
A plant manager usually starts thinking seriously about redundancy planning after the same uncomfortable meeting happens twice. Production lost another shift. Maintenance says the standby equipment wasn't ready. Finance asks why capital wasn't requested earlier. Operations wants a guarantee that it won't happen again.
That's the moment when redundancy stops being a generic reliability buzzword and becomes a capital decision with consequences on the plant floor. For reliability engineers, maintenance managers, and operations leaders, the core job isn't buying a backup pump or adding a generator. The job is proving which assets justify redundancy, selecting the right architecture, building a financial case around the cost of downtime, and then managing the whole design inside the CMMS so the backup doesn't turn into a neglected liability.
A chemical unit cooling water train, a food plant transfer system, a manufacturing air compressor header, or a pipeline booster station all face the same hard truth. A redundant asset only protects production if the plant understands failure modes, maintains independent support systems, and validates the switchover under real conditions.
Table of Contents
- Start with Data Not Hardware Your Criticality Analysis
- Select the Right Redundancy Architecture
- Build an Ironclad Business Case for Investment
- Execute the Plan with CMMS and Spare Parts Optimization
- Validate Performance and Prevent Silent Failures
- From Plan to Plant Floor Reliability
Start with Data Not Hardware Your Criticality Analysis
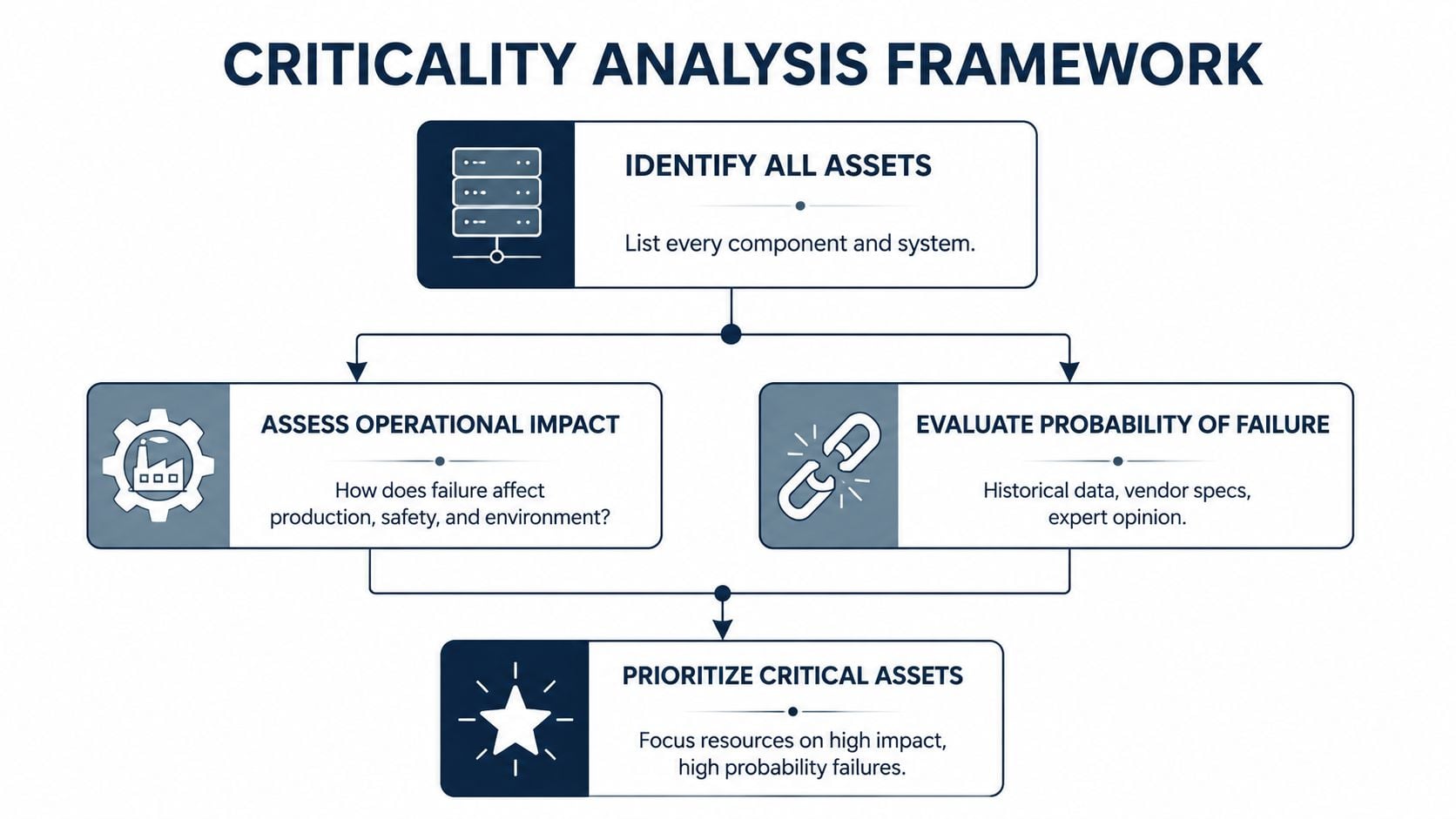
Plants waste money when they start redundancy planning with equipment catalogs instead of asset criticality. The first question isn't “Should a second pump be installed?” The first question is “Which failure stops production, creates safety exposure, or causes environmental risk fastest?”
In industrial work, that answer rarely sits at the equipment tag level alone. It sits in the system. Effective redundancy planning requires a rigorous methodology starting with thorough system mapping and a dependency matrix to systematically identify single points of failure across mechanical, process, structural, and utility categories before any design can occur according to industrial redundancy planning guidance.
Map the system before ranking the equipment
Take a cooling water system in a chemical plant. Two pumps may appear to solve the problem on paper, but the system can still carry hidden single points of failure:
- Common suction source: If both pumps depend on one fouled basin intake, the train still has one failure path.
- Shared electrical distribution: If both motors feed from the same vulnerable panel, the motors aren't independent.
- Single control logic path: If one PLC card or instrument loop trips both pumps, hardware duplication won't protect the process.
- No usable bypass route: If piping can't carry transient flow during switchover, the backup unit may start and still fail the process.
That's why the dependency matrix matters. It forces the team to list not just rotating equipment, but utilities, controls, valves, structures, and operator actions. A pump can look redundant while the system remains fragile.
Practical rule: If two assets share the same failure cause, they don't provide real redundancy.
A useful criticality review also needs failure history. That doesn't require perfect data, but it does require disciplined use of work orders, operator logs, and maintenance records. When a site wants to estimate recurring failures, historical data tied to a measure such as mean time between failure can help separate chronic nuisance assets from true business risks.
Build a practical criticality matrix
A criticality matrix works when it stays simple enough for operations and maintenance to use consistently. Most plants get value by scoring each asset or subsystem against two axes:
| Factor | What the team should ask |
|---|---|
| Impact | Does failure stop production, create a safety hazard, trigger environmental exposure, or damage quality? |
| Likelihood | Has the asset failed before, does it show degrading condition, or does its design contain known weak points? |
In a cooling water example, the tower fan motor may matter, but the pump header and its associated controls usually rank higher because they can shut down multiple process units at once. That distinction is what keeps redundancy capital focused on the assets that drive risk.
A good criticality review also counts hidden costs of downtime. Lost throughput is only part of the picture. Plants also need to account for scrap, restart labor, overtime, cleanup, missed shipments, permit exposure, and the operational instability that follows a rushed restart. Those costs are often what turns a “nice to have” standby asset into a justifiable project.
Use this sequence:
- List every asset in the system. Include pumps, motors, valves, instrument loops, utilities, structural supports, and control dependencies.
- Score operational consequence. Focus on safety, environment, quality, and throughput.
- Review failure modes. Use actual work order history and observed mechanisms such as seal leakage, bearing distress, fouling, or instrument drift.
- Rank the top risk chains. Not the loudest failures. The failures that create the biggest plant-level disruption.
- Target redundancy only where the business consequence supports it. Every backup asset adds inspection, PM labor, spares, and testing burden.
The strongest redundancy projects start with a system drawing, a failure review, and a hard conversation about what downtime actually costs.
Select the Right Redundancy Architecture
Once the plant knows which assets justify protection, the next decision is architectural. At this stage, many projects drift off course. Some sites overbuild and tie up capital in duplication they don't need. Others underbuild and install a backup that fails for the same reason as the primary asset.
A food and beverage transfer system is a good example. A product transfer pump serving a non-bottleneck process step may only justify a modest standby strategy. A pasteurizer support system tied directly to product safety and line continuity may require much stronger separation.
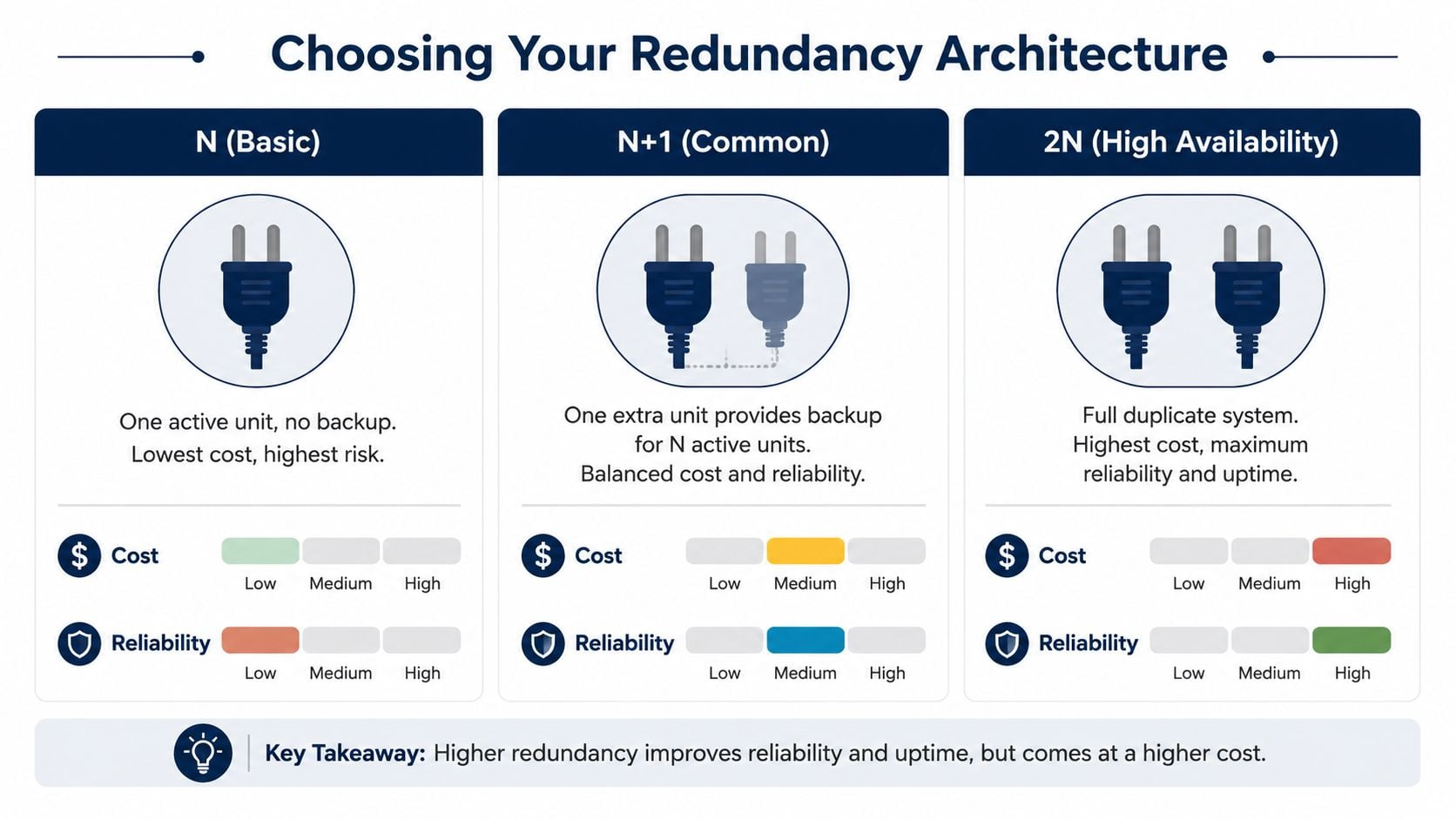
What N, N+1, and 2N actually mean in plant terms
The language matters because finance, engineering, and operations often use these terms differently.
| Architecture | Plant meaning | Typical use |
|---|---|---|
| N | The minimum equipment required to run | Non-critical services where downtime is tolerable |
| N+1 | The required capacity plus one extra unit | Common choice for critical production support systems |
| 2N | Full duplication of the required system | High consequence applications needing strong fault tolerance |
For industrial assets, the standard design is often N+1, meaning one backup for the required units, but this only works when the system has independent failure modes, separate utility feeds, and validated switchover procedures so the backup can absorb the primary load without causing a secondary failure as described in this engineering discussion on pump and motor redundancy.
That last point is where many plants get surprised. Two transfer pumps mounted side by side aren't automatically an N+1 success. If both have the same suction issue, the same power vulnerability, or the same control permissive, the architecture looks stronger than it is.
Hot, warm, and cold standby are different risk decisions
The standby state changes both reliability and operating cost.
- Hot standby: The spare runs or stays fully online and can take load quickly. This reduces delay but increases wear, energy use, and maintenance demand.
- Warm standby: The spare is idle but maintained in a ready state. This balances response time with lower running wear.
- Cold standby: The spare sits isolated or in storage. This costs less to operate but carries the highest startup uncertainty.
In a food plant, a product transfer pump in warm standby often makes sense because maintenance can rotate duty and standby service, verify readiness, and avoid dead legs that create sanitation risk. By contrast, a critical thermal process support service may need a hotter standby posture because startup delay itself creates quality risk.
Redundancy architecture is never just a piping drawing. It's a decision about how much failure risk the plant will carry, how fast recovery must happen, and how much maintenance discipline the site can sustain.
There's also a design choice between identical and diverse redundancy. Identical units simplify parts and training, but they can share the same design weakness. That matters with known failure modes. In equipment maintenance discussions citing OREDA data, seal failures account for approximately 22% of all pump failures in rotating equipment, which makes seals a dominant vulnerability in pump systems and a serious concern when both primary and standby pumps share the same weak point, as noted in this pump redundancy and FMEA discussion.
For a transfer system, that may justify different sealing arrangements, different flushing arrangements, or tighter seal condition monitoring rather than duplicating the same exact failure path.
Build an Ironclad Business Case for Investment
Technical logic alone rarely gets a redundancy project funded. A plant gets approval when the team turns reliability risk into financial language that operations leadership and finance can act on.
A manufacturing facility trying to justify a backup air compressor is a common case. Maintenance knows one compressor trip can upset multiple lines, starve actuators, force emergency shutdowns, and create a scramble across the plant. Management still needs a clean answer to one question. Why this project, now?

Translate failure risk into financial language
The strongest business case compares two numbers the plant already understands:
| Cost bucket | What belongs in it |
|---|---|
| Cost of downtime | Lost production, restart labor, scrap, expedited shipping, contractor callout, quality losses, safety exposure |
| Cost of redundancy | Equipment, installation, piping, electrical work, controls, startup, PM labor, inspection, testing, spare parts |
That comparison changes the conversation. The project is no longer “another capital ask from maintenance.” It becomes a controlled investment to reduce a recurring financial exposure.
A useful air system example looks like this in practice:
- The team identifies which production lines lose air first.
- Operations estimates the consequence of a compressed air interruption during live production.
- Maintenance adds the history of trip causes such as motor overloads, cooler fouling, control instability, and moisture-related issues.
- Engineering prices the backup compressor, tie-ins, controls integration, and switchover logic.
- Finance sees the project framed against repeatable operational loss rather than against equipment price alone.
That's also why maintenance cost structure matters. Plants that want to sharpen these decisions usually need better visibility into reactive labor, parts use, contractor spend, and recurring failure cost. A structured look at maintenance cost reduction priorities often exposes where redundancy delivers a better return than continued emergency response.
Model the full life cycle cost not just purchase price
A weak capital request stops at the quotation for the backup asset. A credible request includes the life cycle burden the plant will carry after installation.
The standby unit isn't free once it arrives. It adds inspections, PM tasks, operator training, parts exposure, and future replacement cost.
That's especially important with designs that look cheap upfront but create expensive support needs later. A cold spare might reduce installation cost, but if startup takes too long or routine verification is neglected, the plant hasn't really bought reliability. It has bought a story about reliability.
A sound justification package includes:
- Failure scenario definition. What event is being prevented, and how does it disrupt operations?
- Architecture rationale. Why N, N+1, or 2N matches the business consequence.
- Total installed cost. Mechanical, electrical, controls, structural, and commissioning scope.
- Ongoing support cost. PMs, inspections, rotation, testing, and spares.
- Decision threshold. What downtime avoidance or risk reduction makes the project worthwhile.
This also protects engineering credibility. When a plant later asks why a backup compressor still needs quarterly inspections, exercised valves, dryer checks, or control testing, the answer is already embedded in the capital case. Redundancy planning is an operating strategy, not just a purchase order.
Execute the Plan with CMMS and Spare Parts Optimization
Plants lose a surprising amount of value after installation because the standby asset never gets built properly into the maintenance system. It exists in the field, but not in the workflow. The result is predictable. The primary unit gets watched. The standby unit gets assumed.
That problem shows up clearly in an oil and gas booster station. A standby pump may be physically installed and piped correctly, yet still fail the plant if the CMMS record is incomplete, the PM route ignores it, and storeroom inventory doesn't support the failure modes that matter.

Set up the asset structure so the standby unit stays visible
The CMMS needs to reflect the actual reliability strategy. That means the backup pump, motor, coupling, instrumentation, valves, and supporting utilities all need their own asset records and relationship to the protected system.
A good structure includes:
- Parent-child hierarchy: The process system sits at the parent level, with primary and standby assets linked beneath it.
- Clear duty designation: Identify which unit is duty, standby, or rotating reserve.
- Failure coding: Separate failure modes for the primary path and the standby path so analysis stays useful.
- PM logic: Create tasks for both run-condition and idle-condition maintenance.
- Switchover documentation: Store the procedure where operators and planners can retrieve it fast.
For teams cleaning up this discipline, a practical CMMS implementation guide for maintenance teams can help standardize asset hierarchy, PM structure, and parts linkage so standby equipment doesn't disappear into bad data.
Stock the parts that decide whether redundancy actually works
Spare parts strategy is where many redundancy plans often fail. Redundancy failures often occur due to a lack of accessible critical spare parts, and effective planning requires on-site stocking of those items for redundant systems, along with maintenance discipline that prevents delaying repairs on the primary unit only because the spare is running, as discussed in this reliability note on dual redundancy and spares.
That's the practical difference between theoretical and usable redundancy.
In a booster station, the parts list shouldn't just mirror the bill of materials. It should reflect downtime risk and lead time. For rotating equipment, that often means paying close attention to items such as seals, bearings, coupling elements, instrument transmitters, and actuator components that can block restoration.
A standby pump doesn't protect the plant if one unavailable seal kit can keep both trains out of service.
A disciplined execution plan usually includes this short checklist:
- Identify long-lead critical spares. Focus on parts that stop restoration, not on cheap consumables.
- Link parts to both duty and standby assets. Avoid hidden inventory assumptions.
- Trigger repair on the failed primary immediately. Don't let the site operate indefinitely on the backup.
- Assign PM routes to idle equipment. Lubrication, rotation, inspections, and readiness checks must be visible work.
- Record every switchover event. That history tells the team whether the design is effectively protecting production.
Validate Performance and Prevent Silent Failures
The most dangerous backup asset in a plant is the one everyone believes will work because nobody has challenged it. Standby equipment fails, often unnoticed. Grease separates. seals dry out. Batteries weaken. Contacts corrode. Valves stick. Instrument references drift. Operators assume readiness because the tag exists on the drawing.
That assumption is exactly what redundancy planning is supposed to eliminate.
A standby asset that isn't tested is still a single point of failure
Hospitals and data facilities understand this problem well with emergency power systems, but the same principle applies to plant utilities, standby pumps, and reserve compressors. Redundancy must be supported by specific monitoring interfaces and scheduled inspections for each component to ensure continued functionality, because a system without access and maintenance planning will degrade unnoticed and fail catastrophically according to this guidance on inspecting redundant systems.
For plant teams, that means every redundant path needs an inspection and test philosophy, not just a PM frequency. The testing approach should fit the equipment:
- Standby pumps: periodic bump tests, full operating runs, discharge verification, and valve position confirmation
- Emergency generators: load-capable testing, fuel system checks, battery condition review, and cooling system inspection
- Redundant compressors: auto-start verification, pressure recovery check, condensate management review, and control sequence validation
- Bypass lines and dual valves: stroke testing, leak checks, and proof that operators can safely execute the path during an upset
A weak test only proves that the motor turned. A good test proves the system can carry the load the process requires.
The plant shouldn't ask, “Did the backup start?” It should ask, “Did the backup sustain the process under the conditions that matter?”
Condition monitoring closes the loop
Scheduled tests catch readiness problems. Condition monitoring catches degradation before the test fails. That's especially valuable for standby assets that spend long periods idle and then must perform immediately.
Plants typically get the most value when they combine exercise routines with targeted diagnostics such as vibration review, temperature checks, lubrication inspection, motor health assessment, and valve performance verification. Teams building this discipline often find practical ideas in resources on condition based maintenance from MA Hydraulics Ltd, especially where hidden deterioration develops between planned interventions.
The larger maintenance strategy matters too. A site that treats redundant assets as “inspect occasionally and hope” usually carries more risk than a site that aligns standby equipment with a broader predictive vs preventive maintenance approach. Predictive methods help detect degradation. Preventive routines make sure critical tasks still happen on schedule. Redundant systems usually need both.
Documentation closes the final gap. Every test, failure to start, slow transfer, manual intervention, alarm, and restoration delay belongs in the CMMS. That record turns redundancy from a design assumption into operating evidence.
From Plan to Plant Floor Reliability
The plants that do redundancy planning well don't treat it as a one-time capital project. They treat it as a loop. Criticality analysis identifies where failure hurts most. Architecture selection decides how much protection the business needs. Financial modeling justifies the spend against real downtime exposure. CMMS execution and spare parts strategy keep the backup visible. Validation proves the system works when the plant is under pressure.
That closed-loop approach is what separates reliable capacity from expensive duplication. It also keeps maintenance and operations aligned. Operations gets faster recovery and fewer production surprises. Maintenance gets clearer priorities, better parts strategy, and documented inspection requirements. Finance gets a capital decision tied to risk reduction rather than vague insurance language.
In practical terms, redundancy planning works best when it removes specific single points of failure instead of broadly “adding backup.” The difference matters. A second pump may help. A second pump with independent support, tested switchover, tracked PMs, and stocked critical spares protects production.
Plants that want this to last also need the operating system around it. That includes planning discipline, inspection access, test records, and asset hierarchy inside daily maintenance work. A broader view of operations and maintenance strategy is often what keeps a justified redundancy project from fading into another under-managed asset group.
If a plant is weighing a backup pump, standby compressor, generator, or parallel process train, the next step is a grounded review of critical assets, failure modes, spare parts exposure, and downtime cost. Forge Reliability offers a free reliability assessment to identify the biggest single points of failure and the highest-return opportunities for practical redundancy planning.


