
The maintenance manager already knows the scene. A line goes down on second shift. The technician who touched the asset last week is off today. The work order history lives partly in a spreadsheet, partly in paper folders, and partly in someone's memory. Stores has a similar bearing, but no one is certain whether it fits the inboard side of the pump or the standby unit. Production wants an answer in minutes. Maintenance needs facts, not guesses.
That's usually when the fundamental question behind what is EAM shows up. It isn't a software question. It's an operating model question. When a plant runs on disconnected records and reactive work, the problem usually isn't technician effort. The problem is that the plant has no reliable system for controlling assets across their full working life.
An Enterprise Asset Management (EAM) system gives that control structure. It takes a broad strategic view across planning, procurement, installation, operation, maintenance, and decommissioning, which helps organizations maximize value from capital investments while planning replacements and reducing both CapEx and OpEx, as outlined in this overview of enterprise asset management. On the plant floor, that means fewer maintenance decisions made in the dark and more decisions tied to actual asset condition, business impact, and lifecycle cost.
Table of Contents
- Beyond Spreadsheets and Firefighting
- EAM vs CMMS The Critical Differences
- Core Components of an EAM System
- Supercharging EAM with Predictive Maintenance Data
- Key EAM Performance Indicators for Reliability
- EAM Implementation Best Practices and Pitfalls
- Documented Outcomes and Calculating EAM ROI
Beyond Spreadsheets and Firefighting
A packaging plant with several conveyors, fillers, and air compressors rarely fails because the team doesn't work hard enough. It fails because every urgent job displaces planned work. A motor trips, the crew responds. A gearbox starts leaking, it gets watched. A compressor runs hot, someone adds it to a whiteboard. After enough of that, the plant starts living shift to shift.
That's where EAM changes the conversation. Instead of treating maintenance as a stream of isolated repairs, it treats assets as managed business resources from acquisition to disposal. A critical conveyor drive isn't just a repairable object. It has a purchase history, install date, parts usage trend, failure history, labor cost, operating context, and replacement path.
Practical rule: If a plant can't see asset history, spare parts exposure, and maintenance priority in one place, it isn't managing reliability. It's managing interruptions.
In a food plant, that matters fast. A repeated bearing issue on a washdown motor may look like bad luck until the EAM record shows the same failure mode after each sanitation cycle. Then the problem shifts from “replace the bearing again” to “change the seal arrangement, improve mounting practice, and verify washdown ingress control.” That's a reliability decision, not just a maintenance action.
A strong EAM setup also connects maintenance to operations and capital planning. When planners can show which filler, pump, or compressor consumes labor and parts year after year, leadership can make better replacement decisions instead of stretching weak assets one more season. That's the difference between maintenance as overhead and maintenance as an operating discipline. Plants trying to improve that discipline usually benefit from aligning EAM with broader operations and maintenance practices.
EAM vs CMMS The Critical Differences
A lot of plants use the two terms as if they mean the same thing. They don't. A CMMS (Computerized Maintenance Management System) is mainly built to manage maintenance work. An EAM system is built to manage the asset and the business decisions around it.
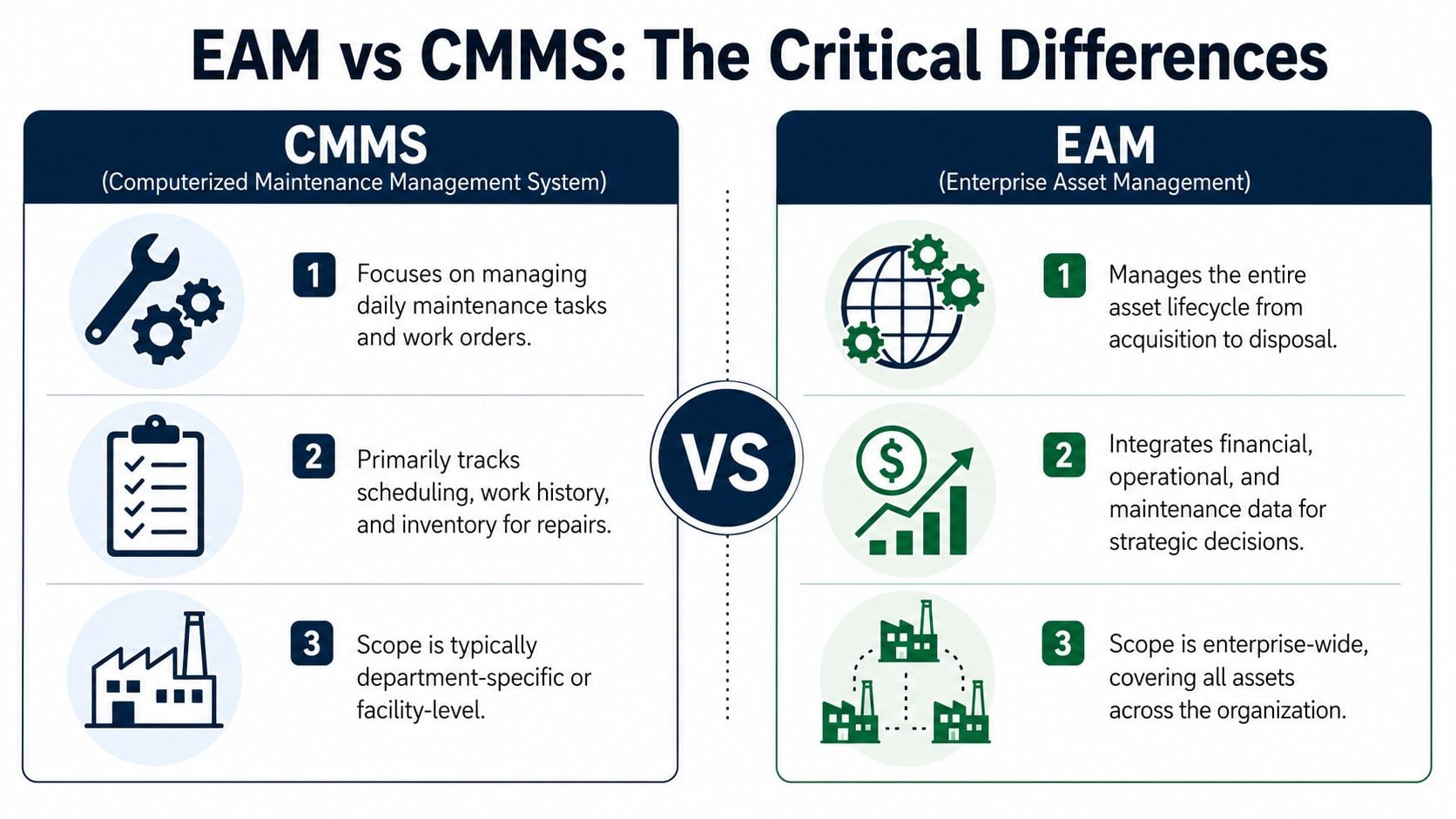
One practical description gets this right. EAM functions as the operational “heart and immune system” of a manufacturing plant, directly integrating maintenance data with production schedules to anticipate and prevent asset failures, while legacy CMMS only address the maintenance stage. That same source notes that benchmarks document 3–5x ROI for asset-intensive organizations in this explanation of EAM's plant-wide role.
Where CMMS stops
A CMMS is useful when the goal is to:
- Manage work orders: Create, assign, close, and document maintenance tasks.
- Track PM schedules: Run calendar-based or meter-based preventive work.
- Control repair inventory: Keep common parts, tools, and reorder points visible.
That's valuable. In many plants, a CMMS is the first step out of paper-based maintenance. But it usually stays focused on the maintenance department.
A pulp and paper mill makes the difference obvious. If a gearbox on a paper machine fails, a CMMS can record the breakdown, issue the repair work order, and log the labor and parts. Useful, but narrow. It doesn't tell the plant whether that gearbox has become a capital replacement candidate, how repeated failures affect throughput, or how procurement and finance should plan around it.
Why EAM changes plant decisions
EAM expands the scope. It brings maintenance, operations, procurement, stores, engineering, and finance into the same asset story.
| Feature | CMMS (Tactical) | EAM (Strategic) |
|---|---|---|
| Primary scope | Work management and maintenance execution | Full asset lifecycle management |
| Main users | Maintenance department | Maintenance, operations, engineering, procurement, finance |
| Data focus | Work orders, PMs, parts, labor history | Cost, performance, lifecycle, risk, replacement planning |
| Decision horizon | Today's maintenance needs | Multi-year asset value and capital planning |
| Business role | Supports maintenance control | Supports enterprise-wide asset decisions |
That broader view changes daily work in practical ways:
- Asset criticality becomes actionable: A brine pump feeding a refrigeration system doesn't get scheduled the same way as a non-critical utility fan.
- Replacement decisions get evidence: Leadership can compare repair burden against replacement cost using real history, not opinion.
- Production and maintenance stop working at cross purposes: Planned outages can be aligned with asset condition and operating demand.
The difference isn't that CMMS is bad. It's that CMMS answers “What maintenance was done?” while EAM answers “What should this organization do with this asset next?”
For reliability engineers, that distinction matters most on equipment with high consequence of failure. A turbine, compressor, extruder gearbox, or high-service water pump needs more than a work order log. It needs lifecycle visibility, cost context, and risk-based planning.
Core Components of an EAM System
The right way to look at EAM modules isn't as a software checklist. Each one gives the reliability team a practical control point. Together they create a single source of truth for asset history, work execution, spares, and decision support.
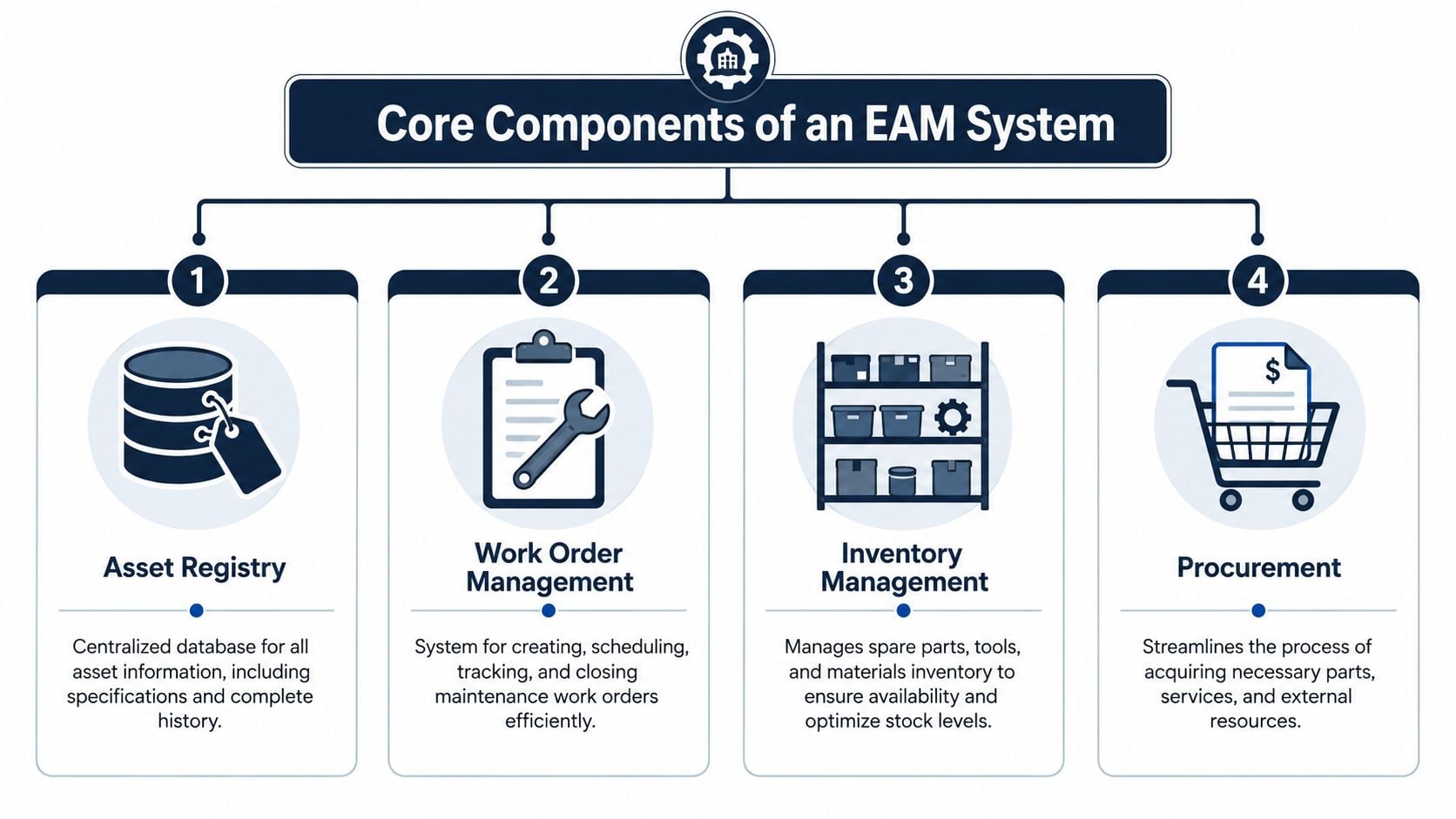
Asset registry and lifecycle control
The asset registry is the backbone. It's the structured record of every critical asset, including nameplate data, location, bill of materials, maintenance history, failure history, and lifecycle status.
In a plastics injection molding plant, the distinction between “press 14 is down” and “the barrel heater circuit on press 14 has repeated failures after startup transitions” becomes apparent. If the plant can't distinguish one heater zone, drive, pump, or cooling loop from another in the data, it can't manage reliability at the failure-mode level.
Lifecycle management extends that record beyond repairs. It tracks what was installed, what changed, what it cost to sustain, and when replacement should be considered. Plants building a stronger system of record around this often improve results through disciplined asset lifecycle management practices.
Work execution inventory and analytics
Work management is where planning discipline lives or dies. A useful EAM setup supports:
- Planned corrective work: Defects found during inspection don't disappear into notebooks.
- Preventive routines: Tasks are scheduled with clear labor, parts, and job steps.
- Feedback capture: Technicians close work with failure codes, symptoms, and repair details.
Inventory and procurement matter just as much. In the same plastics plant, custom mold heaters for a critical press may need controlled stocking because a stockout can stop a high-margin job. Generic hydraulic fittings, on the other hand, shouldn't pile up on the shelf without consumption logic. EAM helps stores and maintenance make those distinctions.
Analytics turns the whole system into a management tool. Good reporting shows which motors fail after washdown, which pump seals recur after alignment work, and which assets absorb disproportionate labor hours. That's when the team stops chasing symptoms and starts managing patterns.
Field insight: If failure codes are weak, analytics will be weak. The software can't fix vague closeout notes like “fixed pump” or “repaired motor.”
Supercharging EAM with Predictive Maintenance Data
A standalone EAM is powerful, but its strategic promise is incomplete if it isn't fed by real condition data. That gap is where many plants stall. They install a platform with strong work order, history, and asset hierarchy capability, then continue scheduling maintenance off static calendars and operator complaints.
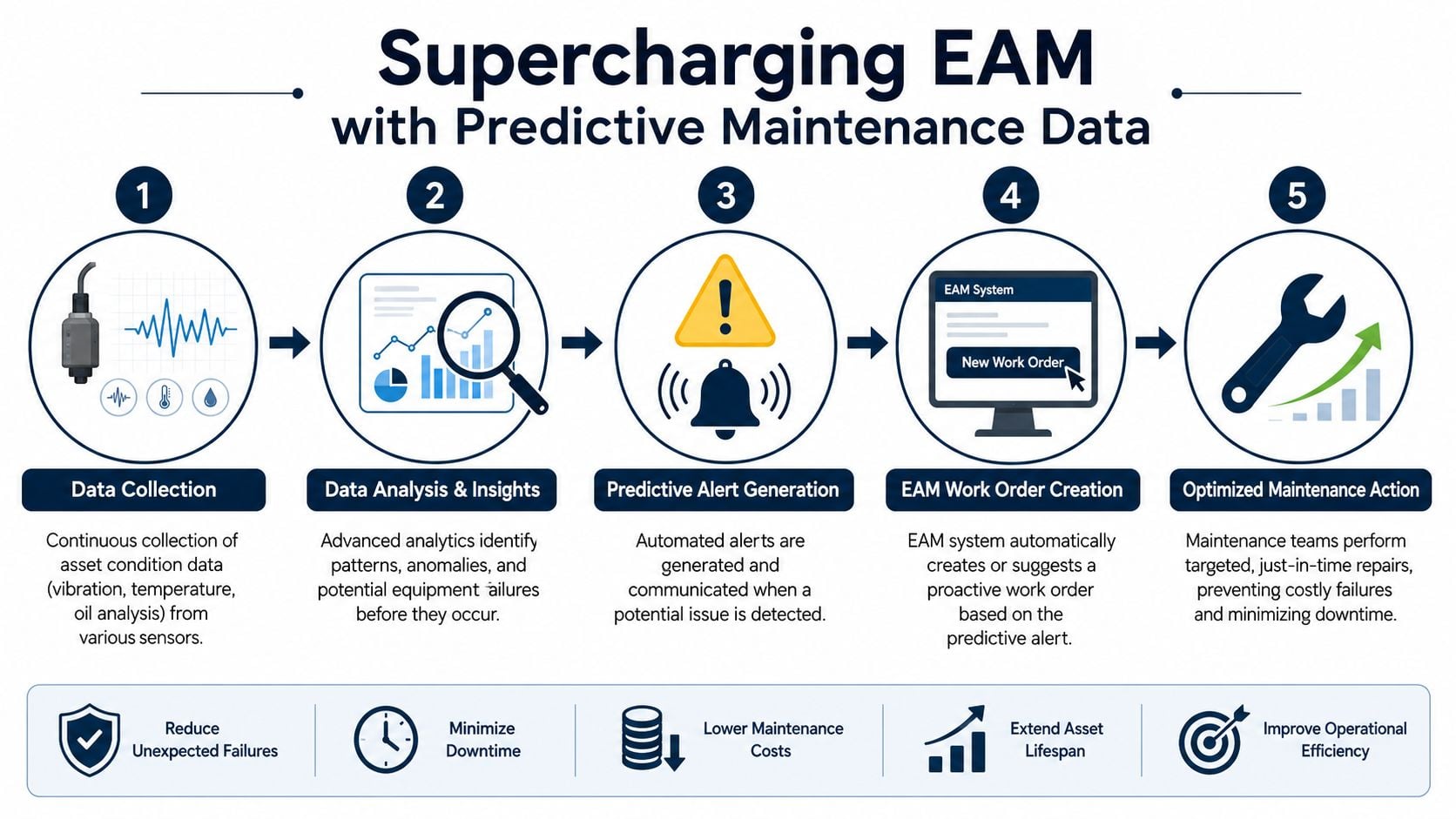
Why standalone EAM falls short
The missing piece is PdM, or predictive maintenance. PdM uses condition-monitoring techniques such as vibration analysis, thermography, and oil analysis to detect developing faults before functional failure occurs. Existing EAM guides rarely explain that standard EAMs often lack native PdM workflow engines, forcing reliability engineers to manually import condition-monitoring data. That gap causes 30%+ delays in failure prediction according to Gartner, as summarized in this discussion of EAM and predictive maintenance integration.
That delay is a real plant-floor problem. A route-based vibration analyst may identify increasing bearing defect frequency on a critical compressor, but if that finding stays in a separate report instead of driving EAM action, the plant still depends on people remembering to do the right thing at the right time.
Data quality becomes a major constraint here. If sensor tags, asset IDs, measurement points, and alarm states don't match the EAM hierarchy, the workflow breaks. Teams that want cleaner integration usually benefit from tightening governance around identifiers, completeness, and consistency. A practical reference on that side of the problem is this guide to data quality metrics.
What closed-loop reliability looks like
When PdM feeds EAM correctly, the plant gets a closed loop:
- Condition data identifies a fault.
- The fault maps to the right asset and component.
- The EAM generates or prioritizes work.
- Planning assigns labor, parts, and timing.
- The completed work updates history for future decisions.
An oil and gas facility with a critical compressor train is a good example. Vibration data may show a developing rolling-element bearing defect. Thermography may show associated heat rise. Oil analysis may indicate wear debris. Instead of waiting for the monthly planning meeting, the integrated workflow can trigger a targeted work order, reserve the bearing kit, and align the repair with a planned production window.
That's the fundamental move from preventive to condition-based execution. The plant stops changing components because the calendar says so and starts intervening because the asset is showing evidence of degradation. Teams comparing strategies on this point often find it useful to review the difference between predictive and preventive maintenance approaches.
Condition monitoring without EAM becomes reporting. EAM without condition monitoring becomes scheduling. Reliability needs both.
There's another gap most vendors gloss over. EAM alone still doesn't replace reliability engineering methods such as RCM (Reliability-Centered Maintenance) and FMEA (Failure Modes and Effects Analysis). RCM defines the right maintenance strategy for the function and consequence of failure. FMEA breaks down how an asset fails, why it fails, and what the effect is. Without that logic, even good condition data can drive poor decisions, such as over-monitoring low-consequence assets and under-protecting production bottlenecks.
Key EAM Performance Indicators for Reliability
Plants usually know they need metrics. The harder part is choosing metrics that help crews make better decisions instead of just producing reports. An EAM system matters here because it provides structured work, asset, and history data that supports reliability KPIs with context.
The KPIs that matter on the plant floor
Several indicators consistently matter in asset-intensive plants:
- OEE: Overall Equipment Effectiveness combines availability, performance, and quality into one operating measure. It helps connect maintenance results to production output.
- MTBF: Mean Time Between Failures shows how long an asset operates between breakdowns. For rotating equipment, it's one of the clearest trend indicators of reliability improvement or deterioration.
- MTTR: Mean Time To Repair shows how quickly the team restores function after failure.
- Schedule compliance: This shows whether planned work is executed when intended.
- Maintenance cost as a percentage of RAV: Replacement Asset Value provides a way to compare maintenance spend against the value of the physical asset base.
Plants working to strengthen failure-interval tracking often need a clear method for calculating mean time between failure, because inconsistent definitions can distort decisions.
Using KPI patterns to find hidden problems
A water treatment plant offers a practical example. If MTTR increases on primary pumps while failure frequency stays roughly stable, the issue may not be the pump design. The issue may be planning quality, crew skill, kitting delays, or poor access to the right spare parts. EAM data can expose whether one crew takes longer on seal changeouts, whether job plans are missing torque and alignment steps, or whether permits slow execution.
Closed-loop reliability becomes visible in this data. EAM systems can integrate vibration analysis directly into work execution, reducing MTTR by 35% and preventing 40% of recurring pump seal failures compared with CMMS-only approaches, according to this practical guide on enterprise asset management software for industrial teams.
That kind of KPI improvement matters because downtime reduction isn't just about avoiding catastrophic failures. It's also about shrinking the long tail of repeat work, troubleshooting delays, and repair variability. For plants looking at the maintenance side of that equation, this resource on how to reduce manufacturing downtime adds useful context.
Watch for this pattern: If MTBF is flat but MTTR worsens, the plant may have a planning and execution problem. If MTTR is steady but MTBF drops, the plant may have an asset condition or strategy problem.
EAM Implementation Best Practices and Pitfalls
Most EAM projects fail for process reasons, not software reasons. Plants get into trouble when they treat implementation like an IT install instead of a reliability and operations redesign.
What to do first
A disciplined rollout usually starts with a few essential elements:
- Rank assets by criticality: Not every motor, pump, fan, or conveyor deserves the same level of detail. Criticality ranking helps the team decide where to build strong bills of material, failure codes, PM tasks, and PdM links first.
- Clean data before migration: Duplicate assets, bad naming conventions, missing serial numbers, and inconsistent locations will poison the system from day one.
- Design for technicians, not conference rooms: If mobile screens don't match field reality, adoption falls fast.
An automotive plant illustrates the point well. One plant improved adoption by putting tablets in supervisors' hands during pilot testing and redesigning work screens around actual lockout, inspection, and changeover steps. Another site tried to push the same rollout from corporate templates, with little plant-floor input. The result was predictable. Technicians worked around the system because the screens didn't reflect how jobs were executed.
What usually goes wrong
The common mistakes are rarely subtle:
- Treating EAM as a records repository: If the plant only uses it to close work orders after the fact, it won't improve planning or reliability.
- Skipping workflow standardization: One crew enters failure data one way, another uses free text, and analytics become almost useless.
- Undertraining planners and supervisors: These roles determine whether the system drives execution or just stores history.
- Ignoring change management: Craftspeople need to see how the tool removes friction, not adds admin work.
Plants planning a serious rollout usually need structured support around CMMS and EAM implementation services because configuration alone won't solve data governance, work process design, or role clarity.
A bad implementation gives the plant digital clutter. A good one gives planners, supervisors, and technicians a common operating language.
The best results usually come from phased deployment. Start with critical assets, standard job plans, accurate spare parts links, and clean failure coding. Then expand. Plants that try to model the entire enterprise in one pass often bury the team in complexity before the first reliability gain shows up.
Documented Outcomes and Calculating EAM ROI
The business case for EAM should be built from operational levers the plant can influence. The core ones are reduced unplanned downtime, lower inventory waste, better labor execution, and longer asset life.
How to build the business case
A documented example from food and beverage shows what that can look like. For plants operating multiple HVAC compressors, EAM-driven lifecycle tracking reduced total cost of ownership by 22%, cut spare-parts overstock by 30%, and extended equipment life by 1.5–2 years through scheduled oil analysis and thermography, as described in this example of EAM software outcomes in industrial operations.
That example matters because it ties ROI to real plant decisions. The value didn't come from “having software.” It came from using lifecycle records, parts control, and condition-based diagnostics to decide when to inspect, when to stock, and when to defer replacement safely.
For reliability leaders, that's the practical answer to what is EAM. It's the system that turns asset history, maintenance execution, and lifecycle economics into better decisions. But it reaches full value only when it's connected to predictive data and reliability methods that deal directly with failure modes, asset criticality, and consequence of failure.
A free reliability assessment from Forge Reliability helps plants identify where EAM, predictive maintenance, and reliability engineering can work together to eliminate unplanned downtime, improve asset life, and build a defensible ROI case before the next major failure forces the issue.


