially useful where background noise is high and access windows are limited. Teams that want a better field workflow for that work can use a structured approach to ultrasonic leak detection in industrial systems.
Oil analysis earns its keep on gearboxes, circulating systems, and any lubricated asset where contamination drives failure. Water ingress, viscosity change, oxidation, and wear debris usually tell the maintenance team what happened before teardown confirms it.
A hot terminal, a noisy steam leak, and water in a gearbox don't need the same technology. Treating every fault with one tool is how programs get expensive and shallow.
The same logic applies to connected monitoring. Data visibility matters, but only if the team knows what must be watched continuously and what only needs periodic route work. For leaders building those practices, the broader discipline behind real-time security essentials is a useful reminder that continuous monitoring only works when thresholds, ownership, and response are defined.
Choosing the right method for the fault
A simple decision table helps teams avoid over-instrumenting low-value assets.
| Fault pattern | Best first diagnostic | What to look for |
|---|---|---|
| Bearing defect on a roll or fan | Vibration analysis | BPFI, BPFO, harmonics, high-frequency impact |
| Cavitation in a process pump | Ultrasound and vibration | Broadband noise, unstable hydraulic signature |
| Loose or overheating electrical connection | Infrared thermography | Temperature delta at lugs, breakers, or terminals |
| Water contamination in a gearbox | Oil analysis | Moisture, degraded lubricant condition, wear particles |
| VFD-related motor bearing damage | Vibration plus motor electrical review | High-frequency bearing roughness, fluting pattern on inspection |
One practical note matters here. Continuous systems don't need every asset monitored all the time. They need the right assets monitored with the right method and a response path that maintenance planners can execute. That's where many mills stall. They collect data but don't convert it into planned work.
A reliability provider such as Forge Reliability can support that conversion by combining route-based and continuous monitoring with diagnostic methods such as vibration, thermography, ultrasound, oil analysis, and motor current signature analysis where the site lacks internal coverage.
From Data to Decisions with FMEA and RCM
Condition data without a decision process usually creates noise. Teams end up with too many alerts, too many “watch” calls, and not enough clarity on which assets deserve immediate intervention. That's where FMEA, or Failure Mode and Effects Analysis, and RCM, or Reliability-Centered Maintenance, stop being academic exercises and start saving time.
FMEA forces the team to define three things clearly. What can fail, how it fails, and what the plant experiences when it does. RCM then uses that information to decide the right maintenance policy for each failure mode. That may be condition-based work, scheduled replacement, redesign, operator inspection, or run-to-failure if the consequence is low enough.
A practical FMEA example on a headbox pump
A headbox pump is a good example because its reliability affects both process stability and product quality.
A simplified FMEA discussion around that asset usually includes failure modes such as:
- Mechanical seal leakage: Effect is loss of containment, housekeeping risk, and possible product upset.
- Bearing degradation: Effect is vibration growth, shaft movement, and eventual pump trip or secondary seal failure.
- Impeller wear or hydraulic degradation: Effect is unstable flow and poorer process control.
- Coupling misalignment: Effect is excess bearing load, heat, and shortened seal life.
The important step isn't listing every possible failure. It's ranking consequence and detectability so the team spends effort where it matters. If the headbox pump has no practical standby and poor flow control directly affects sheet quality, it deserves more aggressive monitoring than a redundant utility pump.
For teams formalizing that analysis, this practical guide to FMEA for maintenance decisions is a useful reference.
Why RCM matters more when staffing is thin
The staffing side of this problem is real. ABB reports that over the past 15–20 years, pulp and paper mills have moved from having one process control engineer per machine to one per site, highlighting a growing skills shortage in an increasingly digitalized market. That shift changes the maintenance equation.
When fewer experienced people are available, tribal knowledge becomes a liability. The site can't rely on one veteran technician remembering which fan always runs hot in humid weather or which refiner starts acting up after a stock change. RCM helps capture that knowledge as a repeatable maintenance logic.
If a mill needs a hero to stay reliable, it doesn't have a reliability system yet.
That's why “fix everything” doesn't work. A mill with limited planners, analysts, and controls support needs a method to decide where precision matters most. FMEA and RCM provide that method.
Your Starter Plan for Predictive Maintenance
Most mills don't fail because they lack technology. They fail because the program starts too wide, alarms aren't trusted, and nobody defines who owns the response. A starter plan works when it stays narrow enough to execute and disciplined enough to scale.

Start with one area and one workflow
A strong pilot usually focuses on one production area where failures are visible and critical. Many mills choose a dryer section, a stock prep train, or a set of liquor and filtrate pumps because those areas combine consequence with repeatable access for inspection.
A practical rollout looks like this:
- Define the pilot boundary. Choose one machine area, not the whole mill.
- Rank the assets inside it. Separate critical single-point failures from assets with practical redundancy.
- Match each asset to a primary diagnostic. Don't default every asset to vibration. Some need ultrasound, thermography, or oil analysis first.
- Collect baseline data under known operating conditions. A baseline taken during startup, upset, or light load is often misleading.
The baseline matters more than many teams think. Without it, alarm limits become guesses, and analysts spend too much time sorting normal process variation from actual machine change.
Build alarm response before buying more technology
The second half of the program is where most sites struggle. They get data, but they don't build action rules.
A workable alarm-response model includes:
- Who reviews the data: route technician, analyst, reliability engineer, or outside specialist.
- What counts as actionable: defect frequency growth, temperature rise, repeatable ultrasonic change, contamination trend.
- How the work is assigned: inspection, planned repair, immediate intervention, or continued observation.
- When the loop closes: someone confirms the finding after repair and updates the failure history.
A few practical rules keep the pilot from drifting:
- Protect the schedule: If every alarm becomes an emergency, planners stop trusting the system.
- Keep operator input in the loop: Operators often see process symptoms before analysts see a confirmed fault pattern.
- Document saves carefully: The team should record what was found, how it was confirmed, and what action prevented the failure.
One more point is worth stating directly. A good pilot doesn't try to prove that every asset needs permanent sensors. It proves that the site can detect faults early, plan work better, and learn which assets justify continuous coverage.
Build Your Mill's Future on Reliability
Pulp and paper mills don't get reliable by collecting more data than the team can use. They get reliable when the site links real failure modes to the right diagnostics, then turns those findings into planned maintenance decisions. That's the discipline that separates a program from a pile of readings.
The operating environment requires that discipline. Mills run in moisture, heat, contamination, chemical exposure, and constant process interdependence. Under those conditions, the weak point usually isn't just a component. It's the gap between detection and action.
That matters in a market this large. The global paper and pulp mills industry was projected at about $622.0 billion in 2026, with 9,545 businesses worldwide and revenue declining at a 4.0% CAGR over the prior five years according to IBISWorld's global paper and pulp mills industry outlook. In a market of that scale, even modest improvements in uptime, maintenance execution, and energy discipline can create a real competitive edge.
The mills that improve fastest usually don't start with a massive transformation project. They start with a critical area, a clean asset list, a practical diagnostic plan, and a maintenance workflow people will follow. Then they expand from evidence, not enthusiasm.
If a mill is dealing with repeat failures, unclear priorities, or a predictive maintenance program that isn't producing planned work, a free assessment from Forge Reliability is a practical next step. It gives maintenance and operations leaders a clear view of critical assets, likely failure modes, diagnostic gaps, and where a focused reliability effort can reduce unplanned downtime.


