
A maintenance team replaces the bearings on a critical process pump every shutdown. The schedule is disciplined. The work orders close on time. Then the pump still trips on high vibration during the middle of a production run, cavitates, damages the mechanical seal, and forces operators to cut rate or stop the line altogether.
That situation is common because a clean preventive maintenance schedule doesn't automatically mean the right maintenance strategy is in place. Many failures don't follow the calendar. They develop from operating conditions, installation error, lubrication contamination, process instability, or load changes that a fixed interval won't catch.
That's where Reliability Centered Maintenance becomes useful. It gives maintenance and operations leaders a way to decide what should be maintained, how, and just as important, what should be left alone until risk justifies action.
Table of Contents
- Beyond Preventive Maintenance Why RCM Matters
- The Core Logic of Reliability Centered Maintenance
- A Step-by-Step Roadmap for RCM Implementation
- Integrating RCM with Predictive Maintenance Technologies
- RCM in Action Examples for Critical Plant Equipment
- Common Pitfalls and How to Prioritize RCM Efforts
- Measuring Success and Achieving Continuous Improvement
Beyond Preventive Maintenance Why RCM Matters
A plant can be full of “good PM compliance” and still suffer repeat failures on the same compressor, fan, or gearbox. The reason is simple. Traditional PM often asks, “When was this part last changed?” RCM asks, “What function must this asset perform, how does it fail that function, and what maintenance action changes the risk?”
That shift matters in high-consequence equipment. A cooling water pump doesn't exist to have fresh bearings every outage. It exists to deliver required flow and pressure to protect production and upstream equipment. If wear, misalignment, suction instability, contamination, or operator upset is the underlying cause of failure, replacing parts by the calendar may create work without controlling the risk.
RCM came out of aviation in the late 1960s, and modern aircraft have achieved about 99.5% dispatch reliability through systematic RCM-based maintenance planning, a benchmark described by the Whole Building Design Guide on reliability-centered maintenance. That history matters because it established maintenance as a risk-based engineering discipline instead of a blanket preventive program.
Teams that are still sorting out the difference between broad approaches can first compare industrial maintenance strategies and then look at a more direct breakdown of predictive vs preventive maintenance before launching a formal RCM effort.
Good maintenance strategy doesn't start with a task list. It starts with the consequence of losing function.
Consider a boiler feedwater pump with a standby unit. If one pump can fail over with no process interruption, the maintenance decision is different than for a single pump feeding a continuous chemical reactor. Same asset family. Different operating context. Different consequence. Different maintenance strategy.
The Core Logic of Reliability Centered Maintenance
RCM works when a team stops thinking in terms of equipment parts and starts thinking in terms of asset functions. That sounds simple, but it changes almost every maintenance decision.
Function first, not part first
A fan's function isn't “to have healthy bearings.” Its function is to move a required volume of air at a required pressure, safely and reliably, within the process conditions it serves. A functional failure happens when it can't do that. A failure mode is the specific way that loss occurs, such as bearing wear, blade fouling, looseness, coupling misalignment, or motor electrical degradation. Failure effects are what the plant experiences when that mode occurs, such as reduced draft, overheating, nuisance trips, quality issues, or a safety exposure.
That distinction keeps teams from writing generic PMs like “inspect fan monthly” and calling the job done. RCM forces the question: what exactly is being looked for, and how would that task prevent or predict the specific failure?
A visual summary helps when teaching the logic to operators, planners, and engineers:
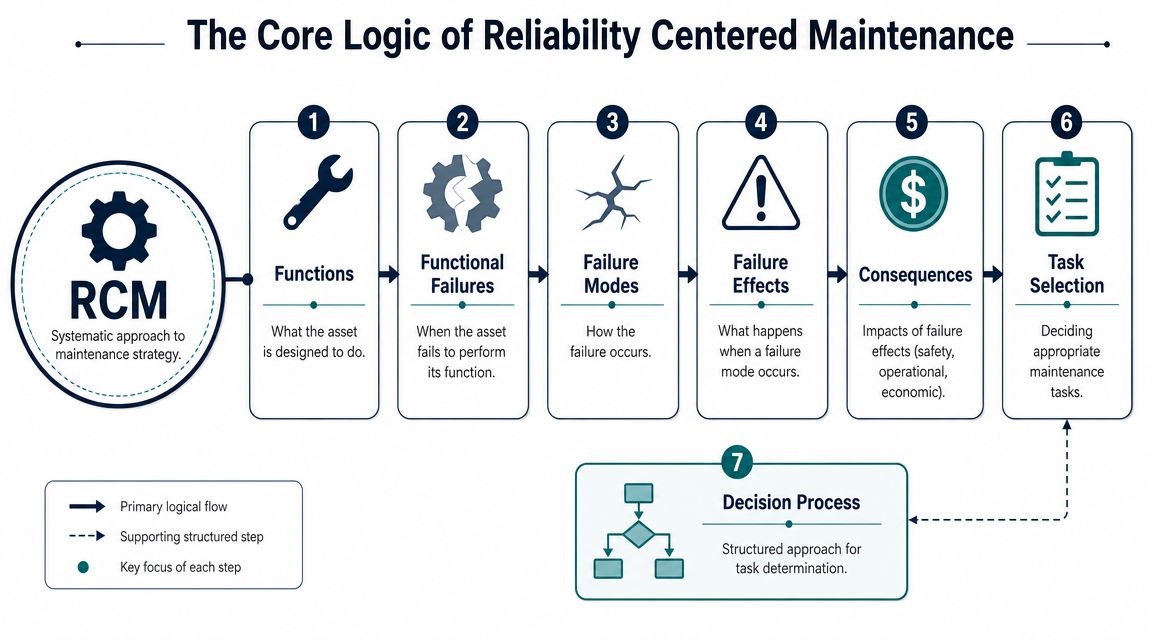
The seven questions that drive the analysis
RCM uses a structured seven-question logic. That disciplined method is one reason aviation implementations commonly report 25–35% maintenance reductions while sustaining very high dispatch reliability, as described in MaintainX's overview of reliability-centered maintenance.
For an induced-draft fan on a process heater, the seven questions typically look like this:
What are the functions and performance standards?
Move combustion air at the required flow. Maintain stable operation. Stay within acceptable vibration and temperature limits.In what ways can it fail to fulfill those functions?
It may fail to start, fail to reach speed, fail to hold airflow, or operate with unstable vibration.What causes each functional failure?
Bearing damage, imbalance from buildup, belt degradation, misalignment, motor winding issues, loose base bolts, or damper problems.What happens when each failure occurs?
The heater trips, combustion becomes unstable, throughput drops, or secondary equipment overheats.Why does each failure matter?
Some consequences are production losses. Others affect safety, environmental compliance, or equipment protection.What can be done to predict or prevent the failure?
Use vibration analysis for bearing and imbalance issues, thermography for electrical connections, inspection for buildup, alignment checks after maintenance, and operating discipline for process-induced stress.What should be done if no proactive task is effective?
Choose redesign, protective devices, procedural change, or run-to-failure if the consequence is low enough.
For teams that need a consistent worksheet to document those failure-mode decisions, a practical bridge is to align the RCM study with a formal FMEA approach for maintenance analysis.
Practical rule: If a task doesn't clearly address a defined failure mode, it probably doesn't belong in the maintenance program.
What good task selection looks like
The output of RCM isn't “more PM.” It's a defensible mix of strategies.
A critical cooling tower fan might end up with:
- Condition-based tasks for bearing degradation and imbalance using route-based vibration monitoring.
- Time-based tasks for lubrication only if the operating environment and lubricant life support a clear interval.
- Failure-finding tasks for protective devices, such as verifying shutdown switches and alarms.
- Redesign actions if repeated soft-foot or base distortion keeps reappearing after repairs.
- Run-to-failure for non-critical accessories with no meaningful consequence.
This is a key advantage of reliability centered maintenance. It removes routine work that doesn't reduce risk and concentrates effort where failure consequences are highest.
A Step-by-Step Roadmap for RCM Implementation
Most RCM programs fail at the start because the plant tries to analyze too much equipment at once. The better path is a narrow, disciplined launch built around a specific system. A compressed air system is a good example because it has obvious production consequences, multiple interacting assets, and clear operating functions.
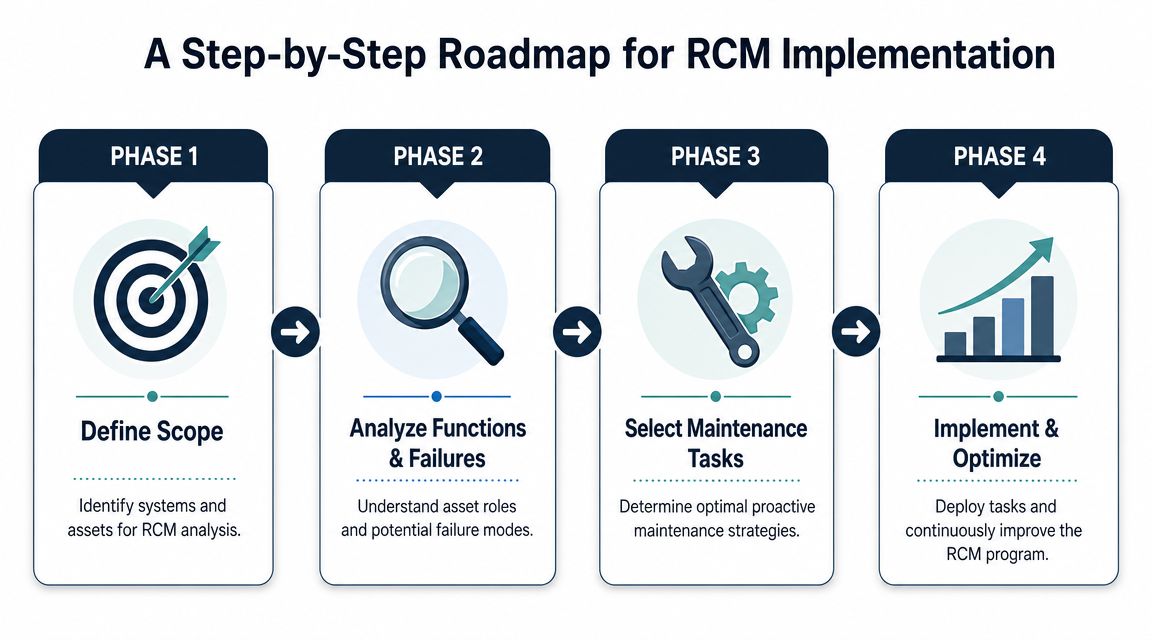
Phase 1 define scope and criticality
Start with the system boundary. For compressed air, that might include the primary compressor, standby compressor, aftercooler, dryers, filters, receiver, condensate drains, distribution header, and critical pressure controls.
Then rank assets by consequence, not annoyance.
A simple screening table works well:
| Asset | Loss of function | Operational consequence | Suggested depth |
|---|---|---|---|
| Main air compressor | Plant air pressure collapse | Line stoppage, valve failures, instrument issues | Full RCM |
| Standby compressor | Reduced redundancy | Higher exposure during upset or maintenance | Focused RCM |
| Filter housing | Differential pressure rise | Efficiency loss, possible downstream contamination | Simplified review |
| Local drain trap | Minor local nuisance if redundant | Limited immediate production impact | Basic PM or run-to-failure |
Criticality should reflect four questions:
- Safety impact. Does loss of function expose people or process safety systems?
- Production impact. Does the asset stop a bottleneck or degrade quality?
- Environmental impact. Could failure create release, spill, or permit exposure?
- Maintainability impact. Are repair lead time, spare availability, or access constraints severe?
A plant that wants to remove waste before adding analysis often benefits from improving planning and labor focus in parallel. That's where maintenance leaders often connect RCM with broader work execution and maintenance cost reduction practices.
Phase 2 analyze functions and failures
Once the scope is set, define each asset's required function in operating terms. For the main compressor, “compress air” isn't enough. The function should include required pressure, flow, air quality, duty cycle, and the operating context.
Then map the failure modes that matter. On a rotary compressor package, common examples include:
- Airend bearing deterioration causing vibration and eventual seizure
- Lubrication breakdown leading to overheating and rotor damage
- Inlet valve malfunction causing poor load control
- Cooler fouling driving high discharge temperatures
- Motor electrical faults causing trip events
- Condensate drain failure sending water downstream
Often, many teams drift into abstract analysis. The fix is to stay physical. Every failure mode should tie to a mechanism that a technician can inspect, test, monitor, or redesign around.
Phase 3 select tasks and build execution
Task selection should answer one question: what action changes the probability or consequence of this failure?
For the same compressor system, that usually means a mix like this:
- Vibration monitoring for airend and motor bearings
- Oil analysis for lubricant condition and wear debris
- Thermography for motor connections and overloaded electrical points
- Performance checks for pressure, temperature, and load-unload behavior
- Operator inspections for leaks, abnormal sound, and condensate carryover
- Scheduled replacement only where age-related behavior is well understood, such as certain consumables or filters
The work only becomes real when the task is translated into an executable job plan. “Check vibration” is not a job plan. A real task specifies measurement points, route frequency, alarm logic, acceptance criteria, and who reviews the results.
A strong RCM study that never becomes a scheduled route, inspection standard, or corrective trigger is only paperwork.
Phase 4 review results and refine
RCM isn't a one-time workshop. The first version is only a starting point. The plant needs feedback from missed failures, false alarms, shutdown inspections, operator rounds, and post-repair findings.
For the compressed air example, common review questions include:
- Were warning signs detected early enough to plan work?
- Did any task create effort without finding actionable defects?
- Did the failure mode list miss process-related causes?
- Did technicians have clear thresholds for escalation?
- Did the standby strategy protect production during repairs?
A plant that treats RCM as a living program will keep adjusting frequencies, thresholds, and task ownership. A plant that treats it as a binder on a shelf won't change reliability at all.
Integrating RCM with Predictive Maintenance Technologies
RCM decides what needs to be controlled. Predictive maintenance decides how the plant will detect the onset of failure. Those are related, but they aren't the same thing.
That distinction matters because plants often buy condition monitoring tools before they've defined the failure modes that justify them. The result is a flood of data with no clear decision path. The useful sequence is the reverse. RCM identifies the credible failure mode, the consequence, and the needed warning time. Then the team chooses the technology that can detect that failure mode early enough to act.
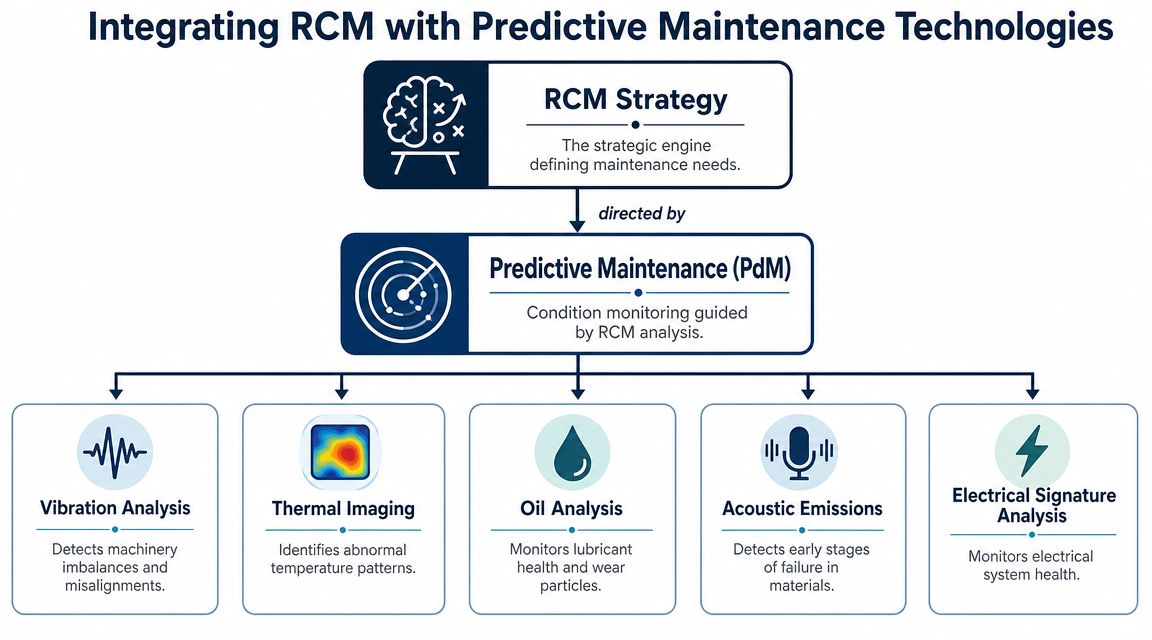
Match the failure mode to the detection method
A core RCM insight is that many equipment failures are not age-related, so time-based overhauls are often ineffective. For pumps and motors, deterioration from modes like misalignment or bearing damage can often be found with predictive technologies instead of relying on the calendar, as discussed in Augury's guidance on reliability-centered maintenance.
For rotating assets, the mapping should be direct:
| Failure mode | Best-fit detection method | Why it fits |
|---|---|---|
| Bearing outer race damage | Vibration analysis, ultrasound | Detects repetitive impact and high-frequency friction early |
| Misalignment | Vibration analysis, precision alignment verification | Shows directional vibration pattern and confirms correction |
| Lubrication degradation | Oil analysis, ultrasound | Confirms lubricant condition and friction changes |
| Loose electrical termination | Thermography | Finds resistive heating under load |
| Rotor bar or stator issues | Motor current signature analysis | Detects electrical fault patterns without disassembly |
| Steam trap or air leak losses | Ultrasound | Finds leakage and flow anomalies quickly |
A gearbox on a critical mixer is a good example. If the RCM study identifies gear tooth wear as a high-consequence mode, the maintenance task shouldn't default to “overhaul every outage.” Better choices may include periodic oil analysis for wear debris, vibration trending at bearing locations, and load-specific inspection triggers after process upset.
A practical condition-based framework can also be seen in resources like MA Hydraulics Ltd on maintenance solutions, especially for teams shifting from fixed PM routines toward equipment-condition decisions. Plants exploring more advanced analytics often pair that with a review of predictive maintenance and machine learning applications.
Where condition monitoring fits and where it does not
Predictive tools are powerful, but they only work when the failure mode has a measurable warning period. If a component fails suddenly with no detectable progression, then condition monitoring won't save it. The answer may be redesign, protective systems, stocking strategy, or accepting run-to-failure if the consequence is low.
That's why a blanket “put sensors on everything” strategy rarely pays off. A better filter is:
- Use condition monitoring when failure develops over time and the plant can act on the warning.
- Use interval maintenance when age or duty cycle has a clear relationship to failure.
- Use failure-finding tasks for dormant protective functions.
- Use redesign when maintenance tasks don't meaningfully reduce risk.
- Use run-to-failure when the asset is non-critical and the consequence is acceptable.
Predictive maintenance is not a maintenance strategy by itself. It's a detection method inside a larger reliability strategy.
On pumps, motors, compressors, and fans, the strongest programs tie every collected data point back to a named failure mode, an alarm rule, and a defined response. Without that chain, teams collect trends but still miss failures.
RCM in Action Examples for Critical Plant Equipment
The easiest way to judge whether an RCM program is practical is to test it against real machines. If the output doesn't lead to different decisions on actual equipment, the analysis is too generic.
Centrifugal pump
Take a multistage centrifugal pump feeding a continuous process. One functional requirement is maintaining flow and discharge pressure. A common failure mode is loss of hydraulic performance from internal wear, recirculation, suction instability, or impeller damage.
The right tasks depend on the mechanism. If the pump is degrading because wear-ring clearance is opening up, a fixed bearing replacement interval won't solve the problem. A better strategy combines vibration analysis, operating point review, suction condition checks, and periodic performance comparison against expected head and flow. If cavitation is the driver, maintenance must also involve process conditions, not just mechanical repair.
Air compressor
A plant air compressor often gets maintained like a packaged utility. That's a mistake when the system supports instruments, air-operated valves, and production equipment.
A common functional failure is inability to supply stable pressure. One failure mode is cooler fouling that drives discharge temperature up and accelerates lubricant degradation. The selected tasks should include temperature trending, cooler inspection, lubricant condition checks, and confirmation that drains and separators are functioning properly. If the compressor repeatedly runs hot after cleaning, the right RCM outcome may be redesign of airflow, enclosure ventilation, or duty cycle rather than shorter PM intervals.
If the same failure keeps returning after the scheduled task was completed, the plant doesn't have a maintenance problem alone. It has a strategy problem.
Large electric motor
For a large process motor, the function is torque delivery under the required load profile. Failures can be mechanical or electrical. Bearing damage, shaft voltage effects, insulation breakdown, contamination, and alignment errors all show up differently and need different controls.
A practical RCM outcome might include vibration analysis for bearing condition, motor current signature analysis for electrical defects, thermography for connections, and precision alignment after every uncoupling. If the motor sits on a weak base and repeatedly develops soft-foot, no inspection frequency will permanently solve it. The effective action is base correction.
Gas turbine
Gas turbines deserve full RCM treatment because the consequences are usually high and the failure mechanisms are complex. Functional failures include loss of power output, unstable combustion, inability to start, and forced trip.
A specific failure mode might be hot-section blade erosion or fouling that reduces efficiency and raises thermal stress. The selected controls should include borescope inspections, performance trending, filtration discipline, and operating reviews after abnormal starts or fuel quality events. In this type of system, the line between maintenance and operations is thin. RCM works best when operators are part of the decision process, because many damaging conditions originate in startup, loading, and process control behavior.
Common Pitfalls and How to Prioritize RCM Efforts
One of the biggest mistakes in reliability centered maintenance is assuming every asset deserves a full study. It doesn't. The analysis itself takes time, labor, plant knowledge, and follow-through. If a team applies full RCM to every conveyor, utility pump, and low-impact motor, the program stalls before it improves reliability.
A more useful question is whether the expected reduction in operational risk justifies the analysis effort. That's the point many plants miss.

Where teams lose time
A key issue is knowing when RCM should be scaled down or not done at all. The process is resource-intensive and is meant to be applied selectively to preserve life-cycle value, which makes criticality-based screening essential for low-impact assets, as noted in Tractian's discussion of reliability-centered maintenance.
The most common failure points look like this:
- Analysis paralysis. The team builds massive worksheets for assets that don't justify the effort.
- Poor participation. Operators, technicians, and planners aren't involved, so real failure mechanisms get missed.
- Task inflation. Every identified risk turns into another PM, even when the task won't detect or prevent the failure.
- No execution path. The workshop ends, but job plans, routes, and thresholds never change.
- No review loop. The original study survives unchanged even after repairs, process changes, and repeat failures prove it incomplete.
How to right-size the effort
A turbine, primary process compressor, or bottleneck kiln drive usually deserves a deep study. A non-critical sump pump with installed redundancy usually doesn't. The right response there may be a simplified decision: basic inspection, spare on shelf, and run-to-failure if consequence is low.
A practical prioritization method is to sort assets into three levels:
| Asset level | Typical approach | Example |
|---|---|---|
| High consequence | Full RCM with cross-functional review | Turbine, reactor agitator, main air compressor |
| Medium consequence | Focused failure-mode review | Production conveyor drive, cooling tower fan |
| Low consequence | Basic PM optimization or run-to-failure | Redundant utility pump, non-critical exhaust fan |
That's how plants avoid over-engineering. The goal isn't to do more analysis. The goal is to put the right level of engineering on the right asset.
Measuring Success and Achieving Continuous Improvement
A reliability centered maintenance program should show up in the operating metrics plant leaders already track. If the strategy is working, critical assets fail less often, failures are found earlier, repairs become more planned, and maintenance labor shifts away from emergency response.
What to measure on the plant floor
The most useful indicators are usually straightforward:
- MTBF. Critical assets should run longer between functional failures.
- MTTR. Planned work and clearer fault detection should shorten restoration time.
- Reactive work ratio. Emergency work should decline as condition-based tasks and better planning take hold.
- Schedule compliance. The plant should execute the tasks that RCM identified as worth doing.
- Repeat failure rate. The same pump, motor, or gearbox shouldn't keep coming back with the same defect.
For teams that need a consistent way to define one of those core metrics, this guide on how to calculate mean time between failure is a practical starting point.
What continuous improvement actually looks like
Improvement doesn't come from adding more tasks every quarter. It comes from refining the strategy based on evidence. If vibration routes keep detecting bearing distress after every motor changeout, the problem may be installation precision, not inspection frequency. If operator rounds repeatedly catch seal water loss before pump damage occurs, that task deserves to stay. If a monthly check never finds actionable defects, it should be challenged.
Lean thinking applies here too. The same discipline used in optimizing warehouse operations applies to maintenance systems. Remove wasted steps, standardize what works, and keep the process tied to actual operational value.
A mature RCM program doesn't become larger every year. It becomes sharper.
A plant doesn't need a bigger PM library. It needs a maintenance strategy that matches failure consequence, operating context, and actual machine behavior. Forge Reliability helps industrial teams build that strategy through practical RCM, condition monitoring, and asset-criticality work grounded in plant-floor execution. If critical equipment is still failing despite scheduled maintenance, request a free reliability assessment and identify where the current strategy is missing the underlying failure drivers.


