
A maintenance manager usually meets this question after a bad week. A critical pump trips without warning, production loses a batch, and the team says the asset was already on condition monitoring. The alarm never crossed its limit. The machine still failed.
That's where the actual condition based maintenance vs predictive maintenance debate starts. Not in a glossary. On the plant floor, with a work order backlog, limited staff, and equipment that doesn't fail on a neat schedule.
For most plants, the decision doesn't come down to which label sounds more advanced. It comes down to two hard realities. First, how much warning time exists between the first detectable sign of a problem and functional failure. Second, whether the plant has the data quality and analytics maturity to turn signals into useful forecasts. A wastewater lift station pump, a cleanroom air handler motor, and a high-speed compressor can all justify different strategies even inside the same facility.
A blended reliability program usually works best. Some assets need simple thresholds and disciplined response. Others need trending, forecasting, and tighter planning windows. Teams sorting through that choice may also find it useful to compare predictive vs preventive maintenance approaches before deciding where CBM and PdM fit.
Table of Contents
- Beyond the Alarm The Core Maintenance Strategy Debate
- The Foundational Difference A Tale of Two Triggers
- Matching Diagnostic Techniques to Failure Modes
- The P-F Curve Your True Planning Horizon
- Data Architecture and Implementation Realities
- Making the Final Decision Cost ROI and Next Steps
Beyond the Alarm The Core Maintenance Strategy Debate
A centrifugal pump on a process line can look healthy right up to the moment it becomes a production problem. Operators hear a little more noise than usual. The casing runs warmer. Flow starts to drift. Nothing crosses the alarm setpoint, so no one pulls the machine from service. Then the seal fails, the bearing follows, and the shutdown becomes unplanned.
That's not unusual. It's what happens when a plant assumes every monitoring program provides the same level of warning. It doesn't. Some programs tell the team that a bad condition exists now. Others try to tell the team when that condition is heading toward failure.
CBM and PdM are often treated as interchangeable terms in meetings, budget requests, and vendor pitches. They aren't the same operationally. A threshold-based vibration alarm on a process pump is one thing. A system that trends vibration, temperature, lubrication condition, and work history to estimate failure timing is something else entirely.
Plant-floor reality: If the first actionable signal arrives too late to order parts, reserve labor, and use a planned outage, the strategy may be technically correct and still operationally weak.
A chemical plant offers a good example. A standby pump on cooling water service may do well with a simple condition-based approach because the consequence of short interruption is manageable and replacement is straightforward. A primary reactor feed pump is different. If that machine has a short failure-development window, the team needs more than alarms. It needs planning runway.
Three factors usually separate useful programs from disappointing ones:
- Asset consequence: A nuisance trip on a utility fan isn't the same as a failure on a process bottleneck.
- Failure behavior: Slow degradation supports simpler monitoring. Rapid degradation demands earlier detection.
- Response capability: A good signal still fails the plant if planners, storeroom staff, and operations can't act on it.
The debate isn't academic. It affects outage risk, maintenance scheduling, and whether the next failure shows up as a work order or an emergency callout.
The Foundational Difference A Tale of Two Triggers
The cleanest way to understand condition based maintenance vs predictive maintenance is to ask a single question. What event triggers maintenance action?
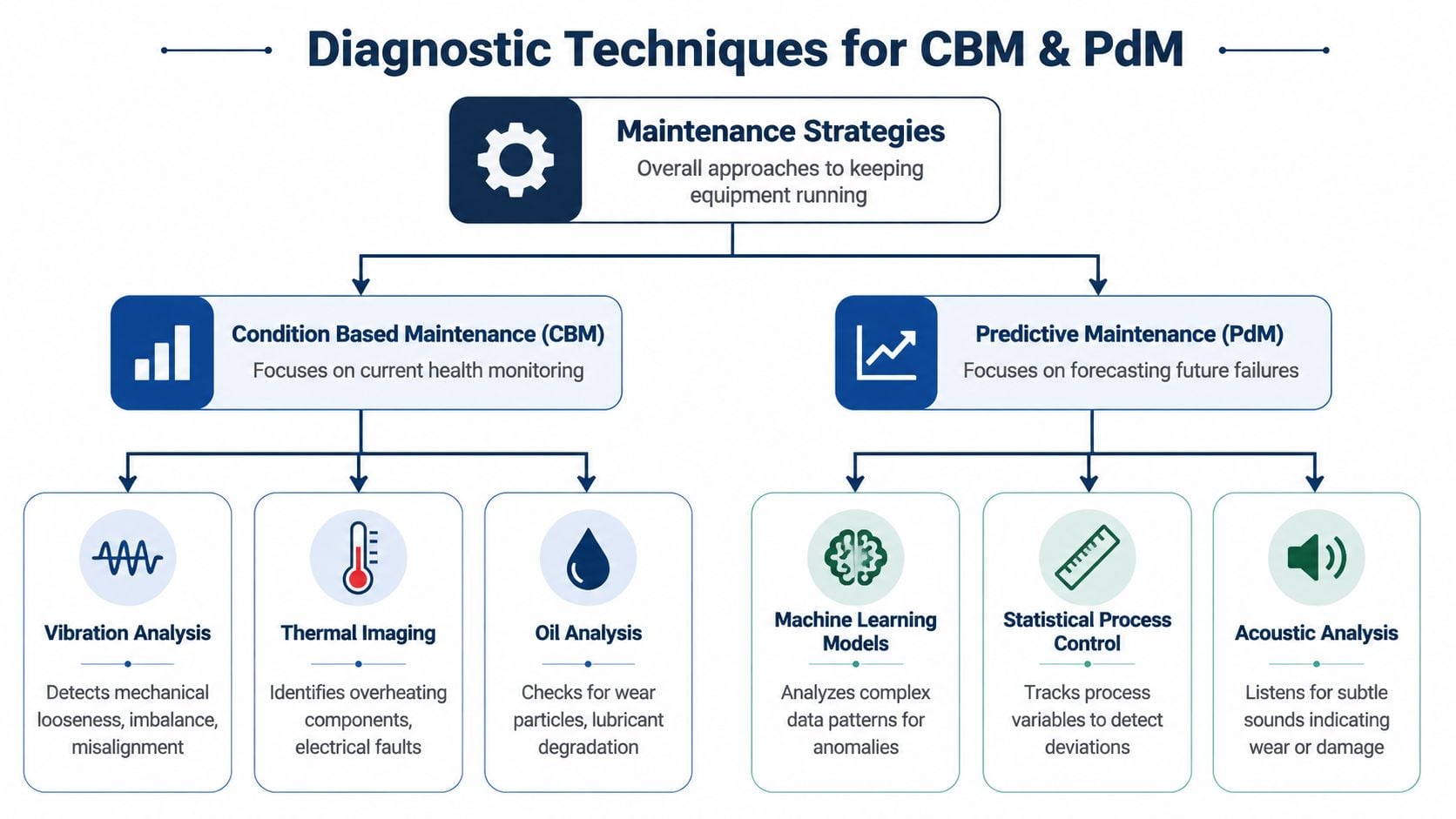
According to this technical explanation of CBM and PdM, condition-based maintenance triggers work when a measured condition crosses a defined threshold, while predictive maintenance uses trends and analytics to estimate when failure will occur. In practical terms, CBM is threshold-driven and reacts after a degradation signal appears, while PdM is trend-driven and aims for more lead time.
A quick side by side comparison
| Aspect | Condition-Based Maintenance | Predictive Maintenance |
|---|---|---|
| Primary trigger | Measured value crosses a limit | Trend and analysis indicate future failure timing |
| Core question | Is the asset outside acceptable condition now? | When is the asset likely to fail if nothing changes? |
| Typical data use | Current-state alarm or alert | Historical plus current data for forecasting |
| Response style | Inspect, confirm, and act after threshold breach | Plan work before threshold breach becomes severe |
| Best fit | Assets with slower failure development or lower analytics maturity | Critical assets where earlier planning time changes the outcome |
| Example | Gearbox temperature exceeds a set limit | Gearbox temperature trend rises alongside worsening oil condition |
This is the practical dividing line. CBM says, “the machine is now in an unacceptable state.” PdM says, “the machine is heading toward failure, and the team still has time to plan.”
How the trigger changes the work order
Take a primary air handler motor in a pharmaceutical cleanroom. A CBM setup might rely on vibration and temperature alarms. If vibration exceeds the setpoint, maintenance receives a notification, inspects the motor, and decides whether to repair or replace it. That's useful. It prevents pure run-to-failure behavior.
A PdM setup treats the same asset differently. The team trends vibration over time, watches the rate of change, compares similar motors, checks lubrication history, and looks for alignment or load changes. The work order is triggered by a forecasted deterioration path, not only by a hard alarm.
That distinction changes planning in four ways:
- Parts readiness: PdM gives buyers and storeroom staff more time to secure bearings, seals, couplings, or a spare motor.
- Outage coordination: Operations can align the repair with sanitation, line changeover, or a planned shutdown.
- Scope quality: Planners can bundle alignment, balancing, and inspection work instead of sending a technician to chase a single alarm.
- Secondary damage control: Earlier intervention lowers the chance that a bad bearing becomes shaft damage, seal failure, or collateral coupling damage.
Plants often oversimplify this and say PdM is just “better CBM.” That's not the right framing. CBM is often the right answer where simple thresholds are enough. Teams building that foundation often start with a structured condition monitoring program before they attempt forecasting.
The trigger logic determines whether maintenance is merely informed or truly ahead of the failure.
Matching Diagnostic Techniques to Failure Modes
The diagnostic method doesn't automatically determine the strategy. The same technology can support either CBM or PdM, depending on how the plant uses the data. A handheld vibration route can feed a threshold alarm program, or it can support trending and failure forecasting. An infrared camera can identify a hot connection today, or repeated thermal images can reveal a steadily worsening pattern.
The same tool can support either strategy
A gearbox illustrates the difference well. In a basic CBM program, the team mounts a temperature sensor and sets an alarm for excessive heat. Once the gearbox crosses that threshold, maintenance inspects the unit, checks lubricant level, and schedules a repair if needed.
In a more mature PdM approach, the team combines thermal data with vibration patterns and lubricant condition. Instead of asking whether the gearbox is hot, they ask whether the heat rise is accelerating, whether wear debris is increasing, and whether the machine is moving toward lubrication failure or gear mesh damage.
A few common techniques show this split clearly:
- Vibration analysis: Used in CBM, it can trigger action when amplitude or frequency indicators exceed acceptable limits. Used in PdM, it trends defect frequencies, sidebands, and rate of change to estimate deterioration.
- Oil analysis: Used in CBM, it can flag contamination or severe wear that requires immediate response. Used in PdM, it can show a worsening wear pattern over time and support remaining-life decisions.
- Infrared thermography: Used in CBM, it catches overheating bearings, couplings, and electrical terminations. Used in PdM, it compares repeat images to identify drift before temperatures become critical.
- Ultrasound: Used in CBM, it detects air leaks, steam leaks, or localized bearing distress. Used in PdM, it helps trend early-stage friction changes before vibration grows obvious.
- Motor current signature analysis: Used in CBM, it helps confirm active electrical issues. Used in PdM, it supports deeper trending of rotor, stator, and load-related problems.
Technicians working with rotating equipment often start with motor vibration analysis practices because motors, pumps, and driven equipment expose many of these failure patterns clearly.
Failure mode examples that matter in real plants
Failure mode matters more than maintenance terminology. A plant doesn't maintain “CBM assets” and “PdM assets.” It manages bearing defects, cavitation, lubrication breakdown, looseness, misalignment, imbalance, electrical overheating, and gear wear.
Consider these examples:
| Equipment and failure mode | What CBM looks like | What PdM looks like |
|---|---|---|
| Process pump with cavitation | Alarm on vibration or suction condition after damage becomes noticeable | Trend vibration and process behavior to spot deterioration early enough to inspect suction conditions and impeller wear |
| Motor bearing with cage defect | Act when vibration or temperature exceeds limit | Trend bearing frequencies and severity progression to plan replacement before secondary damage |
| Gearbox with lubrication breakdown | Alarm on temperature or oil condition once problem is pronounced | Combine oil, thermal, and vibration trends to forecast when lubrication failure will threaten gear health |
| MCC connection with overheating | Thermal scan identifies hot connection requiring immediate correction | Repeat thermal inspections reveal a heating pattern before functional interruption occurs |
Practical rule: Choose the technique by failure mode first. Choose the monitoring strategy second.
A food and beverage facility offers a useful example. A washdown conveyor motor may face moisture intrusion, bearing degradation, and electrical connection issues. A simple threshold alarm might be enough if the motor is easy to replace and a spare is stocked. The main homogenizer drive is different. That asset usually deserves trend-based review because the production consequence is much higher, and the repair window may depend on sanitation and batch scheduling.
What doesn't work is collecting every possible signal from every asset without a failure-mode hypothesis. Plants end up with dashboards full of data and very little guidance. The better approach is narrower. Identify the dominant failure mode, decide which diagnostic method will detect it early, and then decide whether threshold response is enough or forecasting is worth the effort.
The P-F Curve Your True Planning Horizon
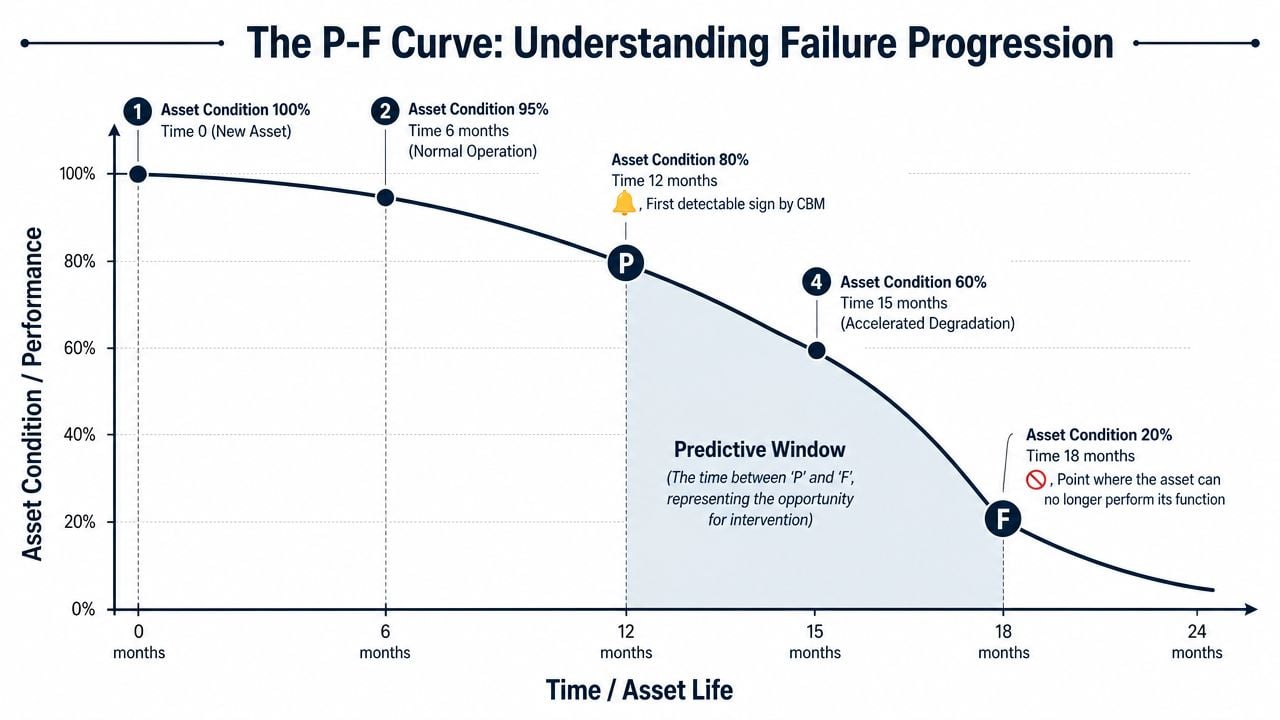
The most useful framework in condition based maintenance vs predictive maintenance isn't a sensor list. It's the P-F curve. This curve tracks the period between potential failure (P), when a defect first becomes detectable, and functional failure (F), when the asset can no longer perform its required function.
Why lead time matters more than labels
A long P-F interval gives the plant room to breathe. If a conveyor pulley bearing degrades slowly, a route-based inspection program may catch the problem with plenty of time to plan labor and parts. In that case, a straightforward CBM program can be enough.
A short P-F interval changes everything. Once the defect appears, failure may advance too quickly for a threshold alarm to provide useful planning time. That's where PdM becomes more than an analytics exercise. It becomes a scheduling tool.
One source notes that predictive maintenance has been used to identify defects 60–90 days in advance for rotating assets such as pumps, compressors, mixers, and conveyors. That matters because the extra planning window often determines whether the plant schedules the work during available downtime or gets forced into an outage.
A short P-F interval punishes slow decision-making. A long P-F interval rewards discipline more than sophistication.
Reading the curve on common rotating assets
A plant engineer doesn't need perfect mathematical precision to use the P-F concept. The key is understanding whether the failure mode develops over weeks, months, or much faster, and whether the current monitoring interval matches that reality.
A few examples make the point:
- Slow conveyor roller degradation: Monthly or periodic condition checks may be enough because deterioration tends to be visible and manageable before total function is lost.
- Pump bearing wear on critical process service: Periodic routes may work if degradation is gradual, but the strategy becomes risky when the asset runs near process limits or carries high production consequence.
- Compressor defects on bottleneck equipment: Continuous monitoring and stronger forecasting are often justified because the time between first detectable defect and functional loss may be too short for route-based response.
- Electrical overheating in switchgear or motor connections: Thermography can detect the issue, but the planning horizon depends on load profile, duty cycle, and whether the temperature rise is stable or accelerating.
Plants that struggle here often focus on technology before they understand the failure pattern. A better sequence is simpler:
- Define the asset function. What counts as failure in operations terms?
- Identify the dominant failure mode. Bearing distress, contamination, cavitation, electrical looseness, insulation breakdown, and so on.
- Estimate the likely P-F interval. Use plant history, technician observations, and known defect behavior.
- Match monitoring frequency to that interval. If the inspection cycle is too slow, the strategy won't work no matter how good the sensor is.
- Escalate only where the planning gain is real. Not every asset needs predictive modeling.
Teams working through failure development patterns can sharpen this process with equipment failure pattern guidance, especially when deciding which assets justify deeper monitoring.
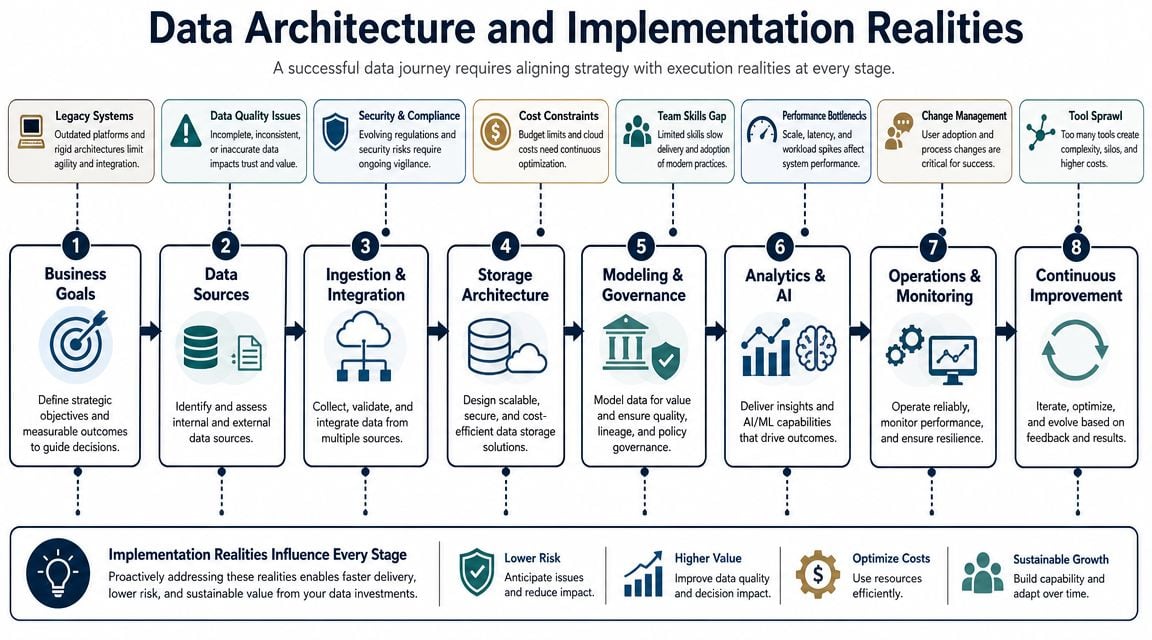
Data Architecture and Implementation Realities
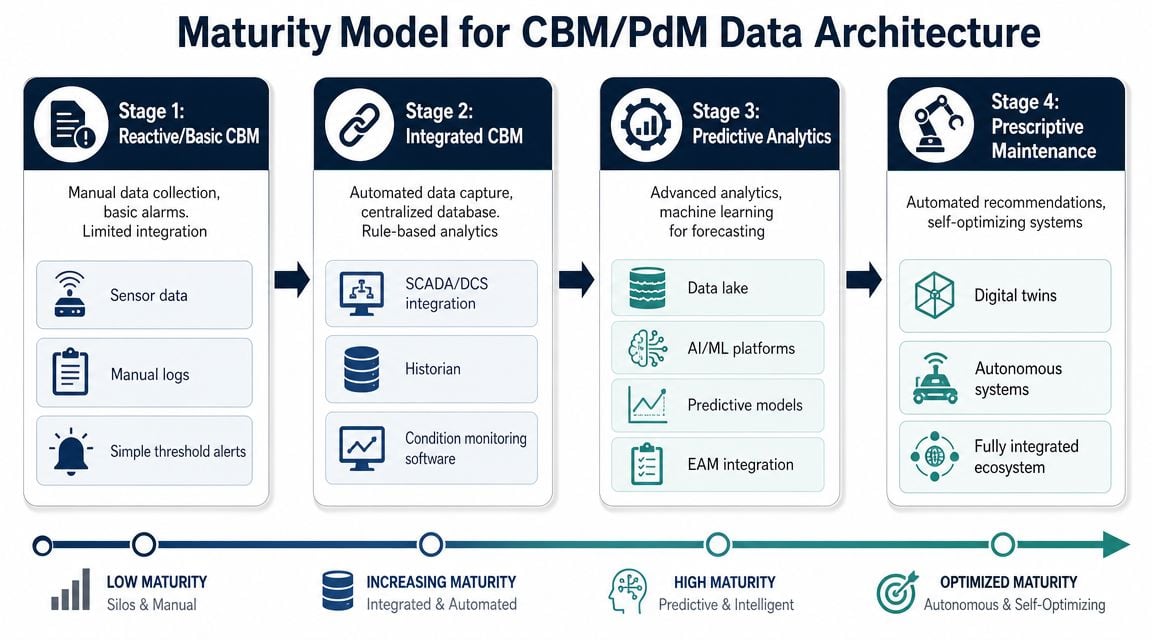
Most plants can launch basic CBM with the tools they already have. That's one reason it remains attractive. It's often the simpler and cheaper deployment path, relying on sensor thresholds and alarms rather than heavy analytics. By contrast, PdM depends on historical condition data and rate-of-change trends to estimate remaining useful life, which makes it more exact but also more data- and analytics-intensive, as outlined in this explanation of predictive and condition-based maintenance.
What basic CBM actually needs
A practical CBM stack doesn't have to be elaborate. For many sites, it starts with a limited number of critical assets, clearly defined alarm points, and technicians who know what response each alarm should trigger.
The basic ingredients are straightforward:
- Reliable measurements: Vibration, temperature, oil condition, ultrasound, or electrical checks need to be repeatable. Inconsistent collection kills confidence fast.
- Alarm logic: Thresholds should reflect real machine behavior, not arbitrary values copied from another site.
- Work order path: If an alarm doesn't create inspection, planning, and repair action, the monitoring effort becomes a reporting exercise.
- Asset context: Sensor data without equipment nameplate, service duty, speed, load, and maintenance history is hard to interpret.
A multi-site food plant often starts here. Route-based monitoring on fillers, motors, gearboxes, and pumps can create strong reliability gains without requiring full-time data science capability.
What changes when a plant moves toward PdM
The jump to PdM isn't just a sensor upgrade. It's a data architecture shift. Continuous or high-frequency data collection becomes more important. History has to be stored cleanly. Events need timestamps that line up with work orders and operating changes. Analysts need enough consistency to tell signal from noise.
That usually means the plant has to tighten five areas:
| Implementation area | CBM need | PdM need |
|---|---|---|
| Sensor coverage | Point measurement or periodic route | Broader, more consistent coverage for trend confidence |
| Data storage | Basic records and alarm history | Time-series history that supports trend analysis |
| Work order integration | Alarm creates task | Model output links to planning and maintenance history |
| Skills | Technician interpretation and threshold management | Added analytical capability and stronger data discipline |
| Governance | Local control can work | Cross-site standards become important |
For teams dealing with inconsistent naming, missing failure codes, and fragmented records, a solid guide to real-world data governance is useful because governance problems often derail PdM long before modeling does.
If the plant can't trust the timestamps, asset hierarchy, and work history, it can't trust the forecast either.
Many programs overreach. They install more sensors than they can support, collect data nobody validates, and expect software to compensate for weak maintenance records. It won't. Prediction quality depends on the discipline underneath it.
A more effective path is staged. Start with assets that already have repeatable failure modes and good maintenance history. Build clean workflows between monitoring and planning. Then expand. Plants exploring advanced analytics usually benefit from understanding how machine learning fits into predictive maintenance before scaling beyond pilot assets.
Making the Final Decision Cost ROI and Next Steps
The right answer is rarely “all CBM” or “all PdM.” It's an asset-by-asset decision based on consequence, failure behavior, and whether better lead time changes the outcome.
For high-criticality equipment, the economic case for earlier detection can be strong. A McKinsey study cited here found predictive maintenance can reduce machine downtime by 30% to 50%, increase machine life by 20% to 40%, and reduce maintenance costs by 18% to 25%. Those results explain why plants tend to reserve PdM effort for assets where unplanned downtime is expensive and planning time has real operational value.
A practical decision filter
A plant manager can usually sort assets with four questions:
- How critical is the asset? If failure stops production, creates quality risk, or affects safety or compliance, earlier detection matters more.
- What is the dominant failure mode? Some defects drift slowly. Others move from detectable to failed too fast for threshold-only response.
- Is there enough usable data? If the site lacks reliable history, sensor coverage, or analytical support, CBM may be the better choice today.
- Can the plant act on earlier notice? There's no value in forecasting far ahead if procurement, scheduling, and outage coordination can't respond.
Where each strategy usually fits
CBM usually fits assets with slower failure development, lower downtime consequence, easier replacement, or weaker data maturity. Many pumps, motors, fans, and auxiliary gearboxes can live here successfully if thresholds are sensible and response is disciplined.
PdM usually fits bottleneck assets, rotating equipment with costly collateral damage, and machines where maintenance timing affects shutdown planning. Compressors, large process pumps, mixers, and other critical train components often belong in this category when the plant can support the required data quality.
The best programs don't chase sophistication everywhere. They spend analytical effort where additional warning time changes the maintenance decision.
Most facilities end up with a layered model. Some assets stay on preventive tasks. Some move to CBM. A smaller population gets PdM because those machines create most of the operational pain when they fail.
A plant doesn't need a bigger dashboard. It needs a clearer reliability decision. Forge Reliability helps industrial teams evaluate asset criticality, failure modes, P-F intervals, and data maturity to decide where condition-based monitoring is enough and where predictive maintenance will pay off. Schedule a free reliability assessment to identify the highest-value opportunities for reducing unplanned downtime and improving maintenance planning.


