
A plant manager usually sees the warning signs before anyone says “we need APC.” Operators keep chasing the process. Quality drifts when feed changes. A compressor, pump, or fired heater spends too much of its life near the wrong operating point. Energy use climbs, alarms pile up, and maintenance gets pulled into problems that started as control issues but end as equipment stress.
That's where advanced process control software becomes a reliability decision, not just a controls upgrade. A stable process is easier on valves, rotating equipment, heat-transfer surfaces, and operators. A poorly deployed APC application does the opposite. It adds another layer of complexity, depends on bad instruments, and gets bypassed the first time production feels uneasy.
Reliability engineers, maintenance managers, and operations leaders don't need another abstract discussion about algorithms. They need a practical guide to putting APC in service without creating new failure modes.
Table of Contents
- Beyond the DCS Navigating Process Instability
- Core Strategies of Advanced Process Control
- APC Architecture and Integrating with Plant Controls
- Implementing APC Models from Data to Commissioning
- Common Pitfalls and APC Reliability Best Practices
- Measuring Performance KPIs and Calculating ROI
- Integrating APC with Your Asset Reliability Program
Beyond the DCS Navigating Process Instability
A standard DCS does its job well when the process is predictable and the loops are mostly independent. Many plants aren't that simple. In a chemical unit, a small change in feed composition can move temperature, pressure, and product quality at the same time. In a refinery fractionation section, one adjustment meant to protect product spec can upset reflux, reboiler duty, and column pressure together. Operators end up running with extra margin because the plant won't hold still.
That conservative operation has a reliability cost. Valves hunt. Pumps recycle more than they should. Heat exchangers foul faster when temperatures swing. Compressors and turbines see avoidable load variation. The process may stay online, but it doesn't stay healthy.
A useful way to think about APC is as a supervisory “master operator” that watches the whole picture and makes coordinated moves before instability grows. It doesn't replace the DCS. It gives the DCS better targets. When advanced process control software is deployed correctly, the result isn't just tighter control. It's fewer violent corrections, fewer excursions into alarm territory, and less wear caused by constant process upset.
Consider a reactor train with aging catalyst. As catalyst activity changes, the old operating window starts to move. The base PID loops can still hold individual temperatures and flows, but they can't see how those variables interact over the next several minutes. APC can. It predicts where the process is heading and adjusts multiple manipulated variables together, instead of waiting for each loop to react after the fact.
Practical rule: If operators are spending most of their time stabilizing a unit instead of optimizing it, the plant has already outgrown a base-layer-only control strategy.
Plants that are already looking at plant optimization services usually find the same thing. The biggest gains often start with variability reduction. Throughput and energy benefits follow, but reliability improves first because the assets stop absorbing every upset.
Core Strategies of Advanced Process Control
A unit can stay on rate and still punish equipment. That usually happens when control strategy focuses on hitting targets while ignoring how hard the plant has to work to stay there. The core APC methods that matter most from a reliability standpoint are model predictive control, inferential control, and constraint management. Used well, they cut variability, reduce operator firefighting, and keep equipment away from the conditions that drive chronic wear.
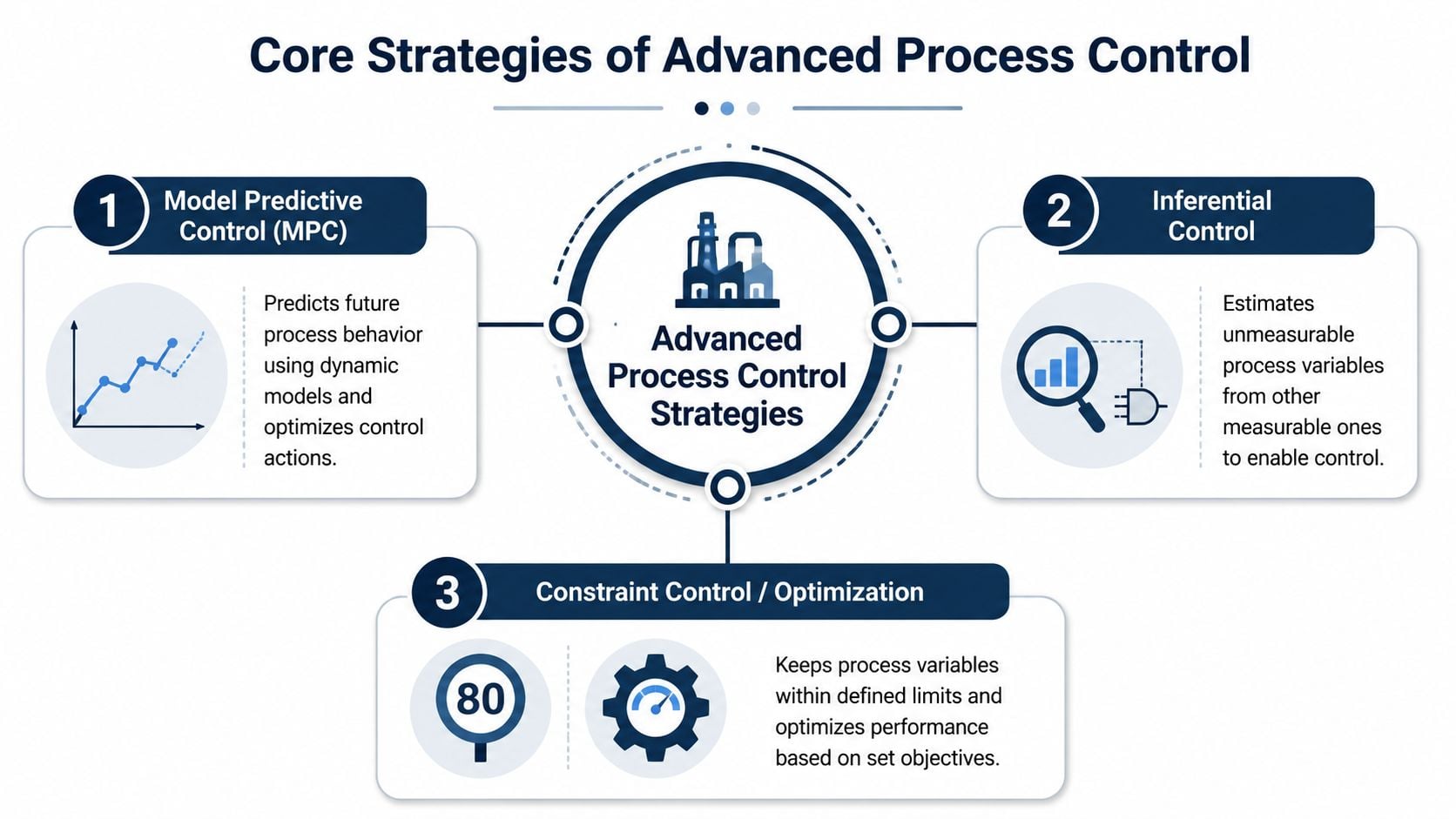
Model predictive control in plant language
Model Predictive Control, or MPC, coordinates multiple moves before the process starts to drift into trouble. A basic loop corrects one variable at a time after error appears. MPC uses a process model to calculate how several variables will respond over the next few minutes, then chooses a set of moves that keeps the whole unit under control.
That matters in real equipment, not just in theory. On a distillation column, one change in reflux or reboiler duty can improve one product cut and upset another. On a boiler, a change in fuel or air can affect steam conditions, draft stability, and emissions at the same time. MPC handles those interactions directly, which means fewer sharp corrections, fewer oscillations, and less repeated movement in valves, dampers, and rotating equipment.
The trade-off is maintenance of the model itself. If feed characteristics change, heat-transfer conditions foul, catalyst activity declines, or instrumentation drifts, model accuracy slips. Plants that treat MPC as a one-time project usually see the same pattern. Performance looks good after commissioning, then operators lose confidence as the controller starts making moves that no longer fit the process. Model upkeep is part of APC ownership, not an optional cleanup task.
Inferential control when analyzers are slow or unreliable
Some variables matter too much to wait on. Composition, moisture, viscosity, and other quality indicators often arrive late from a lab or from an analyzer with poor availability. An inferential sensor, or soft sensor, estimates those values from faster measurements such as temperatures, pressures, flows, density, or power draw.
This can improve both control and reliability. If a dryer inferential catches moisture drift early, operators do not have to make large burner and airflow changes after an off-spec result shows up. If a reactor quality estimate updates continuously, the unit can stay closer to target without the repeated overcorrection that drives temperature cycling and unnecessary stress on internals.
Inferentials also fail in predictable ways. They degrade gradually when process relationships shift. They become unreliable when one bad transmitter feeds the estimate. They can also create bad habits if the site starts trusting the model more than the instruments and analyzers that verify it.
Use inferentials selectively:
- Apply them where measurement delay causes repeated overcorrection or quality giveaway.
- Avoid them where base instrumentation has poor calibration discipline or frequent signal loss.
- Compare them against lab or analyzer results on a defined schedule, so drift is caught before operations start steering by a bad estimate.
Constraint handling without running equipment to the edge
A constraint is any limit the process must respect. Some are obvious, such as pressure, temperature, level, and product quality limits. Others are reliability limits that plants often manage informally, such as valve travel saturation, compressor surge margin, furnace skin temperature, exchanger approach limits, or recurring operation near a known vibration problem.
Good APC makes those limits visible and active in the control strategy. It does not just push for more rate or lower energy use. It decides how close the unit should run to each boundary and which limits deserve extra margin because the consequence of crossing them is expensive.
That distinction matters. A heater may be able to deliver more duty, but repeated operation near a skin-temperature concern can shorten tube life. A compressor may tolerate operation near its limit for a period, but living there increases risk and operator stress. APC should protect the profitable operating window, not shrink asset life to chase small gains.
For teams responsible for operation and maintenance support, this is the standard to hold. Every APC objective should be paired with equipment protection logic, operating envelopes, and clear ownership of alarm limits, constraint priorities, and override rules. If those decisions are left vague, APC becomes another source of conflict between production and maintenance instead of a tool that improves both.
APC Architecture and Integrating with Plant Controls
The usual failure starts in the control room at 2 a.m. APC makes a move, a valve does not respond the way the model expects, the board operator sees the process drift, and the controller gets switched to manual. If that happens a few times, the plant stops treating APC as an operating tool and starts treating it as a risk.
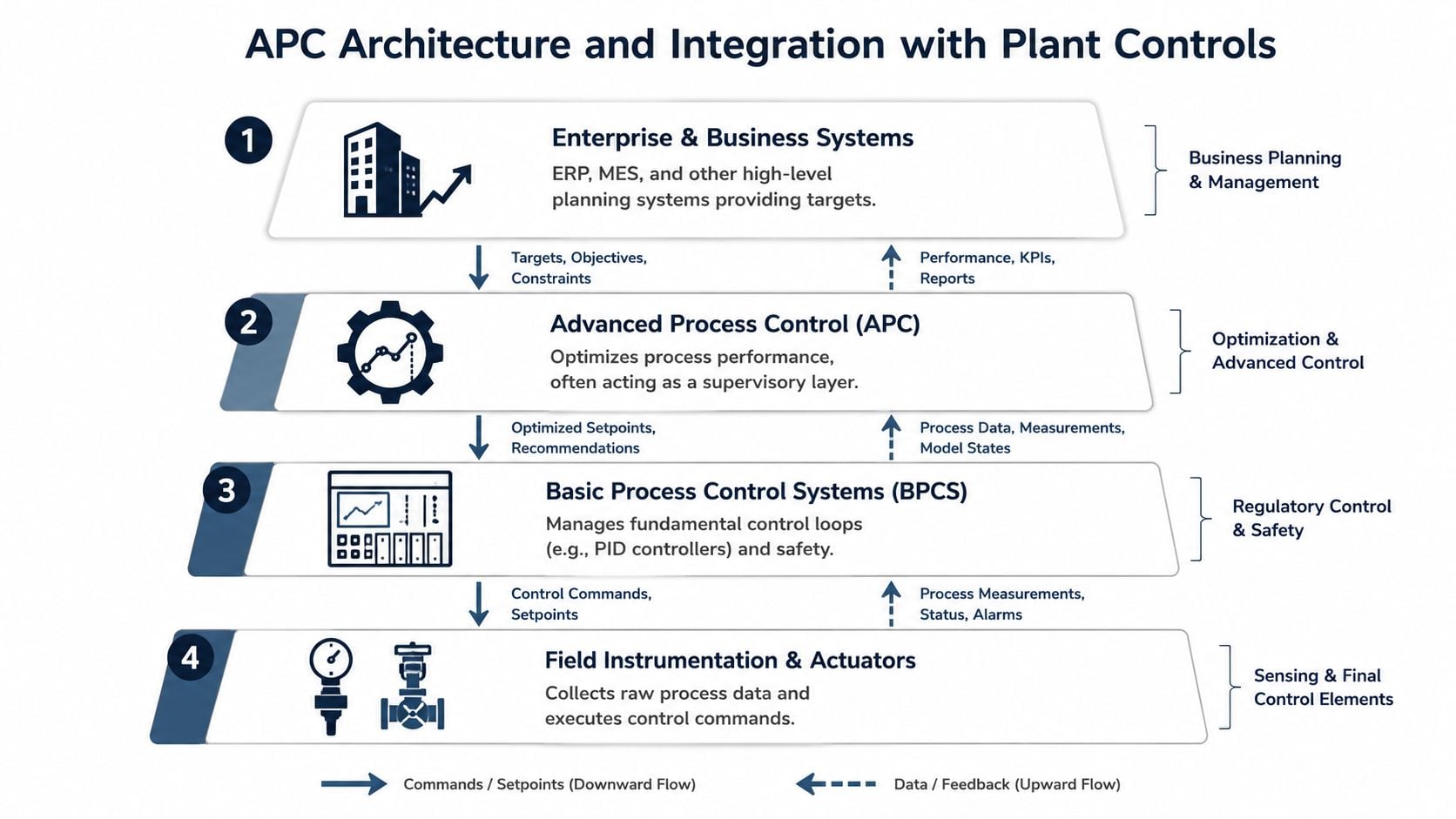
The architecture determines whether APC becomes a stable production aid or another source of maintenance work. APC belongs in a supervisory role above the base controls. The DCS or PLC keeps the process stable, executes sequences, handles permissives, and owns the interlocks. The safety system remains separate. APC reads the plant state, calculates coordinated moves, and writes targets or setpoints back to selected loops.
That separation matters for reliability as much as for control integrity. If the APC server drops offline, communications fail, or the model is temporarily wrong, the unit should continue to run on base control without creating an operator recovery event. Plants that ignore this point usually pay for it later through nuisance mode switching, mistrust, and avoidable production loss.
A practical control stack looks like this:
| Layer | Main role | Reliability concern |
|---|---|---|
| Field devices | Measure process conditions and move valves or drives | Drift, stiction, poor position feedback, bad signal filtering |
| Basic process control | Hold loops, execute sequences, manage interlocks | Loop interaction, poor tuning, failed I/O, unstable cascade behavior |
| APC layer | Coordinate multivariable moves and manage constraint priorities | Model decay, bad assumptions, communication faults, weak ownership |
| Planning and business systems | Send production, quality, and energy targets | Frequent target swings, conflicting objectives, unrealistic economics |
The data path between these layers needs the same discipline as any other production-critical interface. Read permissions, write permissions, update rates, bad-quality tag handling, failover behavior, and time synchronization should all be defined before commissioning. "It usually works" is not enough if the controller is pushing a unit close to throughput, energy, or quality limits.
One rule is simple. If shutting off APC makes the unit unsafe, the architecture is wrong.
The same rule applies to maintainability. Operators need a clean handoff between APC, monitor mode, and conventional control. Instrument technicians need to know which tags are APC-critical. Control engineers need a version-controlled way to manage model changes, constraint edits, and logic updates. Without that discipline, every troubleshooting event turns into a debate about whether the problem started in the process, the valve, the measurement, the base loop, or the APC application.
A pasteurization system in food and beverage shows the point well. The process looks easy until flow changes, inlet temperature shifts, and steam header variation start fighting each other. Base loops can hold individual temperatures and flows, but they do not coordinate the whole thermal profile very well under changing conditions. APC can supervise the heat exchanger train and holding section by adjusting steam demand, recirculation targets, and throughput limits together while the DCS retains direct loop control.
That architecture helps reliability when it is done properly. Smoother steam demand reduces valve wear and hunting. Tighter temperature control reduces repeated thermal stress on plates, seals, and connected piping. More stable recirculation lowers the chance of nuisance trips tied to weak differential conditions or marginal flow.
The catch is that APC often exposes equipment problems that operators have been compensating for manually. A sticky steam valve, a slow temperature element, a biased flowmeter, or a badly tuned cascade can all make the APC layer look unstable. The controller is not always the source of the problem. It is often the first system that forces the plant to deal with hidden actuator and instrumentation defects.
Before integration, review the following with operations, maintenance, and controls in the same room:
- Write scope: Define exactly which tags APC can write to, under what operating states, and with what rate limits.
- Fallback behavior: Set the expected response for communication loss, bad input quality, analyzer failure, and out-of-service instruments.
- Valve readiness: Confirm travel response, deadband, stiction, and position feedback on APC-critical final elements.
- Loop condition: Fix unstable or poorly tuned regulatory loops before asking APC to coordinate them.
- Alarm ownership: Decide who owns APC alarms, performance alarms, and model health alerts on each shift.
- Model maintenance: Assign responsibility for keeping constraints, gains, and operating envelopes current as the plant changes.
Plants that already use predictive maintenance and machine learning methods for asset reliability usually have an advantage here. They are already used to monitoring signal health, detecting degradation early, and treating software outputs as part of an equipment decision process rather than as a black box.
That is the right operating mindset. APC should reduce process variability without increasing support burden. If the integration design respects fallback control, equipment limits, operator workflow, and model maintenance, APC improves throughput and energy performance while protecting asset life. If those pieces are weak, the plant gets a controller that works during the demo and becomes another bypassed application after startup.
Implementing APC Models from Data to Commissioning
An APC project succeeds or fails long before anyone presses “on.” The hard work is in data quality, test discipline, and commissioning behavior. Plants that treat APC like a software installation usually end up with a controller that looks impressive in a meeting and gets bypassed on night shift.
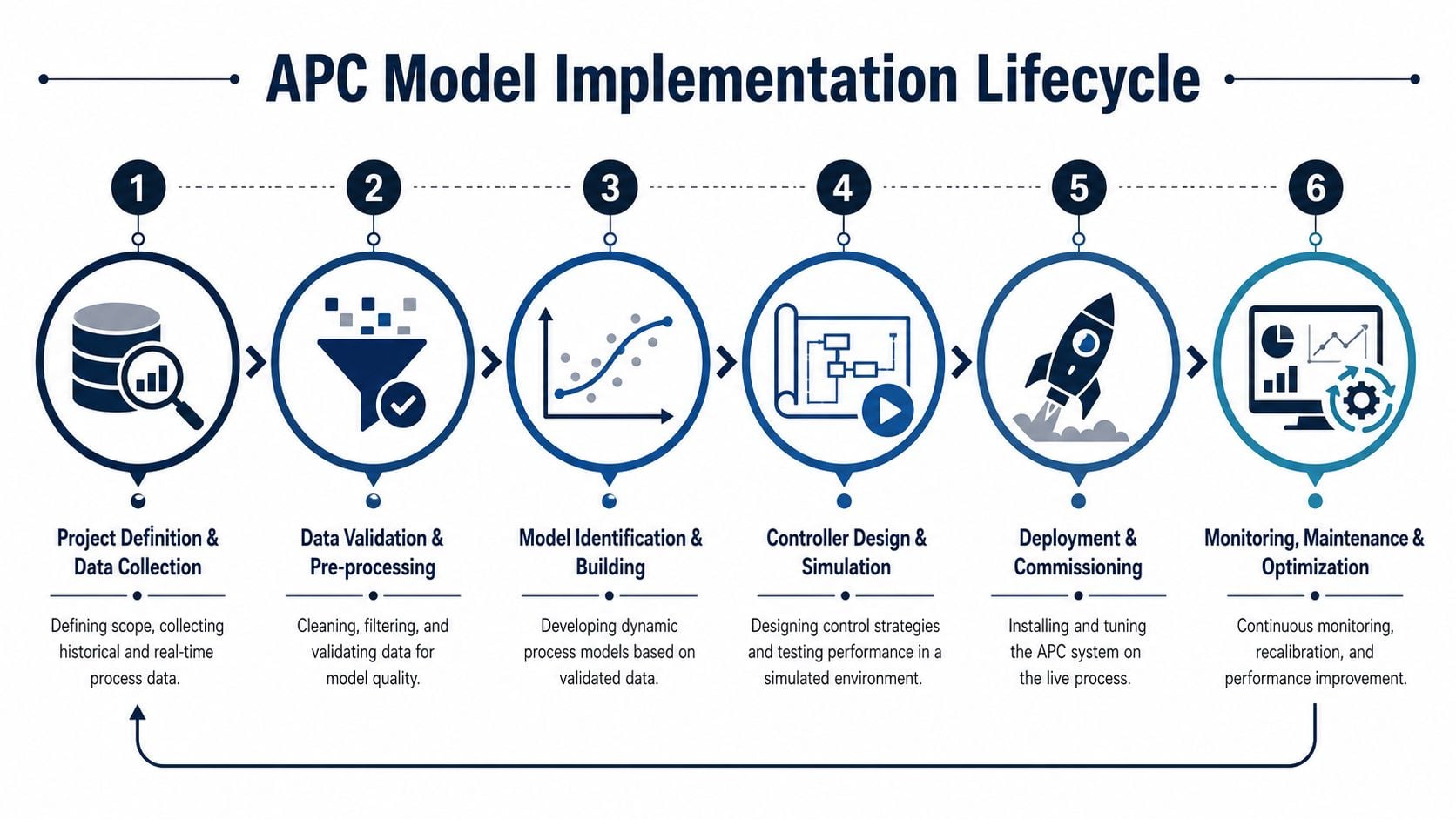
Start with instrument trustworthiness
The first gate is brutally simple. Can the plant trust its measurements?
A combustion turbine in power generation shows why this matters. If fuel flow measurement is noisy, inlet guide vane position feedback is biased, or exhaust temperature signals disagree, any APC model built on that data will be weak. The software may still produce moves, but they won't reflect the machine's real dynamic behavior.
Before model work begins, the project team should verify:
- Signal quality: Look for flat-lined values, spikes, dropouts, clipping, and suspicious filtering.
- Calibration state: APC-critical transmitters need stronger discipline than “close enough for operations.”
- Time alignment: Historian tags must be synchronized well enough to preserve the cause-and-effect sequence.
- Valve and actuator response: A controller can't predict around hidden stiction forever.
This stage often uncovers neglected reliability problems. A transmitter with drifting bias, a sticky fuel valve, or a lagging damper positioner may have been tolerated under manual operation. APC exposes those weaknesses immediately.
Step testing and model building
Once the instrumentation is credible, the plant moves into step testing. A step test is a planned change to a manipulated variable so engineers can observe how the process responds over time. The point isn't to upset the unit. The point is to reveal process dynamics cleanly enough to build a useful model.
For a combustion turbine, the team may introduce controlled changes in fuel demand or inlet guide vane position within approved operating boundaries. They then observe impacts on exhaust temperature profile, load response, efficiency indicators, and emissions-related constraints. The resulting data helps identify gains, delays, interaction strength, and process nonlinearity.
Step testing fails for predictable reasons:
- The moves are too small. The response gets buried in normal plant noise.
- The moves are too aggressive. Operators lose confidence or production intervenes.
- Other changes happen at the same time. Feed, utility, or operator actions contaminate the data.
- No one defines the test window properly. The process never reaches a usable response.
A disciplined test plan prevents most of that. It should define who approves moves, what operating envelope is allowed, what tags will be monitored live, and when the test will pause.
A bad step test doesn't just waste time. It trains operations to distrust the whole APC effort.
After testing, engineers build dynamic models and validate them offline. Offline simulation means running the proposed APC logic against historical or replayed plant behavior before it can write to the live process. During this process, weak relationships, missing constraints, and unrealistic tuning assumptions should be caught.
Plants exploring broader digital support, including predictive maintenance and machine learning applications, should keep the roles separate here. APC models control. Predictive analytics diagnose. Mixing those purposes too early creates confusion about what the software is supposed to do.
Commissioning without losing operator confidence
The commissioning sequence should protect the process and the workforce's trust.
A practical sequence often looks like this:
| Phase | What happens | What the team should watch |
|---|---|---|
| Monitor mode | APC reads the process and predicts actions without writing | Prediction error, missing signals, operator observations |
| Limited closed loop | APC controls a narrow set of variables | Valve movement, stability, alarm response, fallback behavior |
| Expanded scope | More constraints and objectives are enabled | Interaction quality, product impact, operator workload |
| Steady-state support | APC becomes the normal supervisory layer | Runtime discipline, performance drift, maintenance triggers |
For the turbine example, monitor mode is especially important. The APC may correctly predict that a change in guide vane position should improve response under certain ambient conditions, but if operators haven't seen it work safely, they won't let it own the move. Read-only operation gives them a chance to compare APC recommendations with expected machine behavior.
Training also needs to be practical. Operators don't need the mathematics. They need to know what the APC is controlling, what constraints it respects, when it will back off, and what to do if a key instrument fails. Maintenance needs the tag list, health checks, and model-critical hardware map. Reliability needs a method for documenting controller-induced failure modes.
Commissioning is complete only when the application is maintainable by the plant that inherited it.
Common Pitfalls and APC Reliability Best Practices
Most APC failures aren't caused by control theory. They come from neglected assets, drifting process conditions, and weak ownership after startup. The software gets blamed because it sits at the top of the stack, but the root causes usually live lower in the plant.

Why APC applications decay
Model degradation is the most common long-term problem. The process that was step-tested months ago isn't the same process today. Catalyst ages. Fouling increases pressure drop and changes heat transfer. Feed properties shift. Equipment wear alters valve gain, pump performance, or compressor efficiency. The APC model may still run, but its predictions become less trustworthy.
A pulp and paper bleaching tower makes this obvious. Sensor fouling, liquor chemistry changes, and production-grade swings can change the relationship between manipulated variables and final brightness or residual chemistry. If the APC application isn't reviewed and refreshed, it starts making corrections based on yesterday's process physics.
This doesn't mean APC is fragile. It means it needs lifecycle care. Plants maintain compressors because bearings wear. They should maintain APC because the process moves.
A sound maintenance approach includes:
- Scheduled performance review: Compare expected controller behavior to actual closed-loop results.
- Trigger-based model check: Investigate after major feed, catalyst, equipment, or operating strategy changes.
- Version control: Keep a record of model updates, constraint changes, and tuning revisions.
- Ownership clarity: One team must own runtime performance, and it can't be “everyone.”
Failure modes that maintenance teams can prevent
Poor sensor reliability ruins APC faster than almost anything else. A biased pressure transmitter, fouled temperature element, sticky control valve, or drifting flowmeter feeds bad information into a model that assumes the measurements are real.
That creates a classic garbage in, garbage out problem. The APC may chase a false deviation, push another variable unnecessarily, and create a plant upset that operators correctly interpret as “the controller messing up.” In reality, the field device failed first.
Maintenance can prevent that by treating APC-critical devices as a protected class. They should be explicitly identified in calibration planning, bad actor review, and predictive work scopes.
A useful reliability checklist looks like this:
- Instrument criticality: Mark which transmitters, analyzers, valves, and positioners are model-critical.
- Failure mode review: Include sensor drift, impulse line blockage, actuator hysteresis, and communication loss.
- Condition checks: Use calibration records, valve signatures, and loop performance review to find hidden degradation.
- Spare strategy: Hold practical spares for high-impact devices that can disable APC supervision.
Some plants also use a specialist support model. Forge Reliability provides reliability consulting, condition monitoring, and maintenance program support that can help plants tie APC-critical hardware into broader predictive and asset management routines. That matters when the controller depends on mechanical and instrumentation health more than on software features.
APC reliability starts in the field. If the instruments can't be trusted, the model shouldn't be trusted either.
How to keep operators from turning it off
Operator resistance is usually rational. The controller may have arrived with too little explanation, too many unexplained moves, or poor visibility into what it's trying to protect. No experienced board operator wants to be trapped between a software recommendation and an upset process.
Trust improves when the interface answers four questions clearly:
| Operator question | What the APC display should show |
|---|---|
| What is it trying to do? | Active objectives and controlled variables |
| What is stopping it? | Current active constraints and limits |
| Why did it move that valve or setpoint? | Contribution or cause view tied to process targets |
| How do I take over cleanly? | Simple manual handoff and fallback status |
Plants also get better results when operators participate in model review before commissioning. They know where analyzers stick, where valves hesitate, and which disturbances arrive every shift but never make it into project documents.
The worst rollout is the one that tells operations the controller is smarter than they are. It isn't. It is more consistent at handling multivariable interactions when the instrumentation and model are healthy. That's the honest position, and it earns support.
Measuring Performance KPIs and Calculating ROI
A reliability-focused APC business case shouldn't rely on vague claims like “better optimization” or “smarter control.” Budget holders need a performance framework that connects process stability to money, maintenance burden, and asset risk.
KPIs that matter to reliability and operations
The best APC metrics are the ones the plant can already measure with confidence. For most facilities, that means focusing on variability, production consistency, energy intensity, quality margin, and equipment stress indicators.
A practical KPI set includes:
- Process variability: Track the spread of key controlled variables, not just their average. A stable reactor temperature, column pressure, or dryer outlet condition matters because it reduces corrective movement and off-spec risk.
- Throughput consistency: Look at how often the unit can hold its intended rate without repeated operator intervention or temporary cutback.
- Specific energy use: Measure energy consumed per unit of product. APC often improves this by reducing hunting and by keeping the process closer to its efficient window.
- Quality giveaway: This is the amount of overcontrol used to stay safely inside spec. If APC holds the process tighter, the plant may reduce unnecessary margin.
- Asset stress proxies: Count valve travel, recycle events, alarm frequency, controller time in manual, or repeated operation near mechanical limits.
For a natural gas processing example, a plant might focus on product recovery stability, residue gas quality compliance, compressor loading smoothness, and energy use in refrigeration or compression sections. The goal isn't to produce one perfect metric. The goal is to create a short list that reflects how the unit makes money and how it wears out.
If a KPI can't change a maintenance, operating, or capital decision, it's a dashboard decoration.
A practical ROI framework
ROI for advanced process control software should include both benefits and support cost. Too many proposals count only the upside and ignore model maintenance, training refresh, instrument work, and engineering time after startup.
A simple framework works better than a complicated one:
| ROI component | Typical question |
|---|---|
| Production benefit | Did the unit sustain a higher or more consistent rate? |
| Energy benefit | Did the process consume less steam, fuel, or power for the same output? |
| Quality benefit | Did rework, giveaway, or off-spec exposure decline? |
| Reliability benefit | Did the unit see fewer stress-driven interventions, trips, or maintenance calls? |
| Ownership cost | What does the plant spend to maintain models, instruments, and support capability? |
Annualized value should be estimated from observed plant changes over a meaningful operating period, then compared against the total ownership cost of the APC application. Plants don't need invented precision here. They need traceable logic. If valve activity dropped, alarm burden eased, and the unit held target conditions with fewer disturbances, those operational changes can be tied back to labor, energy, quality, and equipment consequences.
Reliability teams should also avoid a common mistake. They shouldn't claim the full value of every improvement as “APC ROI” if maintenance repairs, retuning of base loops, or instrument replacements created part of the result. Shared credit is more believable and usually leads to stronger long-term support.
For teams building internal justification, a grounded set of reliability metrics such as MTBF, MTTR, and OEE helps frame APC as an asset performance investment, not just a controls project.
Integrating APC with Your Asset Reliability Program
The strongest APC programs don't live inside a controls silo. They feed the reliability program with high-resolution operational insight that maintenance can use. When that connection is made, APC stops being just an optimizer and becomes another sensing layer for asset health.
Using APC as a condition monitoring layer
A good APC model knows how the process should respond when assets are healthy. That means deviation from expected controller behavior can reveal early equipment problems.
A pumping system is a simple example. If the APC layer needs progressively higher discharge pressure targets or more valve opening to hold the same downstream flow, something in the physical system may be changing. The pump could be wearing internally. A strainer or line may be fouling. A control valve may be sticking and forcing compensation elsewhere. None of those problems starts as a maintenance work order. They start as a subtle change in process response.
That's why plants should connect APC observations to the same disciplines used for broader digital monitoring. Teams already working on optimizing infrastructure with monitoring tools understand the principle well. Stable systems are easier to diagnose, and deviations from expected behavior are often the earliest warning.
Connecting APC data to FMEA and RCFA
APC also belongs in Failure Mode and Effects Analysis, or FMEA, and in Root Cause Failure Analysis, or RCFA. If a controller depends on a certain analyzer, transmitter, or valve response characteristic, then failure of that component isn't just an instrument issue. It's a process control failure mode with production and equipment consequences.
RCFA benefits too. After a process upset, APC historical data often shows the sequence of moves, active constraints, and prediction errors with more context than operators can reconstruct from memory. That makes it easier to distinguish between a bad model, a bad sensor, a bad actor valve, and an actual process disturbance.
Plants that treat APC as part of asset lifecycle management planning usually make better replacement, spares, and maintenance interval decisions. They can see which field devices are essential to stable operation and which assets create recurring model stress when they degrade.
Advanced process control software creates the most value when operations, maintenance, reliability, and controls all own a piece of its performance. That's how it improves uptime, protects asset health, and avoids becoming another abandoned application in the control room.
A free reliability assessment from Forge Reliability can help identify where APC, instrumentation health, and maintenance strategy are helping the plant, and where they're creating hidden risk. For facilities dealing with process instability, recurring control-related equipment stress, or underperforming optimization projects, that assessment gives operations and reliability teams a practical starting point.


