
At 2:13 a.m., the freezer alarm doesn't care that the maintenance planner is off shift and the plant manager is at home. Suction pressure is unstable, the lead compressor has tripped, product temperature is drifting, and operations wants one answer immediately: how long until the system is back under control?
That's the moment industrial refrigeration stops being “utilities” and becomes what it really is. A production-critical asset system with direct consequences for throughput, quality, safety, and energy spend. In food plants, cold storage warehouses, pharmaceutical sites, and chemical facilities, refrigeration failures rarely stay contained to one machine. A bad bearing, fouled heat transfer surface, drifting control loop, or contaminated oil charge can cascade into lost capacity, unstable temperatures, nuisance trips, and rushed decisions that create even more risk.
The scale of the asset class reflects that importance. The global industrial refrigeration market was valued at USD 21.46 billion in 2023 and is projected to reach USD 33.86 billion by 2032, expanding at a CAGR of 5.2%, driven by food and beverage demand and cold chain growth, according to SNS Insider's industrial refrigeration market report. More plants are depending on these systems, and many of them are becoming more complex at the same time.
Table of Contents
- The True Cost of Refrigeration Downtime
- System Architecture and Critical Components
- Common Failure Modes and Their Root Causes
- Predictive Diagnostics for Early Fault Detection
- Designing a Predictive Maintenance Strategy
- Optimizing for Safety Energy and OEE
- Integrate Refrigeration into Your Reliability Program
The True Cost of Refrigeration Downtime
A refrigeration outage almost never shows up as a single maintenance event. It shows up as a sequence. First comes the alarm. Then operators start managing around temperature drift. Production slows or stops. Quality teams start evaluating exposure windows. Maintenance scrambles for root cause while leadership asks whether the issue is mechanical, electrical, or controls-related.
In a poultry plant with ammonia blast freezers, one overnight compressor trip can force supervisors to choose between holding product, shifting work to another line, or accepting a backlog that spills into the next shift. In a pharmaceutical cold room, the pressure is different but just as real. Product value is higher, excursion tolerance is tighter, and every response decision has documentation consequences.
Downtime spreads beyond the machine
Plant teams often underestimate refrigeration downtime because they count the repair hours but not the operational drag around the event. The actual cost includes:
- Production disruption: Lines slow down when evaporator performance falls or room temperature drifts outside target.
- Product risk: Frozen and chilled inventory can lose value quickly when the system can't pull heat out fast enough.
- Labor inefficiency: Operators, maintenance, quality, and supervision all get pulled into the same incident.
- Safety exposure: Emergency operation, manual overrides, and rushed troubleshooting raise risk in ammonia and high-pressure systems.
Practical rule: If refrigeration is tied to product quality or permit compliance, the asset should be treated like a production bottleneck, not like background infrastructure.
The management mistake is usually the same. Teams focus on restoring operation and then move on, without measuring whether the event was a random failure or a predictable one. Better plants track refrigeration events with the same rigor they apply to other constrained assets, using asset performance measures that connect uptime and maintainability to plant output. A useful starting point is this guide to reliability metrics such as MTBF, MTTR, and OEE.
Growth has raised the stakes
Industrial refrigeration is expanding because demand for cold product handling keeps expanding. The market data cited earlier isn't just a business headline. It signals that more facilities are adding capacity, more operators are relying on cold chain continuity, and more maintenance teams are inheriting systems that can't be managed with reactive work orders alone.
A plant manager doesn't need another generic checklist. The plant needs a reliability framework that identifies failure precursors early, assigns the right diagnostics to the right assets, and helps maintenance intervene before a compressor trip becomes an operations crisis.
System Architecture and Critical Components
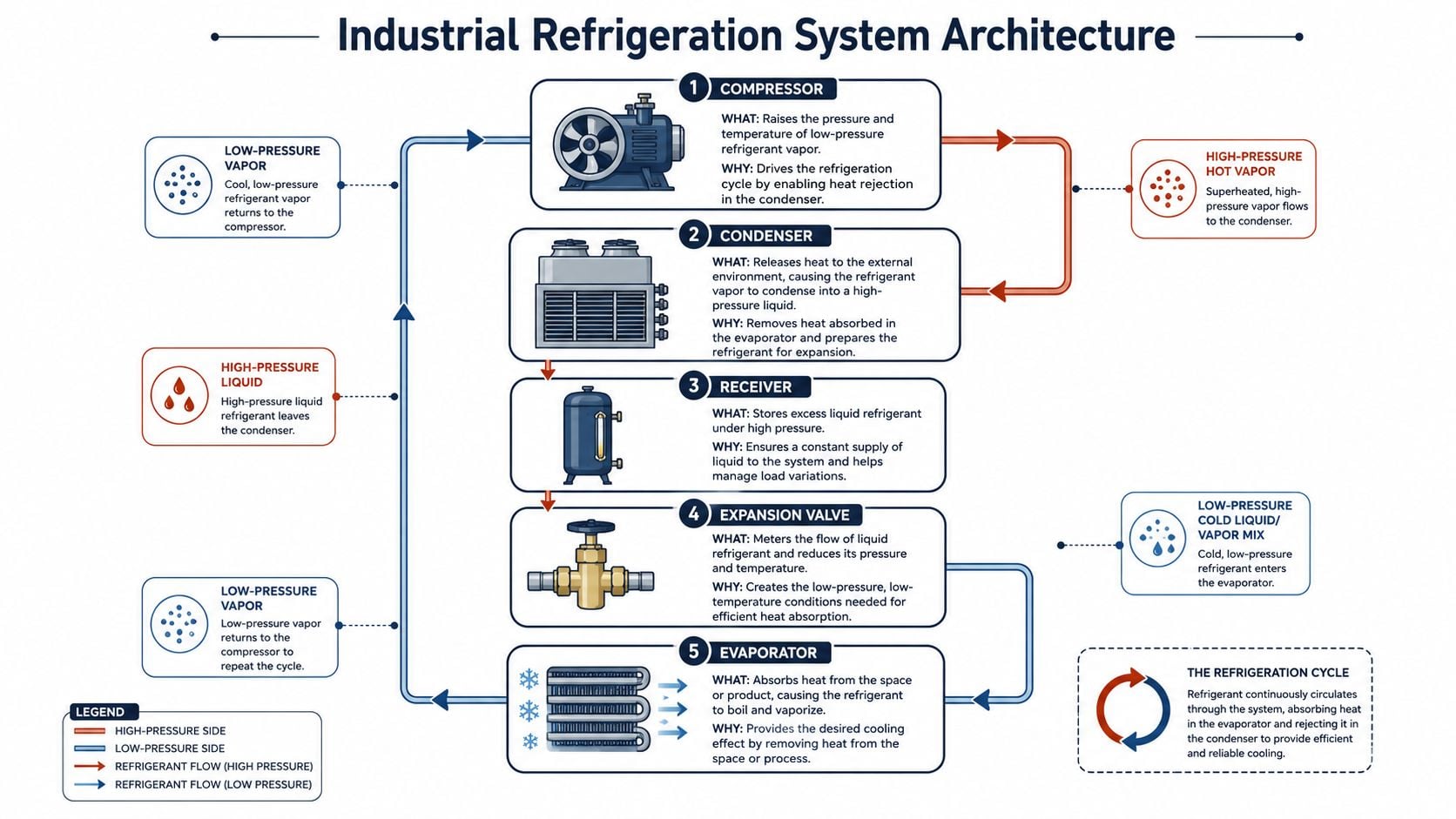
Industrial refrigeration makes more sense when it's treated like a circulatory system. The refrigerant is the working fluid. The compressor provides the driving force. The condenser rejects heat. The expansion device meters flow and drops pressure. The evaporator absorbs heat where cooling is needed. If one part underperforms, the whole loop feels it.
A large food processing blast freezer is a good example. In an ammonia-based system pulling packaged product down to -20°F, the refrigeration circuit has to move heat fast, repeatably, and safely. Capacity isn't just about low temperature. It's about stable temperatures, predictable pull-down times, and enough control margin to handle loading changes shift after shift.
For a more detailed equipment-level view, this overview of industrial refrigeration systems and condition monitoring is useful background for maintenance teams building inspection routes.
How the refrigeration loop actually works
The compressor is the heart of the system. It raises refrigerant pressure and temperature so the system can reject heat at the condenser. In practical terms, it creates the pressure differential that keeps the whole cycle moving. If compressor efficiency falls, system capacity falls with it.
The condenser acts like a radiator. It releases heat from the hot, high-pressure refrigerant to air or water, turning vapor back into liquid. When condenser performance declines, head pressure rises and compressor load increases.
The receiver stores liquid refrigerant and buffers the system during load changes. That matters in industrial plants because load isn't constant. A blast freezer door opening, a room pull-down, or a process surge can all shift system demand.
What matters most in a blast freezing system
The expansion valve meters liquid refrigerant into the evaporator and drops its pressure. That pressure drop allows the refrigerant to absorb heat efficiently. If the valve overfeeds or underfeeds, the evaporator won't operate correctly and compressor protection becomes harder.
The evaporator is where useful cooling happens. It absorbs heat from the room air or product stream, and the refrigerant boils into vapor. In a food plant blast freezer, evaporator performance determines whether product reaches target temperature on schedule.
Two terms matter here:
- Superheat is the temperature of refrigerant vapor above its boiling point at that pressure. In the field, it helps maintenance confirm whether the evaporator is being fed correctly and whether liquid refrigerant might be returning to the compressor.
- Subcooling is the temperature of liquid refrigerant below its condensing temperature at that pressure. In practice, it helps confirm that the liquid line is delivering solid liquid to the expansion device instead of flashing early.
Good operators don't just ask whether the room is cold. They ask whether the loop is balanced.
A blast freezer can still “make temperature” while carrying hidden reliability problems. High head pressure, poor liquid feed stability, oil management issues, and control hunting often appear before the room falls out of spec. That's why component knowledge matters. A plant manager doesn't need to become a refrigeration designer, but they do need to know which component failures create capacity loss, which ones create safety risk, and which ones raise operating cost.
Common Failure Modes and Their Root Causes
Most industrial refrigeration failures are misdiagnosed at first because the visible symptom is not the root cause. The compressor trips, but the root cause may be oil contamination, poor evaporator control, non-condensables, liquid return, or a bad control signal. Teams that stop at the first symptom keep repeating the same outage with different work orders.
A chemical processing facility illustrates the pattern well. Operators kept reporting chiller trips during periods of heavy load. The first response was to inspect motor protection settings and restart sequencing. The actual problem was refrigerant-side contamination by non-condensable gases, which increased condensing pressure and forced the compressor into harder operation than the team recognized.
Compressor failures rarely start at the compressor
In semi-hermetic reciprocating compressors, critical failure modes include valve plate fatigue and bearing degradation. Applying FMEA and Weibull distribution modeling to life-cycle data helps teams predict those failures and schedule condition-based maintenance, cutting unplanned downtime by over 30%, as described in this semi-hermetic reciprocating compressor reliability study.
That matters because the same compressor can fail in very different ways for very different reasons:
- Valve plate fatigue: Often tied to repeated stress, unstable operating conditions, or poor control of liquid carryover.
- Bearing degradation: Commonly linked to lubrication breakdown, contamination, or misalignment-driven load.
- Piston ring wear: Usually associated with long-term wear progression, poor lubrication quality, or contaminated internals.
Maintenance teams that want a structured way to rank failure effects and detection methods can use a framework like this guide to FMEA for operations managers. The value isn't the paperwork. The value is forcing the team to distinguish between failure symptom, damage mechanism, and consequence.
Heat transfer and refrigerant quality problems
Not every serious fault starts in rotating equipment. Heat transfer surfaces create their own reliability problems, and they usually do it gradually.
A 10% decrease in pressure drop across the evaporator or condenser is a verified indicator of heat transfer deterioration, often caused by partial fouling or blocked sections, and that deterioration raises high pressure and compressor load, according to this operation and maintenance reference on industrial refrigeration systems. In the field, that means a plant can still be running while the compressor is working harder every day.
Common root-cause patterns include:
| Failure symptom | Likely root cause | Operational consequence |
|---|---|---|
| Rising head pressure | Fouled condenser, blocked airflow, non-condensables | Higher compressor load, lower efficiency |
| Unstable suction conditions | Expansion valve instability, load swings, evaporator icing | Poor temperature control, nuisance trips |
| Repeated high motor load | Heat transfer loss, refrigerant contamination, oil dilution | Accelerated wear and possible trip events |
When head pressure rises slowly, teams often blame the weather first. The better question is whether the heat exchanger is still doing its job.
Controls create hidden reliability risk
Control failures are different because they can mimic mechanical failure. A bad sensor input, sticky regulator, or unstable logic sequence can produce trips that look mechanical until someone reviews the control action history.
The most effective response is disciplined root cause work, not parts swapping. This guide to root cause analysis in industrial refrigeration fits well when a plant has repeat alarms, recurring nuisance trips, or intermittent failures that haven't responded to standard PM tasks.
A plant manager should expect every recurring refrigeration event to be classified into one of three buckets: mechanical degradation, process or heat transfer issue, or controls logic problem. If the team can't sort events that way, the site isn't troubleshooting. It's reacting.
Predictive Diagnostics for Early Fault Detection
At 2:00 a.m., a low-temperature warehouse does not care whether a fault started in a bearing, a sensor, the oil, or the refrigerant circuit. The product warms up the same way. What matters is whether the plant can detect the problem while there is still time to plan the repair instead of taking an outage.
Predictive diagnostics works when each method is tied to a specific failure mechanism and a defined response. Plants get into trouble when they collect readings without deciding what question each reading is supposed to answer. Industrial refrigeration adds another layer of difficulty because the same symptom can mean different things on an ammonia screw package, a reciprocating system, or a newer low-GWP installation with different pressure-temperature behavior and lubricant sensitivities.
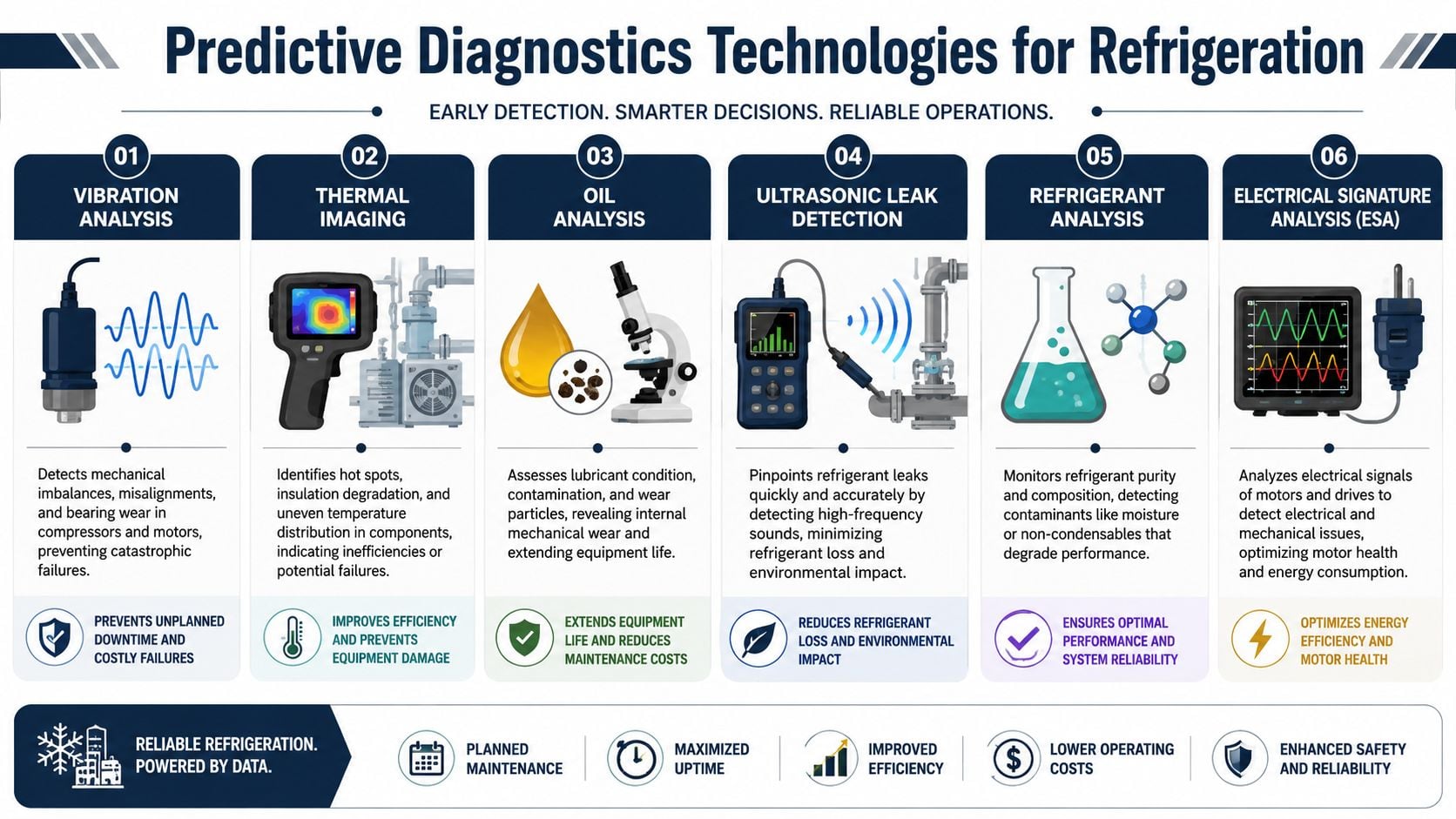
Choosing the right diagnostic tool for the failure mode
The selection process starts with failure physics, not instrument availability.
- Vibration analysis is best for rotating faults in compressors, motors, and fan assemblies. Use it to catch imbalance, misalignment, looseness, and bearing distress before clearance loss turns into a trip or rotor damage.
- Thermal imaging is best for electrical and heat transfer problems. It helps crews find overloaded terminations, failing contactors, blocked airflow paths, uneven condenser loading, and hot spots in motor control equipment.
- Ultrasonic inspection is useful for leak surveys, valve passing, and early bearing friction on accessible assets. It earns its keep where small refrigerant leaks are expensive, hard to isolate, or unsafe to ignore.
- Electrical signature analysis helps separate motor health from driven-equipment problems. That matters when current imbalance, rotor defects, or power quality issues are being mistaken for compressor trouble.
- Oil and refrigerant condition checks are the right tools when efficiency drops without a clear mechanical signature. They expose dilution, moisture, contamination, and non-condensables that can push energy use up long before a machine fails.
Different systems need different emphasis. An ammonia screw compressor usually gives more warning in the oil than in a quick walk-by inspection. A distributed low-GWP system may show its first signs in superheat instability, valve hunting, or abnormal pressure relationships, especially after a retrofit where legacy control settings were never tuned to the new refrigerant.
Oil analysis deserves first-class status in ammonia service
In ammonia refrigeration, compressor oil analysis is one of the few diagnostics that shows what is happening inside the machine without opening it. It identifies wear metals, moisture, acid formation, and refrigerant dilution, all of which change lubrication quality before the compressor gets loud enough for everyone to notice.
That point gets missed by maintenance teams that rely too heavily on vibration alone. A compressor can run without noticeable noise while diluted oil loses film strength and starts damaging bearings or rotors. By the time vibration moves sharply, the repair scope is often larger and the outage window is harder to control.
Use oil results as a decision tool, not a filing exercise:
- Wear metals suggest distress in bearings, gears, rotors, or other loaded components.
- Moisture points to contamination that will shorten oil life and weaken lubrication performance.
- Acid number trend shows lubricant breakdown and possible chemical attack inside the system.
- Refrigerant dilution indicates viscosity loss and reduced load-carrying capacity.
I tell plant managers to treat conflicting evidence seriously. Clean vibration with bad oil does not clear the compressor. It usually means the fault is still early enough to catch.
Teams that want to move beyond isolated inspection routes can connect these inputs to analytics and alarm logic. This guide to predictive maintenance and machine learning for industrial assets is useful when the goal is to turn raw condition data into earlier, more consistent maintenance decisions. The operating model behind that approach is still condition based maintenance, but refrigeration programs need tighter diagnostic rules than generic CBM examples usually provide.
A practical diagnostic mix for a cold storage warehouse
For a warehouse running around the clock, I would build the diagnostic program around asset criticality and fault consequence.
Start with route-based vibration on compressors, condenser fans, and any evaporator motors tied to high-value rooms. Add scheduled thermography on MCCs, VFD cabinets, disconnects, and heavily loaded electrical connections. Pull routine oil samples on ammonia compressors, then shorten the interval on problem machines or after seal work, motor events, or unexplained operating changes. Use ultrasonic leak checks after intrusive maintenance and during seasonal transitions when leak rates often become visible. Add refrigerant condition and pressure-temperature verification when field readings stop matching expected evaporator or condenser performance.
That mix works because each method answers a different diagnostic question. More important, it gives the plant a way to distinguish mechanical degradation from contamination, controls drift, and refrigerant-side problems before they combine into a shutdown.
Designing a Predictive Maintenance Strategy
A diagnostic tool only becomes a maintenance strategy when the plant defines what action each signal should trigger. Many industrial refrigeration programs fail at that step. They gather vibration, thermal, and lubricant data, but no one agrees on alarm thresholds, inspection intervals, or what constitutes an actionable trend.
A pharmaceutical facility storing temperature-sensitive product offers a useful example. The plant can't wait for a hard failure because product exposure, documentation burden, and operational disruption all rise quickly once room conditions drift. The maintenance team needs thresholds that are tight enough to catch developing faults early, but stable enough that the staff doesn't start ignoring alarms.
Set baselines before setting alarms
Original equipment settings are only a starting point. A real predictive program needs plant-specific baselines built from actual operating conditions, load patterns, and system configuration.
That means the site should define:
- Which compressors are most critical to production or compliance.
- What normal looks like for vibration, temperatures, oil condition, suction behavior, and head pressure under stable load.
- Which trend changes require observation, planned intervention, or immediate action.
A helpful concept for operations leaders is condition based maintenance. The key idea is simple. Work is triggered by verified equipment condition, not just calendar intervals. In refrigeration, that approach is especially valuable because two identical assets can age very differently depending on load, contamination exposure, and control stability.
Low-GWP refrigerants change the reliability playbook
Plants transitioning to natural refrigerants often focus first on regulation, efficiency, or capital design. Reliability usually gets less attention than it should.
That's a mistake. Transitioning to low-GWP natural refrigerants like ammonia or CO2 creates new reliability challenges. Ammonia's higher pressure requires recalibrated vibration thresholds, while CO2 operation changes oil analysis baselines, as noted in the EPA discussion of transitioning to low-GWP refrigeration alternatives. If the plant keeps old alarm assumptions after a refrigerant transition, the team may either miss early failures or chase false positives.
Mixed-refrigerant and cascade systems become especially demanding. In those systems, the team has to separate symptoms by circuit, operating regime, and component duty. Generic PM templates don't help much because the signatures can differ across low-boiling and high-boiling loops. Reliability leaders need asset-specific failure logic, not inherited checklists.
Use business-facing KPIs that operations will trust
The best predictive maintenance strategy uses technical indicators and operating indicators together. Reliability data gains credibility when it explains business performance, not just equipment condition.
Useful refrigeration KPIs include:
- Energy Efficiency Ratio: A way to track how effectively the system converts energy input into cooling output.
- Cost per ton of refrigeration: A practical measure for comparing operating burden over time.
- Temperature stability by area or process: Important where quality or compliance depends on narrow limits.
- Intervention lead time: How far in advance the team identifies a fault before production is affected.
A mature PdM program doesn't ask, “Did the compressor fail?” It asks, “How much warning did the plant get, and did the team act in time?”
When those measures are reviewed together, the plant starts making better decisions about overhaul timing, spare parts, capital planning, and operator response expectations.
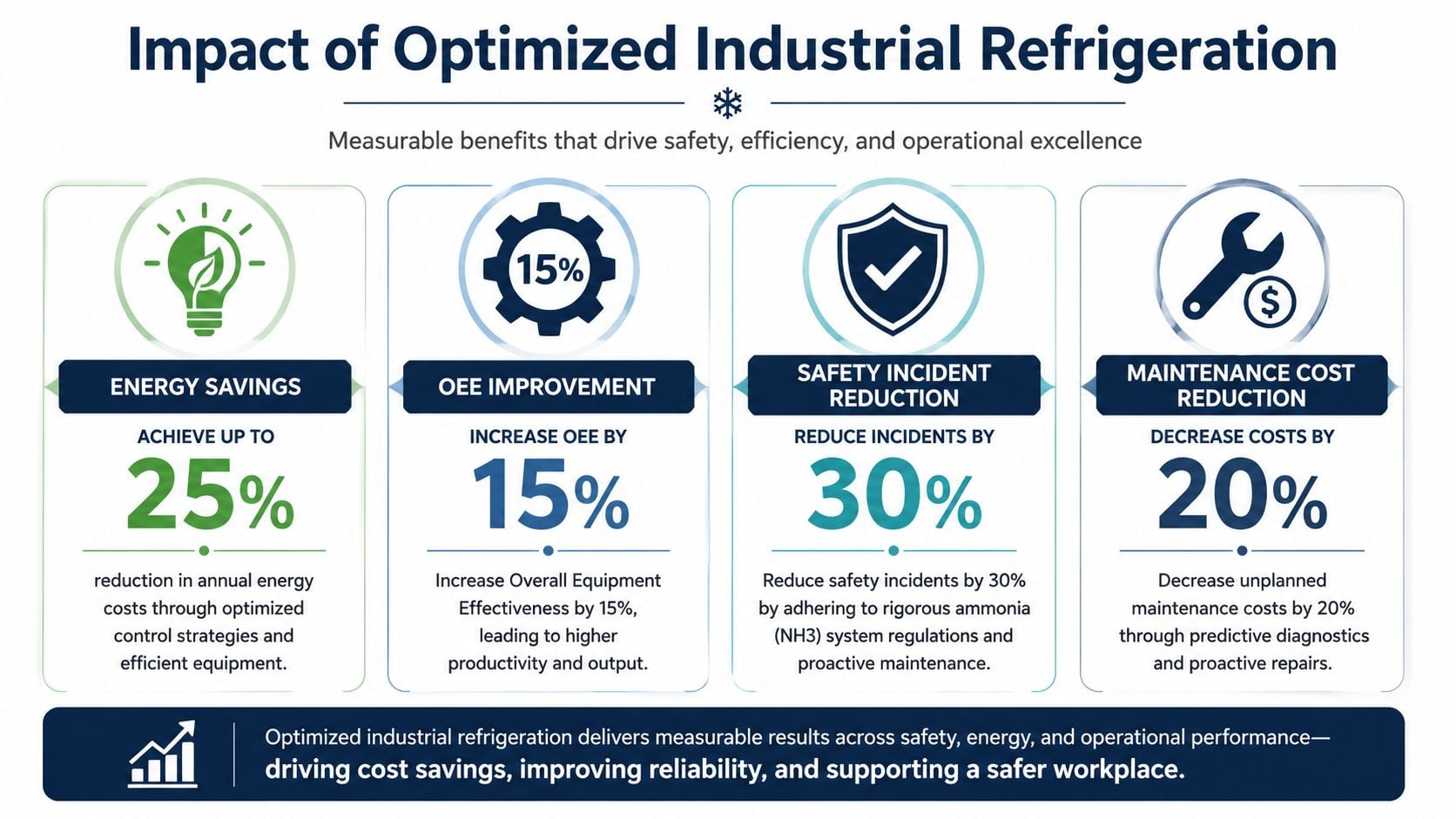
Optimizing for Safety Energy and OEE
Reliable industrial refrigeration is one of the few plant programs that improves safety, efficiency, and production at the same time. That's especially true in ammonia systems, where a mechanical or controls problem can create both process loss and serious safety exposure.
The point isn't that every refrigeration issue becomes a safety event. The point is that weak reliability discipline raises the odds of unstable operation, emergency intervention, and repeat failures. That's why safety leadership and maintenance leadership should be looking at the same refrigeration data, not separate dashboards.
Safety failures often begin as maintenance failures
In industrial refrigeration, PLCs and ammonia regulators are high-risk components with documented failure rates, and equipment-related events require root cause methods such as 5-Why and fault tree analysis to eliminate recurring breakdowns and support safety, according to this technical paper on natural refrigeration equipment-related events.
That's a practical warning for plant managers. If a regulator sticks, a control sequence behaves unpredictably, or an instrument signal drifts, the mechanical system may still look healthy while operating risk rises.
A disciplined response includes:
- Control loop verification: Review whether valves, sensors, and logic are doing what operators think they're doing.
- Event reconstruction: After trips or excursions, map the sequence instead of replacing parts based on guesswork.
- Repeat failure review: If the same alarm or trip returns, treat it as a system problem until proven otherwise.
Energy waste is usually a reliability symptom
Plants often separate energy management from maintenance, but refrigeration doesn't cooperate with that split. A fouled condenser, poor liquid feed, unstable head pressure, or degraded compressor lubrication directly pushes power demand in the wrong direction.
A large dairy site is a strong example. When heat transfer performance degrades, the refrigeration system must work longer and harder to deliver the same cooling result. Energy cost climbs, but the root cause is still maintenance execution.
Operations leaders who want a better financial lens on refrigeration often benefit from understanding the broader energy audit process for commercial and industrial facilities. That perspective helps connect equipment condition findings to energy budgeting and capital priorities.
If the refrigeration plant is drawing more power to hold the same temperatures, the first question shouldn't be tariff-related. It should be what changed inside the system.
OEE improves when refrigeration stops constraining production. Energy performance improves when heat transfer surfaces stay clean, control loops stay stable, and compressors operate within healthy condition limits. Safety improves when the plant eliminates repeat faults before operators have to manage around them. Those aren't separate wins. They're outcomes of the same reliability discipline.
Integrate Refrigeration into Your Reliability Program
Many plants already have a reliability program on paper. Fewer have refrigeration fully integrated into it. The difference shows up in work prioritization, CMMS data quality, and who gets called when system performance starts to drift.
A refrigeration program becomes manageable when the site treats it like any other critical asset system. It needs criticality ranking, failure logic, condition monitoring, planned response criteria, and regular review. Without those pieces, the plant will keep handling refrigeration through urgency rather than process.
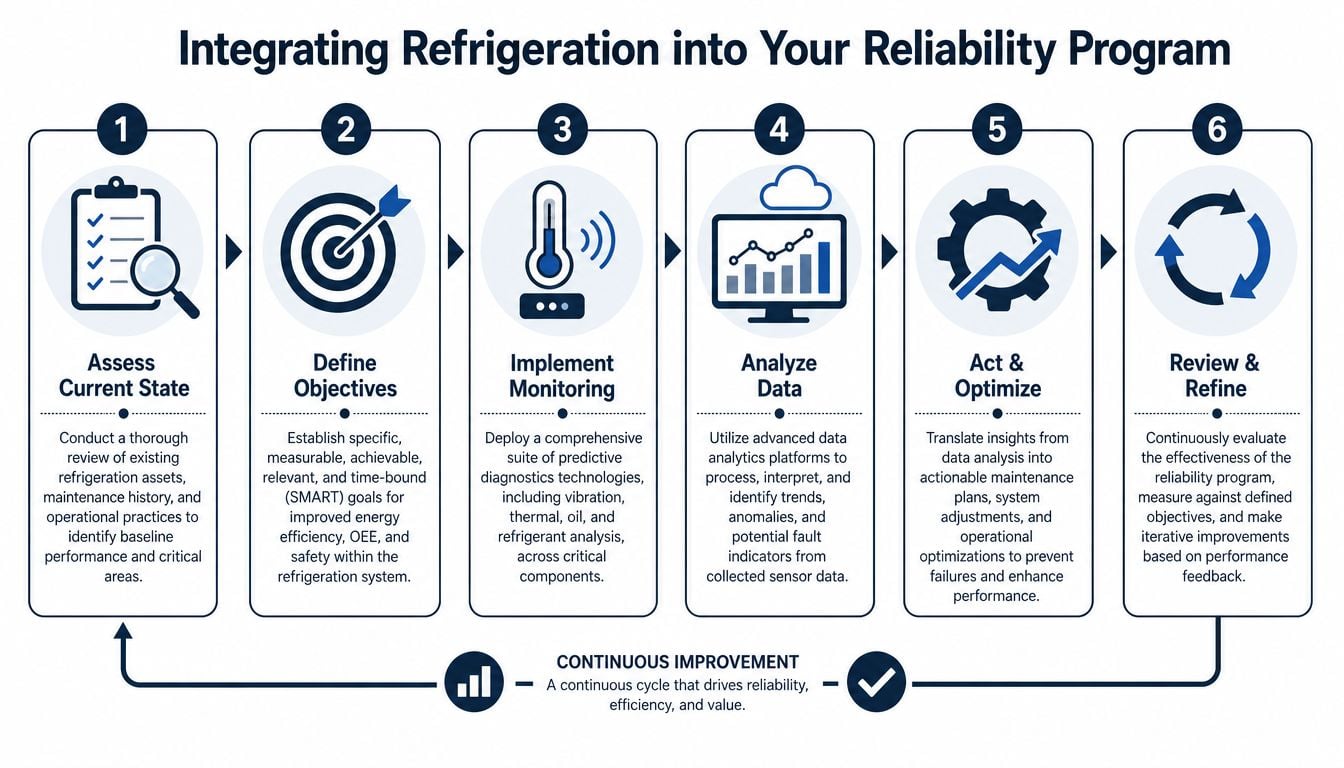
Start with criticality and a pilot asset set
The first step is an asset criticality review. Not every evaporator fan or package unit deserves the same attention. The plant should rank assets by production impact, product exposure risk, safety consequence, and recovery difficulty.
This is also where lifecycle thinking matters. A site that's deciding which compressors to rebuild, which controls to upgrade, and which assets to replace needs a disciplined view of asset lifecycle management, not just annual repair history.
A practical rollout usually follows this sequence:
- Select the most critical refrigeration assets, not the most convenient ones.
- Define failure modes that matter operationally, such as compressor bearing distress, lubricant contamination, unstable controls, or heat transfer loss.
- Set collection methods for vibration, thermal data, oil analysis, and operating parameters.
- Push those findings into the CMMS with failure coding that supports analysis later.
Build the review loop into the program
Plants often launch condition monitoring and then lose discipline in the review stage. That's where the value is won or lost.
A monthly refrigeration reliability review should ask:
- Which faults were detected early, and what intervention followed?
- Which alarms were false, and why were thresholds wrong?
- Which repeat failures still lack a verified root cause?
- Which assets need PM interval changes, redesign, or capital planning?
A good program also forces communication between operations and maintenance. Operators usually see the first performance drift. Maintenance sees the physical failure evidence. Engineering sees the design limitations. The plant manager has to make sure those views meet before the next outage does.
Industrial refrigeration doesn't need to remain a specialist problem that only gets attention during emergencies. With clear criticality, fault-specific diagnostics, and disciplined review, it becomes another asset system the plant can control instead of fear.
A plant that's dealing with recurring compressor trips, unstable temperatures, rising energy use, or uncertain refrigerant transition risk should start with a structured outside review. Forge Reliability offers a free reliability assessment to help maintenance and operations teams identify critical failure modes, improve condition monitoring, and build a practical path to fewer refrigeration outages.


