A critical process pump fails on a Thursday night shift. Operations reports low flow, the motor trips, and maintenance replaces the bearing that came apart. Two weeks later, the same pump is back on the floor with vibration alarms climbing again. By the third failure in the quarter, nobody believes the last repair “fixed” anything.
That pattern is common in plants that treat the failed part as the whole story. The bearing failed, so the work order closes with “bad bearing.” The pump returns to service, production resumes, and the same conditions that damaged the bearing remain untouched. The visible failure gets corrected. The system that enabled it stays in place.
For reliability teams trying to define contributing factors, that distinction matters. A recurring pump failure rarely comes from one isolated defect. It usually comes from a stack of conditions such as alignment drift, contaminated lubricant, poor startup practice, wrong spare selection, weak planning data, or missing operator checks. The point of an investigation isn't to produce a smarter label for the failed part. It's to identify which conditions increased the chance of failure, sped it up, or made the outcome worse, then convert those findings into maintenance and asset management actions that stick.
Table of Contents
- The Cycle of Recurring Failures
- What Are Contributing Factors in Incident Investigation
- The High Cost of Ignoring Contributing Factors
- Contributing Factors in Industrial Equipment Failures
- Tools to Uncover and Document Contributing Factors
- Turning Analysis into Corrective Maintenance Actions
- Frequently Asked Questions About Contributing Factors
The Cycle of Recurring Failures
The maintenance manager usually sees the cycle before anyone names it. Pump P-204 fails. The crew swaps the inboard bearing, checks rotation, and returns the unit to service. The CMMS history shows the same repair code from the last outage, but the pressure to restart production is stronger than the pressure to investigate.
A month later, the same pump starts running hot. The seal begins to leak, vibration rises, and the coupling guard comes off for another fast repair. This time the discussion turns to bad parts, then to operator handling, then to age. None of those explanations are completely wrong. None of them are precise enough to stop the recurrence.
That's where many teams misuse the phrase “root cause.” They identify the last failed component and treat it as the answer. In reliability work, that approach creates the illusion of closure while the failure pathway stays open. The bearing becomes the headline, even though the underlying story may include pipe strain, chronic misalignment, grease incompatibility, suction instability, and a PM route that checks noise but not precision lubrication or base condition.
Field reality: Repeat failures often look random from the control room and highly predictable from the asset history.
One useful early warning sign is unstable failure frequency. If the same asset keeps consuming labor and parts, the team doesn't just have a repair problem. It has a pattern problem. Reviewing how to calculate mean time between failure helps expose that pattern, but MTBF alone won't explain why the interval keeps collapsing.
What keeps the cycle going
- Fast closure pressure: Production needs the pump back, so the team restores function before it restores reliability.
- Weak failure coding: The work order records “bearing failed” but misses operating context, lubricant condition, and installation details.
- No system correction: The repair replaces the damaged part, not the conditions that damaged it.
The practical consequence is simple. The plant keeps paying for the same failure in different forms: downtime, overtime, emergency parts, cleanup, and credibility loss between operations and maintenance.
What Are Contributing Factors in Incident Investigation
A clear definition matters because the phrase is often used loosely. In reliability investigations, contributing factors are the conditions that made the incident more likely, made it happen sooner, or made the result worse. They matter even when removing one of them wouldn't completely prevent the event.
A practical definition for plant teams
The cleanest technical distinction comes from reliability practice. A contributing factor is not necessarily the primary cause of a failure; in root-cause analysis, it is any condition that influences the outcome by increasing likelihood, accelerating timing, or worsening severity, while eliminating it alone would not necessarily prevent the event (Reliabilityweb on cause vs. contributing factor).
That definition is more useful than a vague dictionary answer because it helps plant teams decide what to do next. If a pump bearing failed after contaminated grease, poor shaft alignment, and repeated operation away from best efficiency point, each of those may be a contributing factor. Some belong to maintenance execution. Some belong to operations. Some belong to engineering design.
The distinction becomes easier when the team looks at a simple conveyor example:
- The incident is a conveyor stopping under load.
- The immediate cause might be a seized motor bearing.
- The contributing factors could include improper lubrication frequency, excessive belt tension, dust blocking cooling passages, and delayed response to rising temperature.
- The root cause sits deeper, at the level where removing the underlying issue would prevent recurrence.
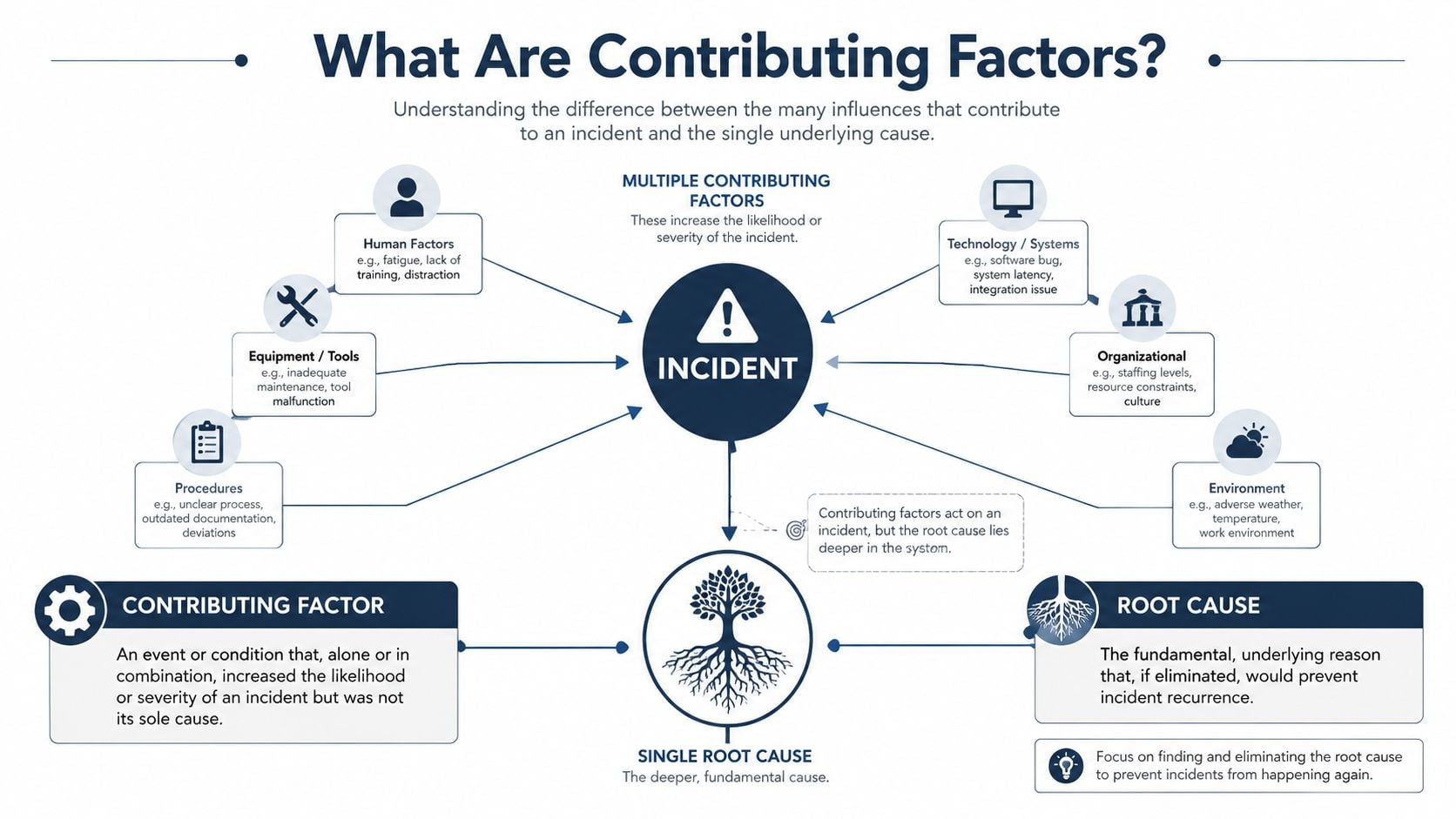
Teams that need a structured path for that distinction usually work through formal root cause analysis services or apply the same logic internally with discipline.
Root cause, causal chain, and contributing factors
A useful way to define contributing factors is to separate three layers.
| Layer | What it means | Pump example |
|---|---|---|
| Failure event | What happened | Bearing overheated and failed |
| Contributing factor | What increased likelihood, accelerated timing, or worsened severity | Grease contamination, pipe strain, poor alignment |
| Root cause | The deeper condition that must be removed to prevent repeat occurrence | No precision lubrication standard, no alignment verification after reinstall |
A failed part answers what broke. Contributing factors answer why that part was exposed to failure conditions.
Many investigations often go off track. Teams ask for one answer when the actual answer is often a combination. A good investigation doesn't collect every possible imperfection around the event. It identifies the conditions that had a credible relationship to the outcome and can be supported by evidence.
The High Cost of Ignoring Contributing Factors
Plants don't suffer from lack of repair effort. They suffer from repairs that stop at the visible defect. That choice has a cost because the same contributors stay active in the background.
Why single-cause thinking keeps failures alive
A peer-reviewed analysis of incidents found that only 20.71% of adverse events were tied to a single factor, while 79.29% involved more than one contributory factor. The most common were cognitive limitations, communication failures, and poor adherence to policies (peer-reviewed incident analysis). That study was not about industrial pumps, but the lesson translates well to plant reliability. Significant events usually come from combinations, not isolated defects.
That matters in a maintenance setting because recurring failures almost never stay confined to one work order. A pump that repeatedly loses bearings often drags in seal damage, shaft wear, coupling deterioration, and process instability. If the team fixes only the terminal symptom, the rest of the failure path remains ready for the next run cycle.
What plants leave on the table
Ignoring contributing factors creates avoidable trade-offs:
- Downtime keeps returning: The asset comes back, but the operating risk doesn't leave with the repair.
- Maintenance labor gets trapped in repeat work: Skilled technicians spend time restoring the same machine instead of improving system reliability.
- Decision quality degrades: Management sees many completed work orders and assumes control, even though the same failure mode stays active.
A narrow investigation also weakens budget decisions. If the problem is coded as “bad bearing,” planners may stock more bearings. If the actual issue is contamination entering through poor storage, overgreasing, or seal failure, the plant buys more of the wrong solution.
Practical rule: If the same asset fails in a similar way more than once, the team should assume the previous investigation stopped too early.
There's also a strategic cost. Repeating technical fixes without system corrections trains the organization to accept chronic instability as normal. Once that happens, operators work around bad assets, planners normalize emergency parts, and supervisors expect weekend callouts. Teams that want to reduce maintenance costs have to break that pattern at the investigation stage, not after another quarter of reactive repairs.
Contributing Factors in Industrial Equipment Failures
A centrifugal pump offers a good working example because its failures often expose interactions between equipment condition, operating practice, parts control, and planning discipline. Consider a process pump handling a service that changed over time. The current symptom is a leaking mechanical seal, but the maintenance history also shows increased vibration and repeated bearing work.
The pump did not fail for one reason

The obvious event is seal leakage at the stuffing box area. Many teams would stop there and replace the seal. A better investigation asks what conditions increased seal face distress, shaft movement, heat generation, or dry running exposure.
The logic behind modern failure analysis is to weigh interacting variables rather than assume one obvious cause explains the event. That same analytical logic has been tied to broader quantitative methods that became practical with the arrival of the digital computer in the early 1960s, and it's directly relevant to reliability work because diagnosis often depends on variables such as maintenance quality, operating conditions, asset criticality, and human factors (History Matters on quantitative analysis).
For this pump, the likely contributing factors may include:
- Latent equipment condition: The rotor is slightly imbalanced. Vibration isn't high enough to trigger immediate shutdown, but it increases seal face movement and bearing load.
- Operating factor: The pump occasionally runs with poor suction conditions during startup. Even short dry or near-dry operation can damage seal faces.
- Maintenance factor: Stores issued an incorrect seal material that fit dimensionally but wasn't appropriate for the current fluid and temperature exposure.
- Human factor: A newer operator followed a general startup routine, not the pump-specific procedure for venting and confirming suction availability.
- Organizational factor: The process fluid changed, but no formal review updated seal specification, BOM data, or PM task content.
How the factors interacted
None of those items alone fully explains the failure. Together, they create a credible chain.
The wrong seal material reduces margin. Startup practice exposes the seal to poor lubrication. Rotor condition adds vibration. The PM route detects leakage only after damage becomes visible. The BOM still lists the old material, so the same spare gets reordered. Each factor feeds the next.
A useful way to read this case is to ask two questions for every observation:
| Observation | Why it matters |
|---|---|
| Seal faces show heat distress | Suggests inadequate lubrication or dry running exposure |
| Bearings show distress history | Points to shaft movement, misalignment, or lubrication problems |
| Spare part matches dimensions but not service | Indicates a materials control gap, not just a parts issue |
| Operators vary in startup sequence | Indicates procedural weakness, not individual blame |
That's how teams should define contributing factors in real plant language. Not as abstract categories, but as specific conditions connected to evidence and action. The point isn't to create a long list. The point is to show how the pump became vulnerable.
A recurring pump failure is often a system failure wearing a component-level disguise.
Tools to Uncover and Document Contributing Factors
Most plants already know the common RCA tools. The issue isn't tool availability. It's how quickly teams stop using them once they find a plausible technical answer.
Using 5 Whys without stopping too early
The 5 Whys method is useful when the team applies it past the failed part.
For the pump case, the first answers might look familiar:
- Why did the pump trip? Because the bearing overheated.
- Why did the bearing overheat? Because lubrication condition was poor.
- Why was lubrication condition poor? Because grease was contaminated and overapplied.
- Why did that happen? Because the PM task gave quantity guidance that was vague and technicians used mixed grease sources.
- Why was the task vague and grease mixed? Because the lubrication standard, storage controls, and job plan were never updated after asset standardization changed.
That chain doesn't prove every answer by itself, but it pushes the team beyond the failed component and into controllable system conditions.
Building structure with fault trees and Apollo thinking
A deeper investigation needs a way to separate trigger, condition, and organizational weakness. That's where branching logic helps.
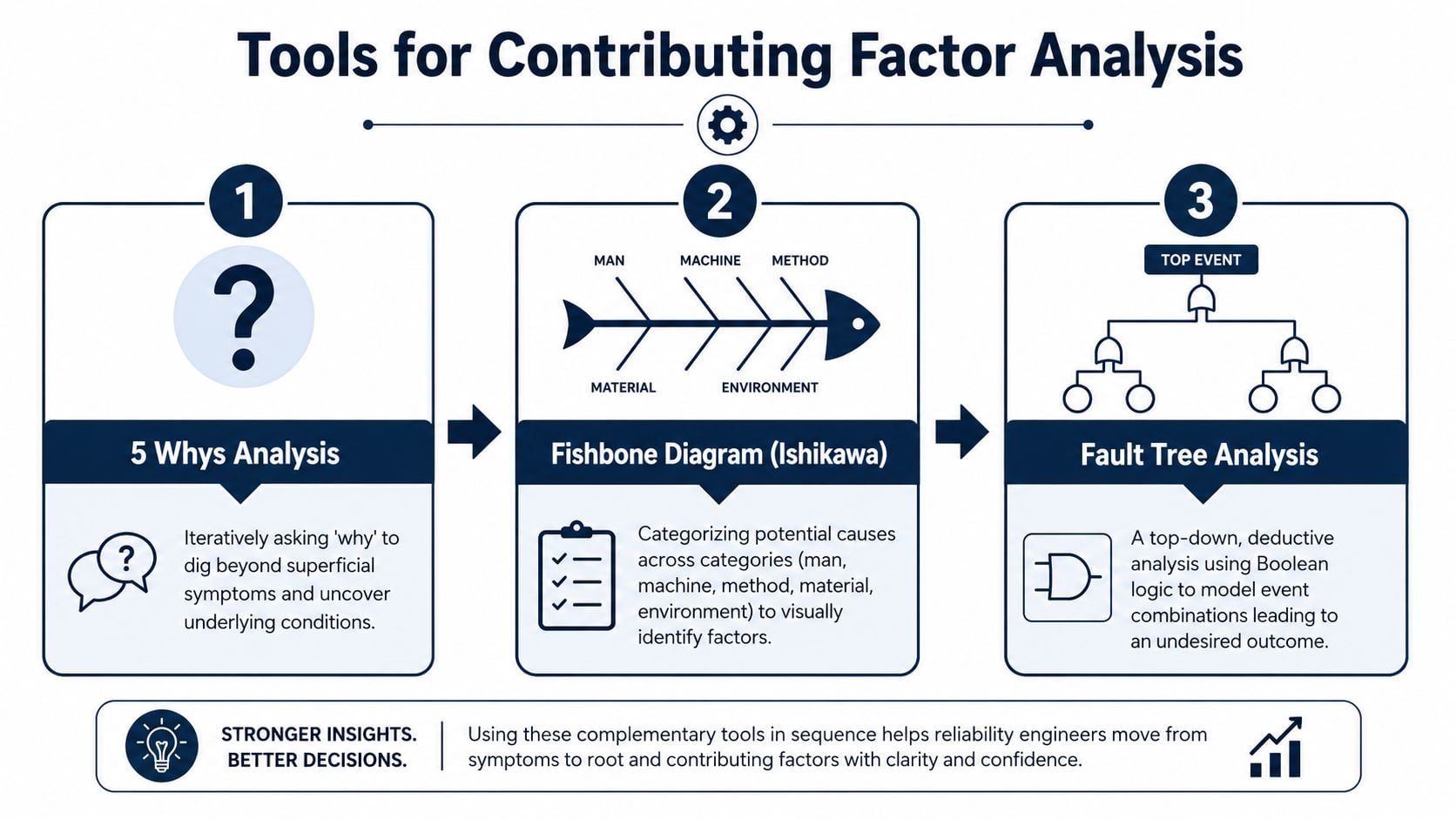
Fault tree analysis works well when several conditions must align for failure to occur. The top event might be “pump seal failed in service.” Branches then break into mechanical loading, process upset, installation error, and material mismatch. That forces the team to show combinations instead of defaulting to a single storyline. A practical reference for teams building that logic is this guide to examples of fault tree analysis.
Apollo-style thinking adds another useful discipline. It requires evidence behind each cause-and-effect relationship. That's important because one of the hardest calls in any investigation is deciding when to stop at contributing factors and when to continue into deeper root cause analysis. In reliability work, the challenge is real because a failure may involve immediate triggers, latent system issues, and organizational contributors that need different tools to uncover (discussion of when to continue deeper analysis).
One option plants use for structured investigations is Forge Reliability's root cause failure analysis work, which applies methods such as 5-Why, fault tree analysis, and fishbone logic to separate physical, human, and systemic contributors.
A documentation format that works in practice
What fails in many plants is not the meeting. It's the record. If contributing factors aren't documented in a consistent format, they won't convert into action.
A simple working template should include:
- Factor statement: What condition contributed to the event.
- Factor type: Human, procedural, equipment, material, operating, or organizational.
- Evidence: Inspection finding, trend, interview, work order history, parts record, or operating log.
- Control decision: Eliminate, reduce, monitor, or accept.
- Owner and due date: Who changes the system.
Don't log “operator error” or “maintenance issue” as a final factor. Those labels stop thinking instead of documenting evidence.
Turning Analysis into Corrective Maintenance Actions
An investigation only earns its keep when findings alter the maintenance system. That means each contributing factor must map to a change in the CMMS, EAM, spare parts structure, operating procedure, or maintenance strategy.
Map each factor to a system change
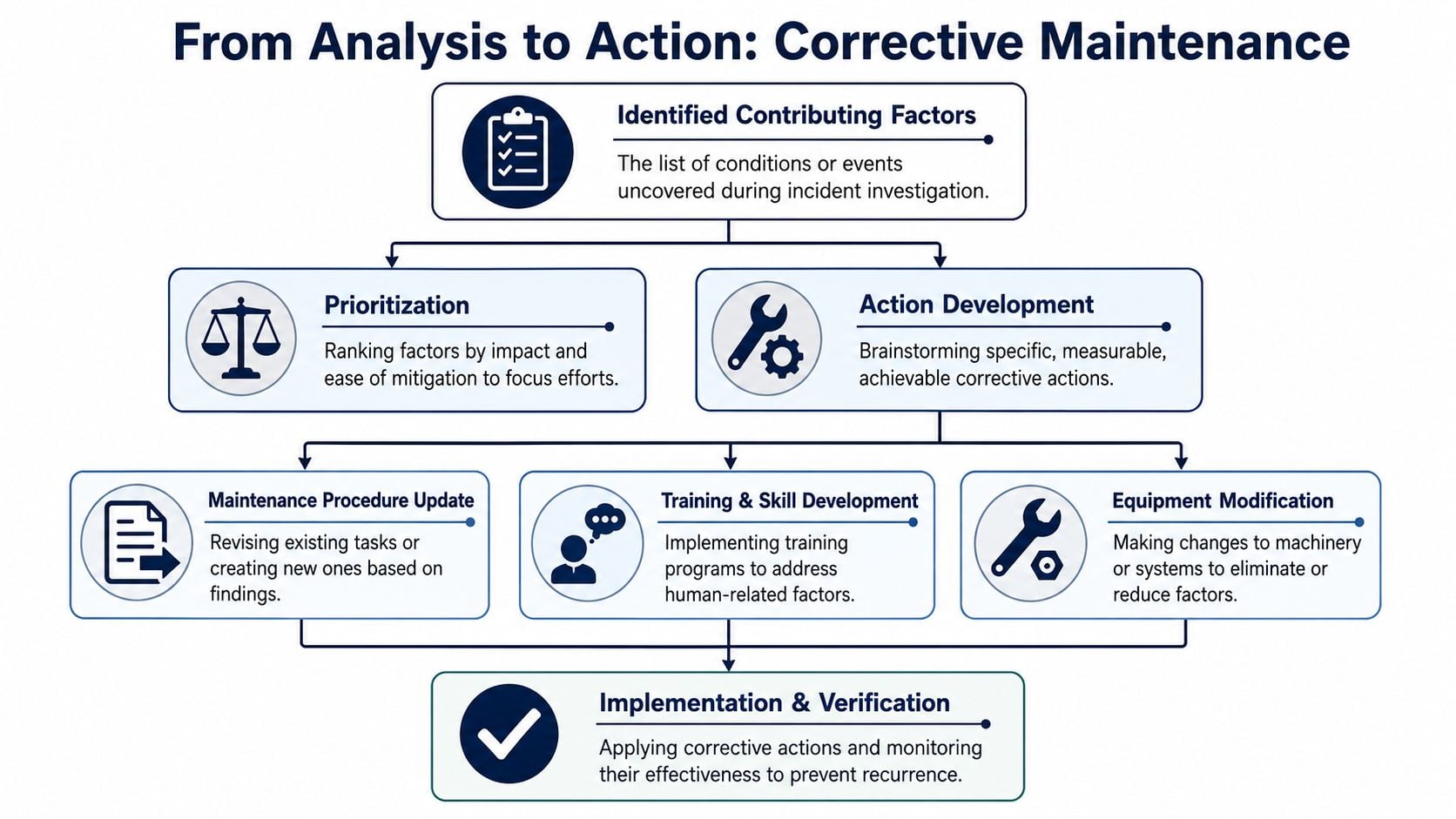
Take the pump case again. If the investigation identifies poor lubrication control, the corrective action isn't “be more careful.” The action is to revise the PM task with lubricant type, quantity, method, and contamination controls. If the issue is wrong seal material, the action is a BOM correction, approved parts restriction, and stores review. If startup practice contributed, the action is an updated operating procedure with a verifiable pre-start check.
That's the difference between analysis and closure. Closure ends the meeting. Analysis changes the system.
CMMS and EAM actions that prevent repeat failures
The most effective translations are specific and trackable:
- PM interval adjustment: If degradation appears between routes, the team changes task frequency or inspection method.
- Job plan revision: Precision alignment, torque values, lubrication details, and acceptance criteria get added to the work instruction.
- BOM update: Incorrect or obsolete parts are removed, and approved replacements are tied to the asset record.
- Failure code cleanup: The CMMS gets better coding so future work orders separate symptom, failure mode, and contributor.
- Training work orders: Operations or maintenance receives assigned retraining tied to the exact procedure gap.
- Engineering action: If piping loads or base condition are part of the problem, a modification request gets created instead of hiding the issue in maintenance history.
A practical screen for each action is simple. Can someone assign it, schedule it, verify it, and audit it later? If not, the factor is documented but not controlled.
Teams that want those actions tied back to maintenance strategy often use an RCM implementation guide to decide whether the answer belongs in preventive maintenance, condition monitoring, redesign, operating discipline, or spare parts governance.
Frequently Asked Questions About Contributing Factors
What's the difference between a contributing factor and a finding
A finding is an observation supported by evidence. A contributing factor is a finding that has a meaningful relationship to the event. “Seal faces were heat checked” is a finding. “Pump started without adequate seal flush” may be a contributing factor if records, physical evidence, or interviews support that connection.
How many contributing factors are too many
There's no useful fixed number. The wrong number is “one” when the event clearly required several conditions, and it's also wrong to list every imperfection around the machine. A good investigation stops when each documented factor has evidence, a plausible causal link, and an action path. If a factor can't change a decision, it may belong in notes, not in the final contributor list.
Who should identify contributing factors
The best group is cross-functional and close to the asset. That usually means maintenance, operations, reliability, and planning. Stores or engineering should join when parts control, design decisions, or process changes are involved. The supervisor should keep blame out of the room so people describe what happened, not what sounds safest.
A mature reliability program doesn't just repair failures. It defines contributing factors clearly, proves them with evidence, and converts them into system changes that prevent recurrence.
If recurring pump, motor, or process equipment failures are still driving emergency work, a free assessment from Forge Reliability can help identify the contributing factors hiding inside the current maintenance system and turn them into practical reliability actions.